声明:本文来自于微信公众号 新智元,授权Soraor转载发布。
对物理的直观理解是人类认知的基础:期望物体的行为,具有可预测性,也就是说,物体不会突然出现或消失,穿过障碍物,或随意改变形状或颜色。
这种对物理的直观理解,还在更多物种中得到证实,包括猴子、鲸鱼、乌鸦等。
相关研究人员猜测:人类天生或婴幼儿时期就具备一套进化形成的、古老的系统,专门用于表示和推理世界的基本属性,比如物体、空间、数字、几何形状等。
Meta新研究证明,没有任何先验知识,自监督视频模型V-JEPA,也能够理解直观物理学!
换句话说,通过观察,V-JEPA觉醒了物理直觉,和人类一样不需要硬编码,天生如此!
V-JEPA不是去生成像素级的精准预测,而是在抽象的表示空间里进行预测。
这种方式更接近LeCun所认为的人类大脑处理信息的模式。
他甚至回归X平台,转发论文通讯作者的post,宣布:「新方法学会了直观物理」。
这次的主要发现如下:
V-JEPA能够准确且一致地分辨出,符合物理定律的视频和违反物理定律的视频,远超多模态LLM和像素空间中的视频预测方法。
虽然在实验中观察到改变模型的任一组件,都会影响性能,但所有V-JEPA模型都取得了明显高于随机水平的表现。

论文链接:https://arxiv.org/abs/2502.11831
V-JEPA被网友Abhivedra Singh评价为:AI的关键飞跃!
AI直观物理: 第三条路
在语言、编码或数学等高级认知任务上,现在高级的AI系统通常超越人类的表现。但矛盾的是,它们难以理解直观物理,没有物理直觉。
这就是莫拉维克悖论(Moravec's paradox),即对生物体来说微不足道的任务,对人工系统来说可能非常困难,反之亦然。
之前,有两类研究致力于提高AI模型对直观物理的理解:结构化模型和基于像素的生成模型:
结构化模型:利用手工编码的物体及在3D空间中关系的抽象表示,从而产生强大的心理「游戏引擎」,能够捕捉人类的物理直觉。这是核心知识假设的一种可能的计算实现。
基于像素的生成模型则持截然相反的观点,否认需要任何硬编码的抽象表示。相反,它们提出了通用的学习机制,即基于过去的感官输入(例如图像)来重建未来的感官输入。
新研究则探讨了位于这两种对立观点之间、第三类模型:联合嵌入预测架构(Joint Embedding Predictive Architectures,JEPAs)。
新研究专注于视频领域,特别是视频联合嵌入预测架构V-JEPA。V-JEPA在下列文章中首次提出。

论文链接:https://arxiv.org/abs/2404.08471
基于心理学的预期违背理论,这次直接探测直观物理理解,而不需要任何特定任务的训练或调整。
研究人员通过促使模型去想象未来的视频表示,并将其预测与实际观察到的未来视频进行比较,获得了定量的惊讶度,用来检测违背的直观物理概念。
测量直观物理理解
预期违背起源于发展心理学。
受试者(通常是婴儿)会看到两个相似的视觉场景,其中一个包含物理上的不可能事件。
然后通过各种生理测量方法,获得他们对每个场景的「惊讶」反应,并用于确定受试者是否发生了概念违背。
这种范式已被扩展到评估AI系统的物理理解能力。
与婴儿实验类似,向模型展示成对的场景,其中除了违反特定直观物理概念的单个方面或事件,其他所有方面(物体的属性、物体的数量、遮挡物等)在两个场景中都保持相同。
模型对不可能场景表现出更高的惊讶反应,反映了对被违背的概念的正确理解。
理解直观物理的视频预测
V-JEPA架构的主要开发目的,是提高模型适应高级下游任务的能力,直接从输入中获取,而不需要一连串的中间表征。
研究团队验证了一个假设,即这种架构之所以能成功完成高级任务,是因为它学会了一种表征方式,这种方式能隐含地捕捉到世界中物体的结构和动态,而无需直接表征它们。
如下图所示,V-JEPA是通过两个神经网络实现的:
编码器:从视频中提取表示;
预测器:预测视频中人为遮蔽部分的表示,比如随机遮蔽的时空块、随机像素或未来帧。
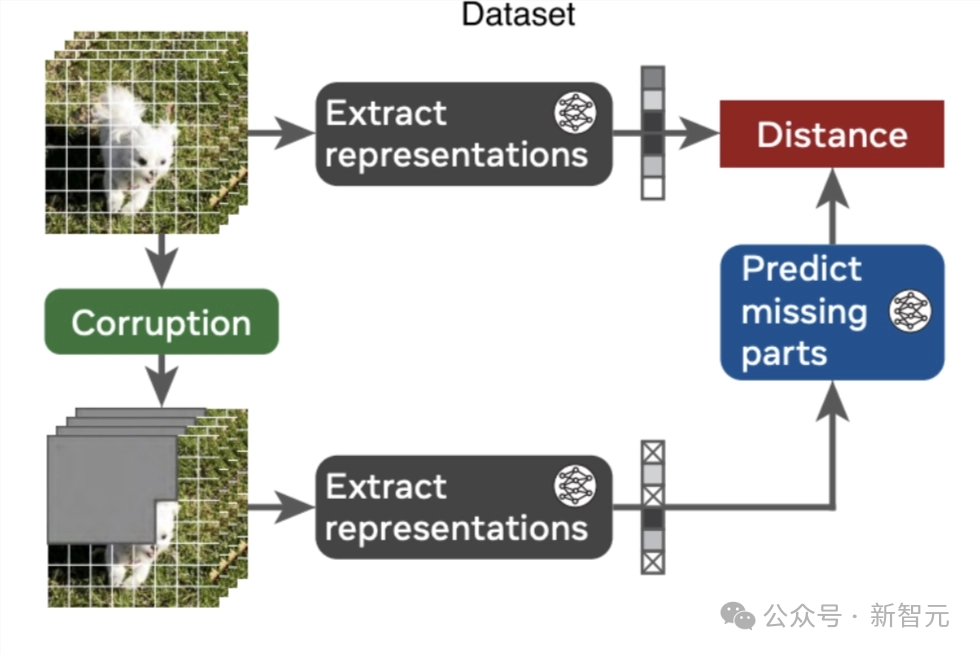
训练从视频和损坏版开始,首先提取表征。
然后,从损坏视频的表征,来预测原始视频的表征。通过编码器和预测器的联合训练,编码器能够学习到编码可预测信息的抽象表示,并舍弃低层次(通常较少语义)的特征。
经过训练之后,在学习到的表征空间中,V-JEPA可以「修复」自然视频。
在自监督训练之后,可以直接使用编码器和预测器网络,无需任何额外的适应,来探测模型对世界理解的程度。
具体来说,通过遍历视频流,模型会对观测到的像素进行编码,并随后预测视频中后续帧的表示,如图1.C所示:
从训练好的V-JEPA 中,基于M个过去的帧,预测N个未来帧的表征。
然后比较预测与观察到的事件表征,来计算惊讶度指标。
最后,使用惊讶度指标,决定两个视频中的哪一个违反了物理学定律。
通过记录每个时间步的预测误差——即预测的视频表示与实际编码的视频表示之间的距离——获得了一个在时间上对齐的、量化模型在视频中惊奇程度的度量。
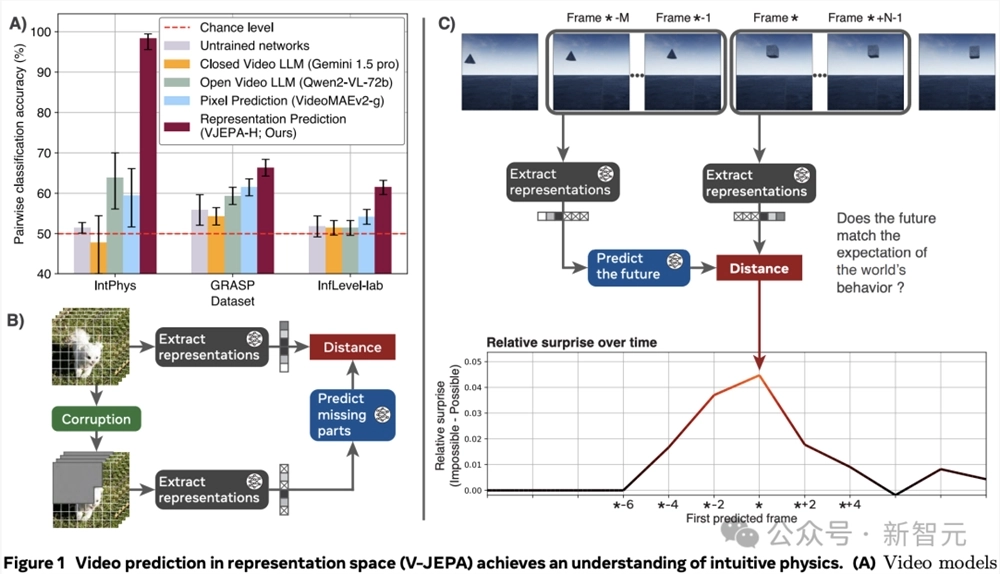
图1:在表征空间中进行视频预测(V-JEPA)实现对直观物理的理解。
改变模型用来预测未来的过去视频帧(上下文)的数量,可以控制记忆;通变视频的帧率,可以控制运动的精细度。
研究团队评估了三个数据集上的直观物理理解:IntPhys的dev数据集、GRASP和 InfLevel-lab。
这些基准测试的组合提供了视觉质量(合成/照片级真实感)、场景多样性以及直观物理属性的多样性。具体而言,这些数据集的组合能够探究对以下概念的理解:物体永恒性、连续性、形状和颜色恒常性、重力、支持力、坚固性、惯性以及碰撞。
将V-JEPA与其他视频模型进行比较,目的是研究视频预测目标及表征空间对直观物理理解的重要性。
此次考虑了两类其他模型:视频预测模型和多模态大型语言模型 (MLLM)。
视频预测模型:直接在像素空间中进行预测,预训练方法与V-JEPA在预测目标上相似,但通常学习到的表征空间的语义性较差 ,因此通常只有在针对特定任务微调后才具有实际应用。
多模态大语言模型:主要用于预测文本,并且在训练过程中仅在事后与视频数据结合,因此缺乏视频预测的目标。
作为前者的代表性方法,作者评估VideoMAEv2。
尽管该模型使用了不同的预测目标和预训练数据,但其预测空间的设置使得与V-JEPA进行比较成为可能。鉴于其预测性质,VideoMAEv2可像V-JEPA一样,通过预测未来并通过预测误差衡量惊讶程度来进行评估。
作为后者的典型的示例方法,作者研究了Qwen2-VL-7B和Gemini1.5Pro。
就参数数量和训练数据量而言,这些模型都比V-JEPA大得多,并且它们主要从文本数据中学习。多模态大型语言模型,将视频和可能的文本提示作为输入,并学习生成相应的文本输出。
由于MLLM只有文本输出,因此无法使用基于定量惊讶度量去评估这些模型。
所以给模型一对视频,询问哪个视频在物理上是不可能的, 如下所示。


对于每个方法,作者评估了原始研究中提出的旗舰模型。
进一步将全部模型与未训练的神经网络进行比较,以测试直觉物理理解的可学习性。对于每个属性和模型,选择的上下文大小要最大化性能,以便让模型能够适应不同的评估设置。
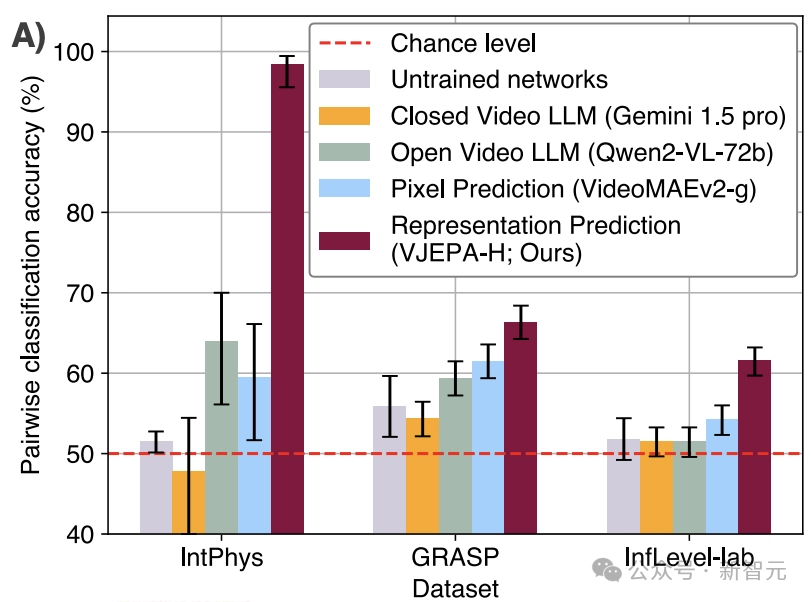
在3个直观物理数据集IntPhys、GRASP和InfLevel上,使用违反预期范式,评估视频模型。V-JEPA对不合理的视频明显更加「惊讶」,是唯一一个在所有数据集上表现出显著优于未训练网络的性能的方法,在IntPhys、GRASP和InfLevel-lab数据集上分别达到了98%、66%和62%的平均准确率。
下图总结了各方法在不同数据集上的对比分类性能(即,在一对视频中检测哪个是不可能的)。
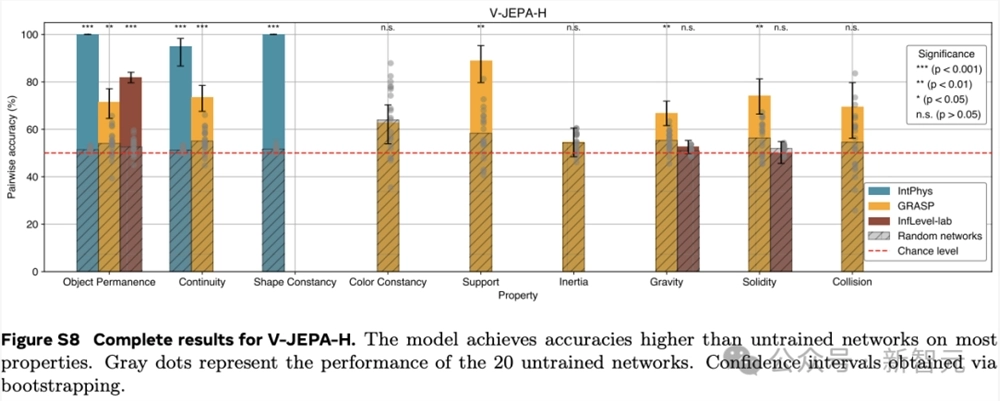
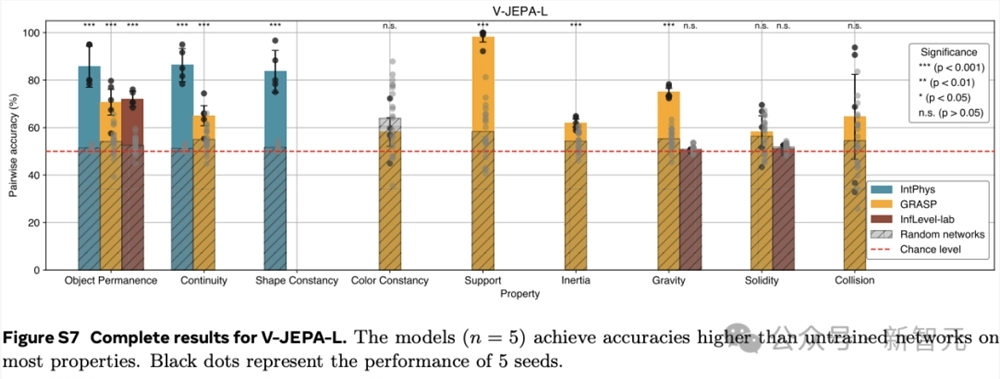
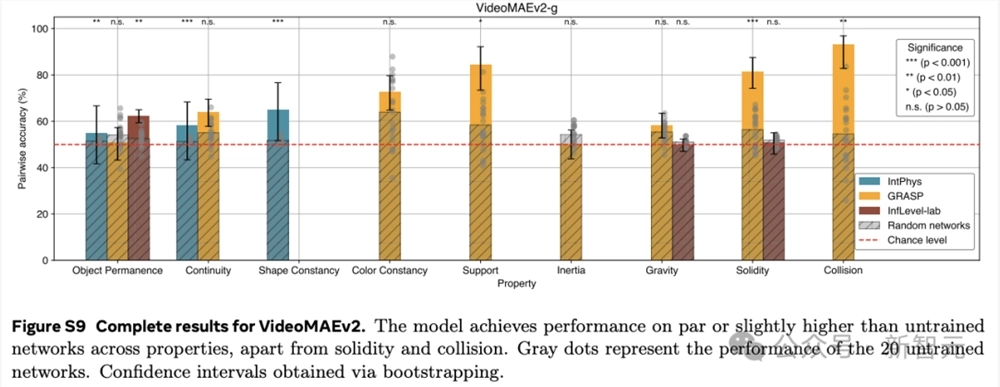
更详细的结果,参考下图。
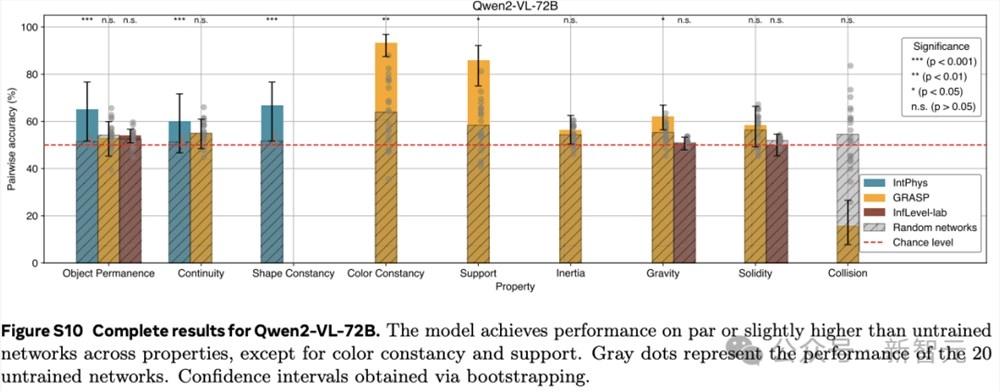
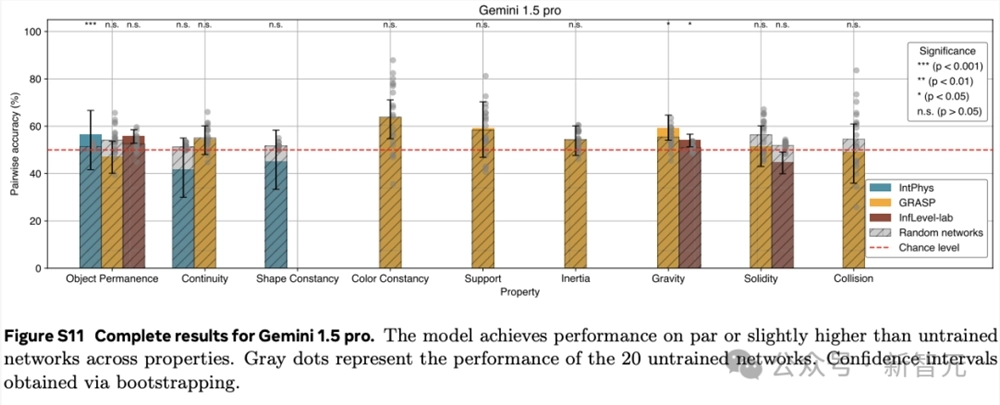
这些结果表明,在学习到的表示空间中,只做预测就足以发展出对直觉物理的理解。这个过程没有依赖任何预定义的抽象概念,也没有在预训练或方法开发过程中使用基准知识。
而像素预测和多模态LLMs的低性能验证了之前的发现。
这些比较进一步突显了V-JEPA相对于现有的VideoMAEv2、Gemini1.5pro和Qwen2-VL-72B模型的优势。
然而,这些结果并不意味着LLMs或像素预测模型无法实现直觉物理理解,而只是表明这一看似简单的任务,对于前沿模型来说仍然困难。
V-JEPA深度剖析
为了解V-JEPA对不同直观物理属性的理解能力,研究者对其在各个数据集上的逐属性性能进行了深入分析。
使用基于视觉Transformer-Large(ViT-L)架构的V-JEPA模型,在HowTo100M数据集上进行训练。
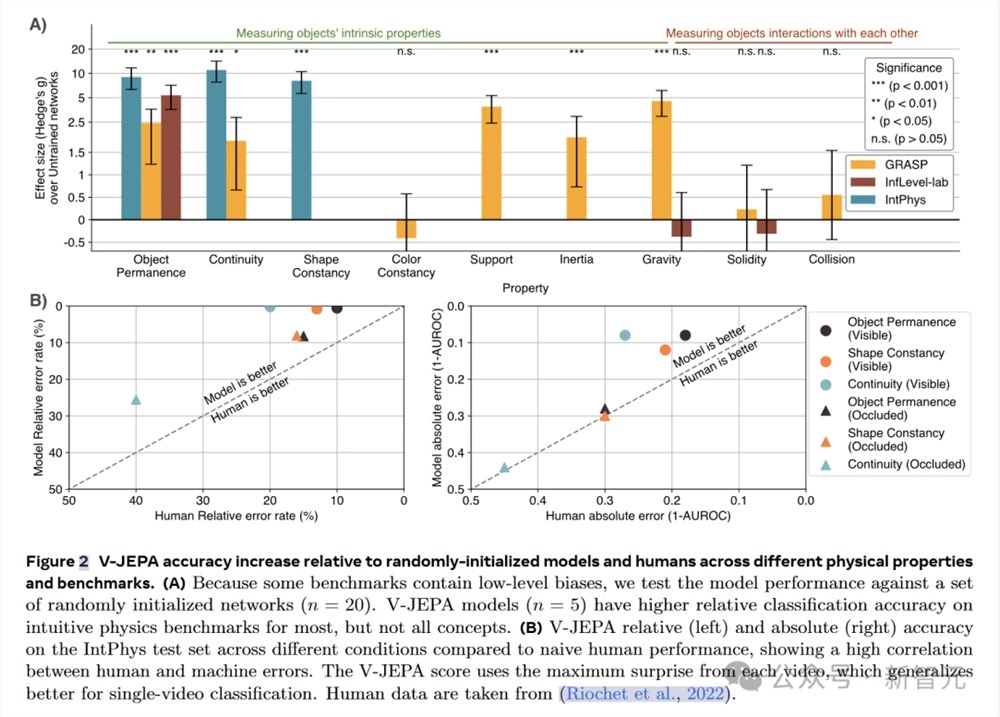
在IntPhys数据集上,V-JEPA在物体持久性、连续性和形状恒定性等属性上的表现远超未训练的网络。
以物体持久性为例,V-JEPA的准确率达到了M=85.7,SD=7.6,而未训练网络的准确率仅为M=51.4,SD=1.0(t (4.0)=-8.9,p=4.19×10⁻⁴),效应量g=9.0(95%置信区间 [6.3,11.7])差异非常显著。
在GRASP数据集上,V-JEPA在物体持久性、连续性、支撑性、重力和惯性等属性上的准确率同样显著高于未训练网络。然而,在颜色恒常性、坚固性或碰撞等属性方面,并未观察到显著的提升。
在InfLevel数据集上,V-JEPA在物体持久性上的准确率有显著提高,但在重力或坚固性方面则没有明显的优势。
综合来看,V-JEPA在与场景内容相关的属性上表现出色,但在涉及需要理解上下文事件的类别或涉及精确物体交互建模,还存在一定的困难。
研究者推测,这些局限性主要来源于模型的帧率限制。
尽管如此,V-JEPA能从原始感知信号中学习必要的抽象概念,而无需依赖强先验信息,展现出对直观物理学的理解能力。这表明深度学习系统理解直观物理概念并不一定需要核心知识。
研究人员还将V-JEPA与人类表现进行了对比,V-JEPA在所有直观物理属性上均达到或超过人类的表现。
在单个视频分类任务中,使用视频中的最大惊讶度而非平均值,能够使V-JEPA的性能得到进一步提升。
对于物理违反事件发生在遮挡物后面的视频,V-JEPA和人类的表现都会下降。在遮挡场景下,两者的表现具有较高的相关性。
直观物理学理解的关键
为了深入挖掘V-JEPA中直观物理理解出现的内在机制,研究者进行了详细的消融实验,考察训练数据、模型大小和预训练预测任务这三个关键因素对直观物理理解的影响。
V-JEPA在训练时采用的是块掩蔽任务,即对视频的整个持续时间内的一个大空间块进行掩蔽,而在推理时则运用因果预测。
为了探究预训练任务对直观物理理解的具体影响,引入了两种不同的替代方案:因果块掩蔽和随机掩蔽。
实验结果显示,预测任务对直观物理理解的影响相对较小。尽管随机掩蔽在视频分类任务上会导致明显的性能下降,但在IntPhys数据集上,其平均下降幅度仅约5分。
有趣的是,因果块掩蔽虽然在测试时与模型的预测设置更为接近,但实际表现却不如非因果块掩蔽。
随机掩蔽能够取得一定的有效性能,这表明在抽象表征空间中进行预测才是关键所在,而不一定非要依赖特定的预训练目标。
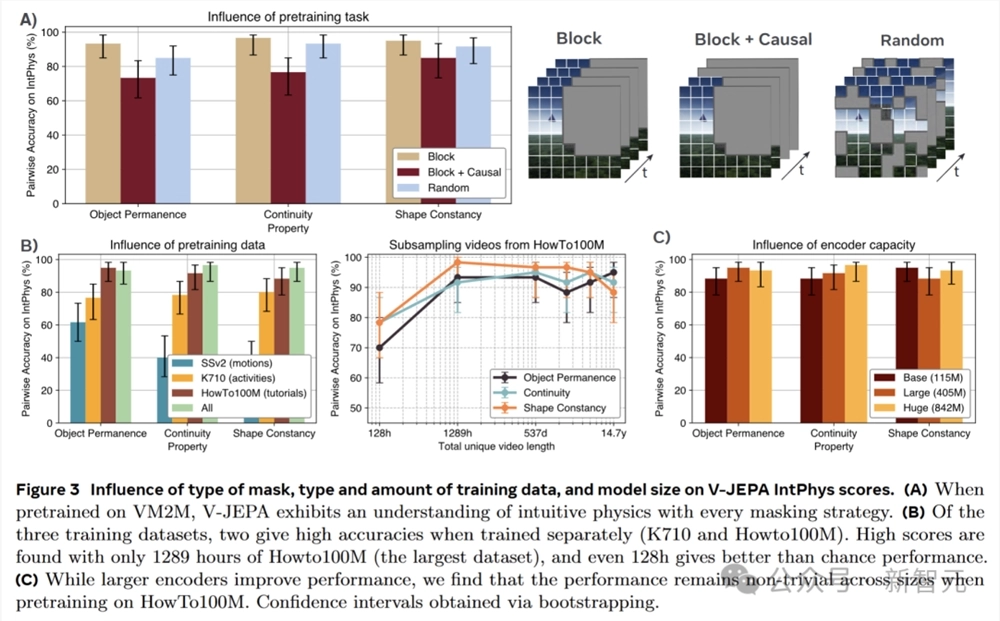
V-JEPA之前是在Kinetics710、Something-Something-v2和HowTo100M三个数据集的混合(VideoMix2M)上进行训练的。
为了研究预训练数据对直观物理性能的影响,分别使用这三个组件数据集重新训练V-JEPA-L模型,并对HowTo100M进行子采样,以探究数据集大小对模型性能的影响。
研究发现,数据源对模型性能有着显著的影响。
仅使用基于运动理解的视频(SSv2)进行训练时,模型的性能接近随机水平;侧重于动作的数据(K710)能使模型获得高于随机水平的直观物理理解能力;而教程视频(HowTo)在单个组件数据集中展现出了最佳的性能。
通过对HowTo100M进行子采样,进一步发现,即使使用仅占该数据集0.1%、仅代表128小时独特视频的小规模数据集,模型依然能有效地区分对直观物理概念的违反情况,且在所有考虑的属性上保持超过70%的成对准确率。
在深度学习领域,通常认为更大的模型具有更好的性能。
为了验证这一观点在V-JEPA模型中的适用性,团队研究了V-JEPA在使用不同大小编码器时的表现。
实验结果表明,一般情况下,更大的模型确实表现更优。然而,一个参数仅有115M的小模型,仍然能够达到超过85%的准确率。
这充分展示了V-JEPA模型对直观物理理解的稳健性,即使是较小的模型也能实现对直观物理的有效理解。
参考资料:
https://arxiv.org/abs/2502.11831
https://x.com/ylecun/status/1893390416185008194