字节跳动旗下火山引擎,发布豆包大模型1.6、视频生成模型Seedance 1.0 pro、豆包·语音播客模型等一系列新模型,并升级了Agent开发平台等AI云原生服务。
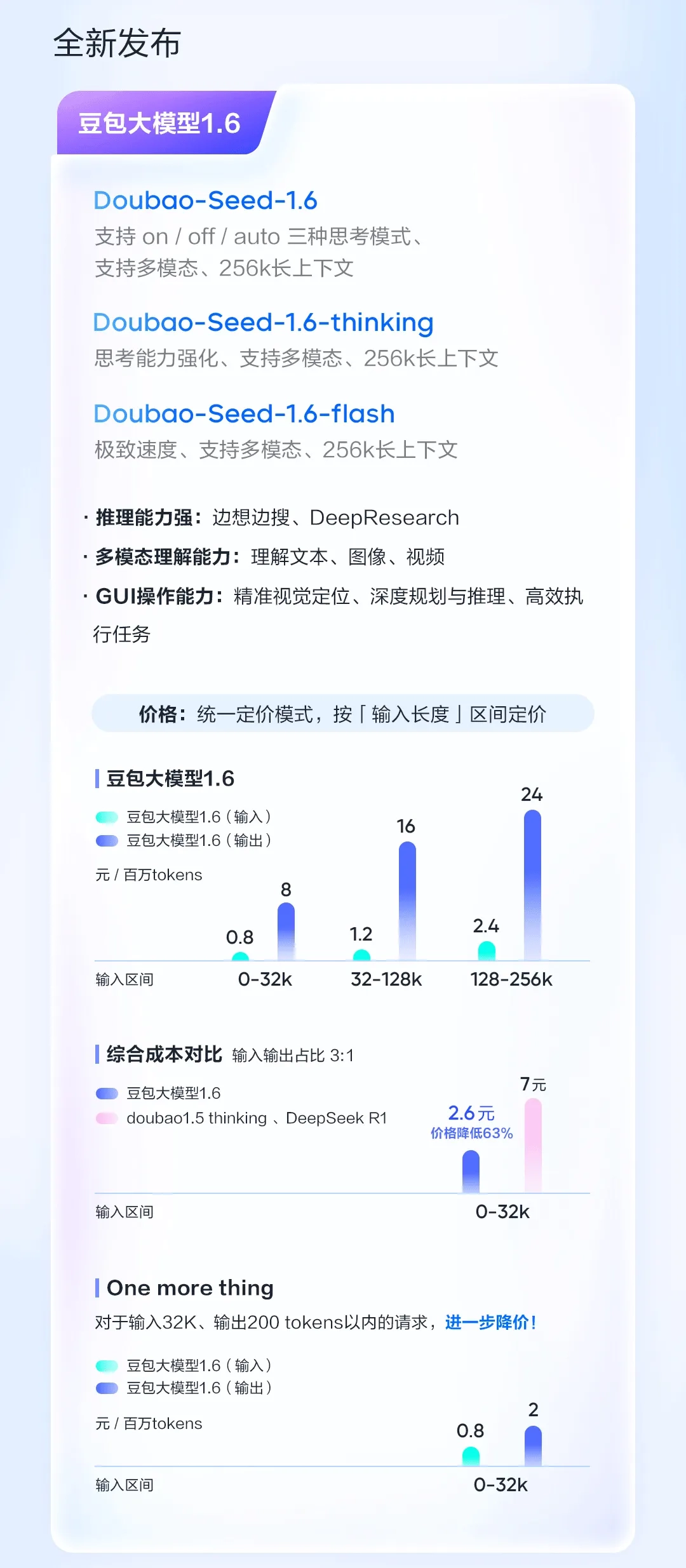
豆包大模型1.6
豆包1.6-thinking模型在多个权威测评集上达到全球第一梯队水平:GPQA Diamond测试成绩达到81.5分,是目前最好的推理模型之一;数学测评AIME25成绩达到86.3分,相比豆包1.5深度思考模型大幅提升12.3分。
豆包大模型1.6系列均支持深度思考、多模态理解、256k长上下文、图形界面操作等能力,能够更好地支持复杂Agent的构建,促进AI生产力的提升。
多模态理解能力提升
多模态理解的核心是“让模型像人一样理解世界”。豆包大模型1.6全系列均原生支持多模态思考能力,让模型可以理解和处理真实世界的问题。
该能力支持了豆包 APP 最新的实时视频通话功能,在企业端可广泛应用于电商商品审核、自动驾驶标注、安全巡检等场景。
目前,豆包大模型1.6系列已在火山引擎上线,企业和开发者可调用API体验。
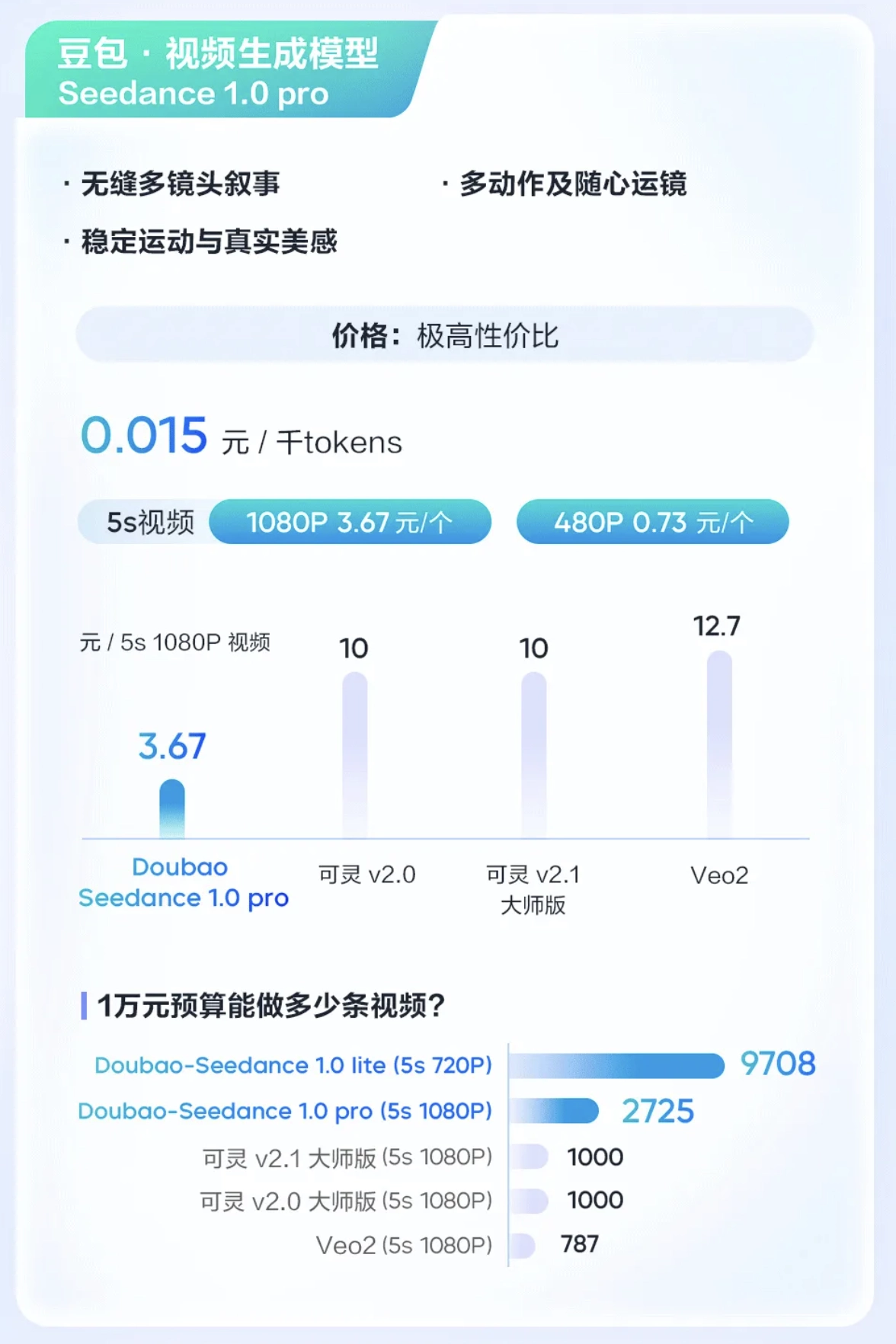
豆包·视频生成模型Seedance 1.0 pro
Seedance 1.0 pro支持文字与图片输入,可生成多镜头无缝切换的1080p高品质视频,主体运动稳定性与画面自然度较高。在国际知名评测榜单Artificial Analysis上,Seedance 1.0 pro在文生视频、图生视频两个任务的表现均排名首位。
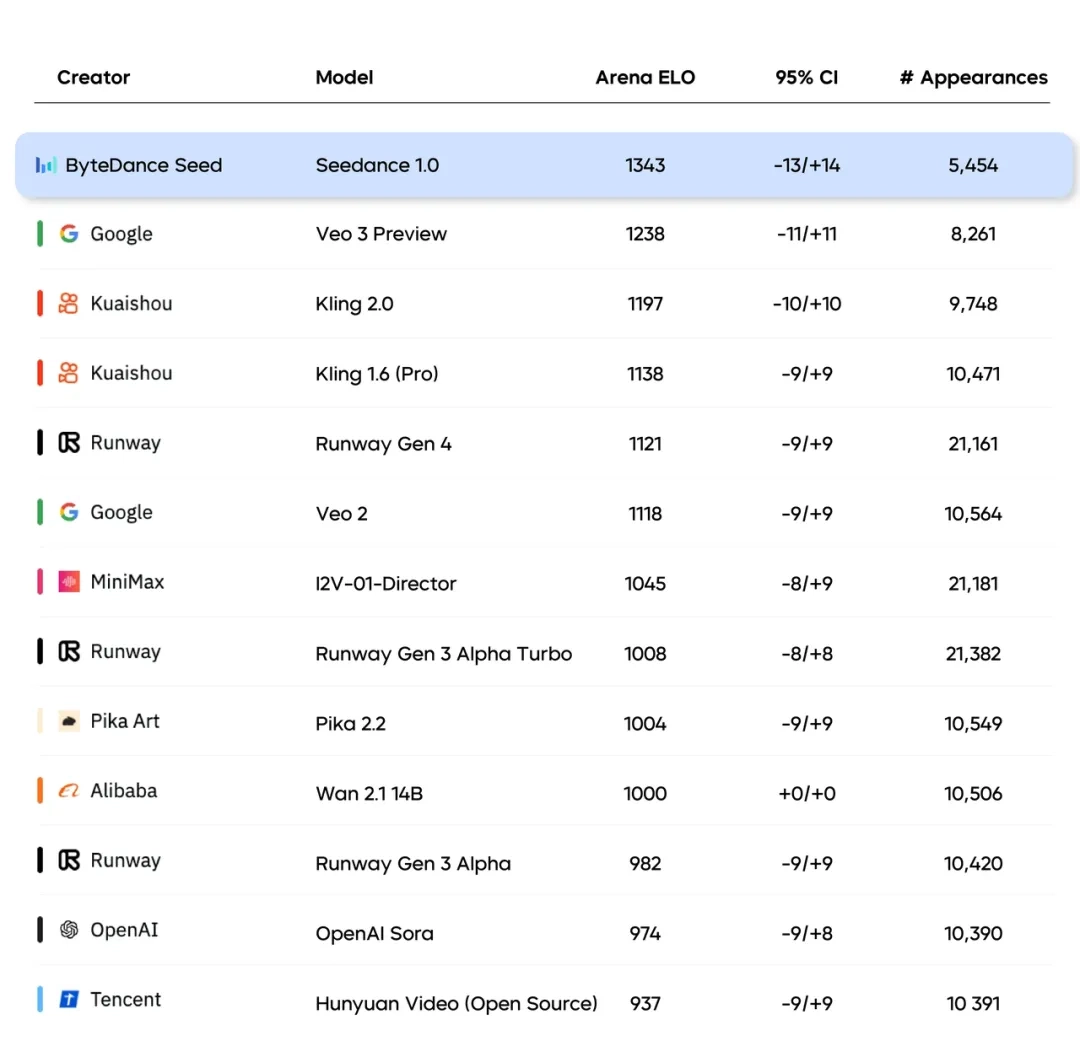
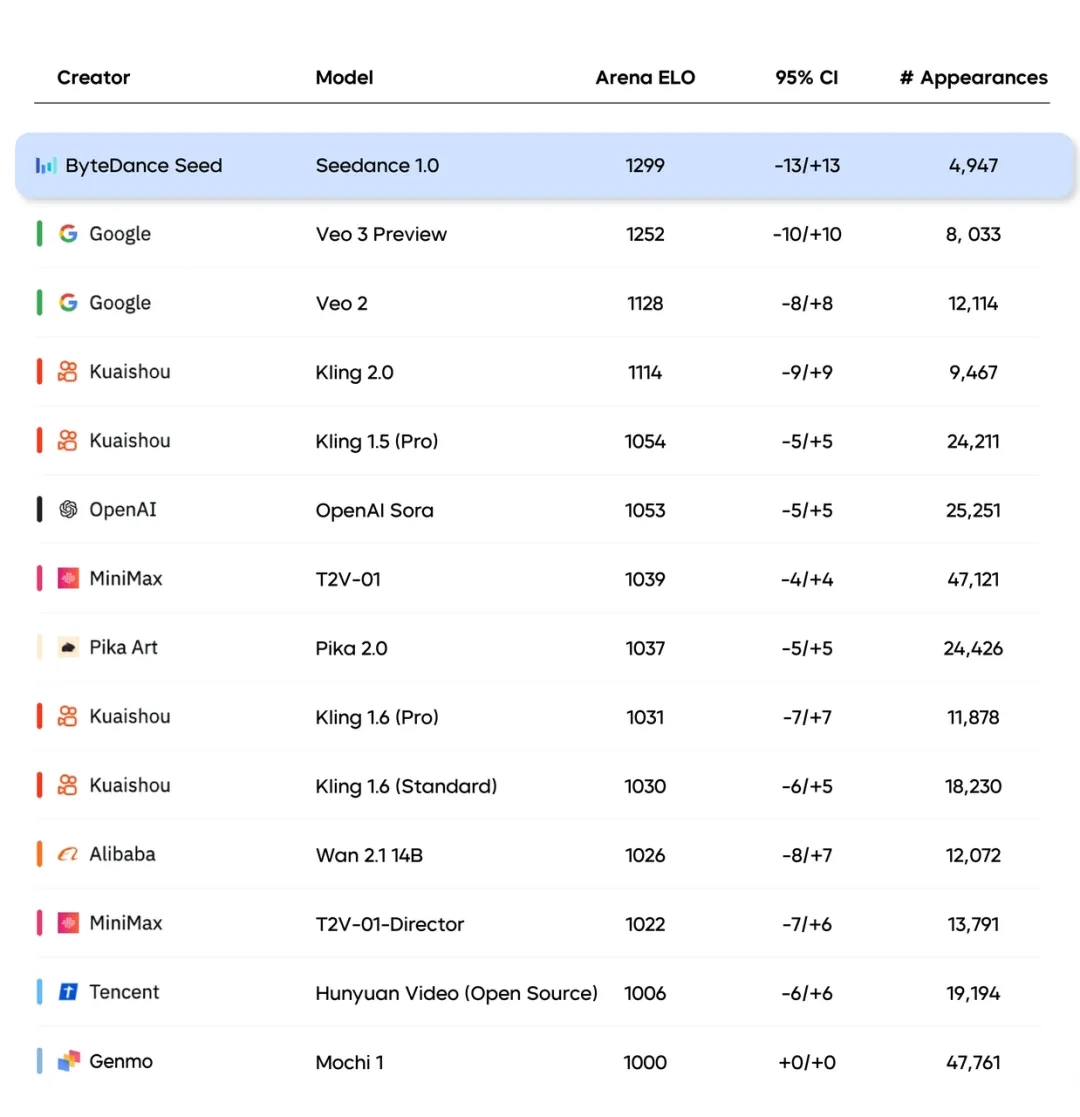
- 输入类型:支持文本、图像、视频、音频
- 输出类型:生成视频(支持 Text-to-Video 与 Image-to-Video)
- 分辨率支持:480p、1080p
- 帧率:24fps
- 时长:5秒或10秒
核心技术亮点
🧩 多镜头叙事能力
- 原生支持连续“多镜头视频”生成
- 通过多模态交织的位置编码与统一建模结构;
- 实现时空切换中视觉一致性、情节连贯性。
🕺 高度真实的运动表现
- 基于自研的精细数据集和奖励机制;
- 使用 RLHF(Reinforcement Learning from Human Feedback)技术优化生成质量;
- 实现从微表情到动作场景的高保真模拟。
🎯 指令遵循能力
- 精准解析多主体、多动作组合;
- 高度匹配文本描述,控制“运镜”行为;
- 支持复杂叙事结构的视频任务。
🎨 多风格视频输出
支持以下风格控制词(prompt风格):
- 油画、毛毡、水彩、3D卡通、水墨、粘土、像素、蒸汽朋克、素描等。
计费与限流
- 价格:15元 / 百万token(文生与图生同价)
- 并发限制:每主账号最多10个并发请求
限流阈值:每分钟最多600个创建请求(RPM)
关于Seedance 1.0 pro的更多技术细节,详见项目主页(可查看完整技术报告)
豆包·语音播客模型
全新发布的豆包·语音播客模型源于端到端实时语音的进一步拓展,能够实现从文本创作到双人对话式播客作品的秒级生成,同时具备互相附和、插话、犹豫等自然的播客元素生成,达到了媲美真人的生成效果。

你可以在扣子空间 体验语音播客相关功能。同时,豆包产品已启动小流量测试,近期将全量上线播客模型。
