TheoremExplainAgent (TEA) 是由 TIGER AI Lab(滑铁卢大学文本与图像生成研究实验室)开发的一个多模态 AI 系统。
它基于双智能体架构,利用大语言模型(LLM)的推理能力,结合动画生成和语音合成技术,模仿人类视频制作流程,利用代理规划和动画生成技术,自动化创建长时间(超过5分钟)的定理解释视频,可以将复杂的学术概念转化为易于理解的视频动画解释。
TheoremExplainAgent (TEA) 通过结合动画、结构化推导和画外音叙述,以直观且教育性的方式解释定理的概念、证明和应用。适用于数学、物理、化学和计算机科学等多个STEM学科。
解决了什么问题
TheoremExplainAgent 主要解决了以下三大问题:
- 多模态解释的生成
• 问题:现有的大型语言模型在文本推理方面表现良好,但难以生成连贯且具有教育意义的视觉解释,尤其是长时间的结构化视频内容。定理理解往往需要可视化来展示抽象概念,而当前AI系统在这方面能力有限。
• 解决方案:TheoremExplainAgent 通过代理规划和Manim动画生成技术,自动创建多模态的教育性视频,提供了一种全新的解决方案。 - 定理理解的深度
• 问题:传统的定理评估方法(如多项选择题)无法充分反映AI对定理的深层理解,模型可能仅依赖表面线索而非真正掌握概念。
• 解决方案:通过生成详细的视频解释,TheoremExplainAgent 要求AI系统显式展示定理的结构和推导过程,从而揭示其深层推理能力,提升理解的透明度和全面性。 - 评估框架的缺乏
• 问题:目前缺乏针对AI生成多模态定理解释的标准化评估方法。
• 解决方案:作者开发了 TheoremExplainBench,一个包含240个定理的基准数据集和5个自动评估指标,用于系统性地评估AI生成视频的质量和教育效果。
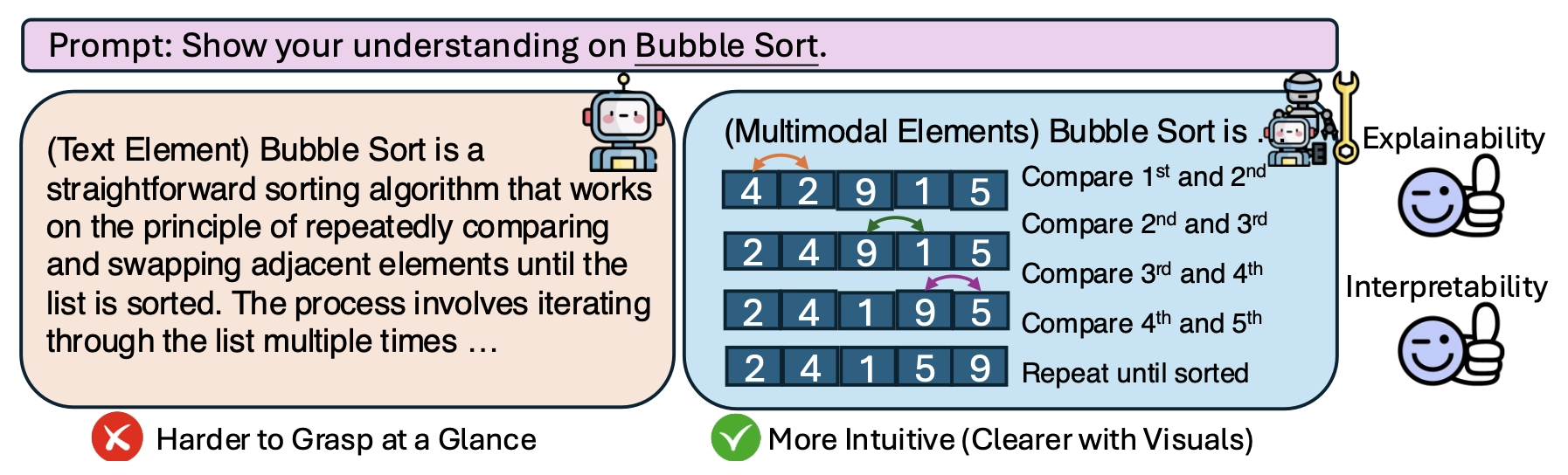
我们只有在掌握事物的原因后,才能对其有真正的认识(亚里士多德,1901 年)。一个强大的推理模型不仅应能得出正确的结论,还应能有效地传达这些结论。可视化通过将抽象概念具体化并揭示隐藏的关系,增强了人类的直觉。此外,视觉解释比文字更清晰地揭示推理错误,使得诊断模型的错误变得更加容易。
TheoremExplainAgent(TEA)的主要功能特点
1. 多模态定理解释
TEA 采用 文本、语音和动画结合 的方式,生成超过 5 分钟 的 详细定理讲解视频,相比纯文本解释具有更高的直观性和可理解性。
主要特点:
- 文本 + 视觉 + 语音 结合,比传统 LLM 仅使用文本解释更具教育价值。
- 基于 Manim(Python 动画库) 生成高质量数学动画,直观展示推导过程。
- 自动化视频生成,减少人工干预,提升效率。
2. 智能代理架构
TEA 采用 双代理架构,实现高效的视频生成:
规划代理(Planner Agent)
- 分析定理,设计逻辑清晰的讲解结构和叙述内容。
- 生成 长篇故事脚本,确保教学内容连贯流畅。
代码生成代理(Coding Agent)
- 将规划代理的讲解脚本转换为 Python 代码。
- 使用 Manim 创建动画,结合语音旁白,生成完整视频。
优势:
✅ 自动化生成视频,不需要人工编写动画代码。
✅ 确保内容逻辑性,避免传统 LLM 生成的片段式、不连贯解释。
3. TheoremExplainBench(TEB)基准测试
为了评估 TEA 生成的视频质量,研究团队提出了 TheoremExplainBench(TEB):
- 涵盖 240 个数学、物理、计算机科学、化学等领域的定理
基于 5 项自动评估指标 确保讲解质量:
- 准确性 & 深度(Accuracy & Depth):内容是否正确、推理是否深入。
- 视觉相关性(Visual Relevance):动画是否符合定理内容。
- 逻辑流畅性(Logical Flow):讲解是否连贯、逻辑是否清晰。
- 视觉元素布局(Element Layout):视觉元素的排列是否清晰易懂。
- 视觉一致性(Visual Consistency):风格、颜色、结构是否统一。
优势:
✅ 确保 AI 解释质量,让讲解更具可读性和教育性。
✅ 通过视觉评估发现推理错误,比传统 LLM 仅使用文本解释更精准。
4. 高质量视频自动生成
TEA 生成的视频质量高,能够制作出与人类手工制作接近的教学级别视频。
示例: ✅ 高质量视频:
- 数学:积分替换法、理性根定理
- 物理:几何布朗运动
- 计算机科学:梯度下降
- 化学:凯尔达尔法
🚫 低质量视频(仍需改进):
- 数学:勾股定理
- 化学:米氏酶动力学
- 物理:电磁波谱
5. 视觉推理 & AI 解释增强
研究发现,视觉化解释比纯文本解释更具优势:
能够直接暴露 AI 计算或逻辑错误:
- 纯文本可能只显示“计算错误”。
- 视觉动画会直观地显示错误来源(如箭头方向错误、数学推导错误)。
- 增强 AI 透明度,便于研究人员和用户理解 AI 如何得出结论。
案例:
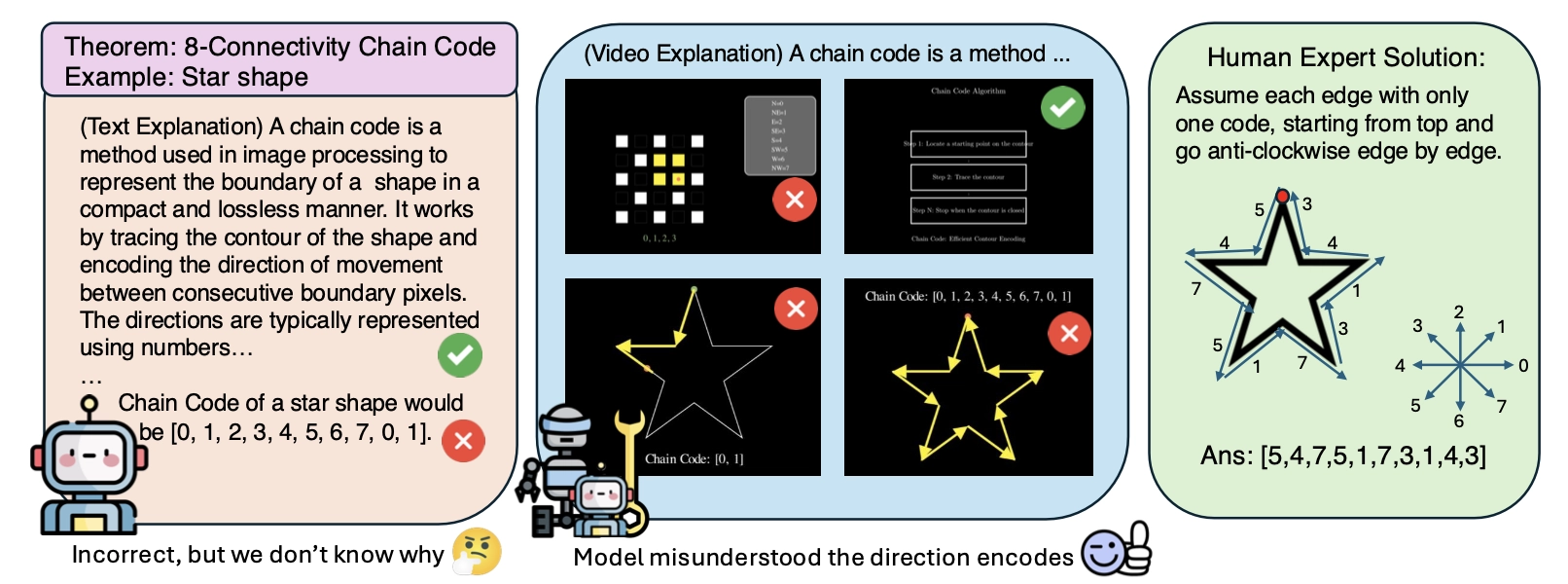
一个关键发现是,视觉解释显著改善了错误诊断,相比于基于文本的解释。虽然文本可以揭示错误的存在(如图 4 所示),但往往无法阐明错误发生的原因。
例如,文本解释可能指出链码定理的错误应用,但未能明确指出推理中的根本缺陷。相比之下,基于视频的解释能够直接暴露误解。错误的运动方向编码和错误放置的箭头直接揭示了对链编码过程的误解。这表明视觉解释不仅仅是对错误的确认;它们是强大的诊断工具,可以揭示根本原因,从而更有效地分析 AI 生成的输出。
6. 可定制化 & 低计算成本
TEA 适用于多种设备和环境,可在边缘计算和本地设备上高效运行。
- 低计算需求:相比 GPT-4o 或 Claude 3.5,TEA 使用小型模型(如 o3-mini),能够在 本地设备上运行,降低计算成本。
可定制化:
- 用户可自定义讲解风格(调整动画速度、添加额外解读)。
- 企业和教育机构可定制专属数学或科学教学视频。
7. 适用场景
✅ 在线教育:为 MOOC 平台(如 Coursera、Khan Academy)提供自动化数学和科学讲解视频。
✅ 学术研究:用于AI 解释性研究,帮助发现 LLM 的推理错误。
✅ 企业培训:适用于金融、工程、数据科学等专业培训,提供可视化教学材料。
✅ AI 透明性增强:提升 AI 生成内容的可解释性,确保模型决策更透明、更可验证。
一些案例
数学 - 积分的替换法
化学 - 凯尔达尔法分析
物理学 - 几何布朗运动
计算机科学 - 梯度下降法
数学 - 风筝的特性
数学 - 有理根定理
技术方法
TheoremExplainAgent 是一种基于代理的AI系统,旨在通过模仿人类视频制作过程,生成长时间(超过5分钟)的定理解释视频。
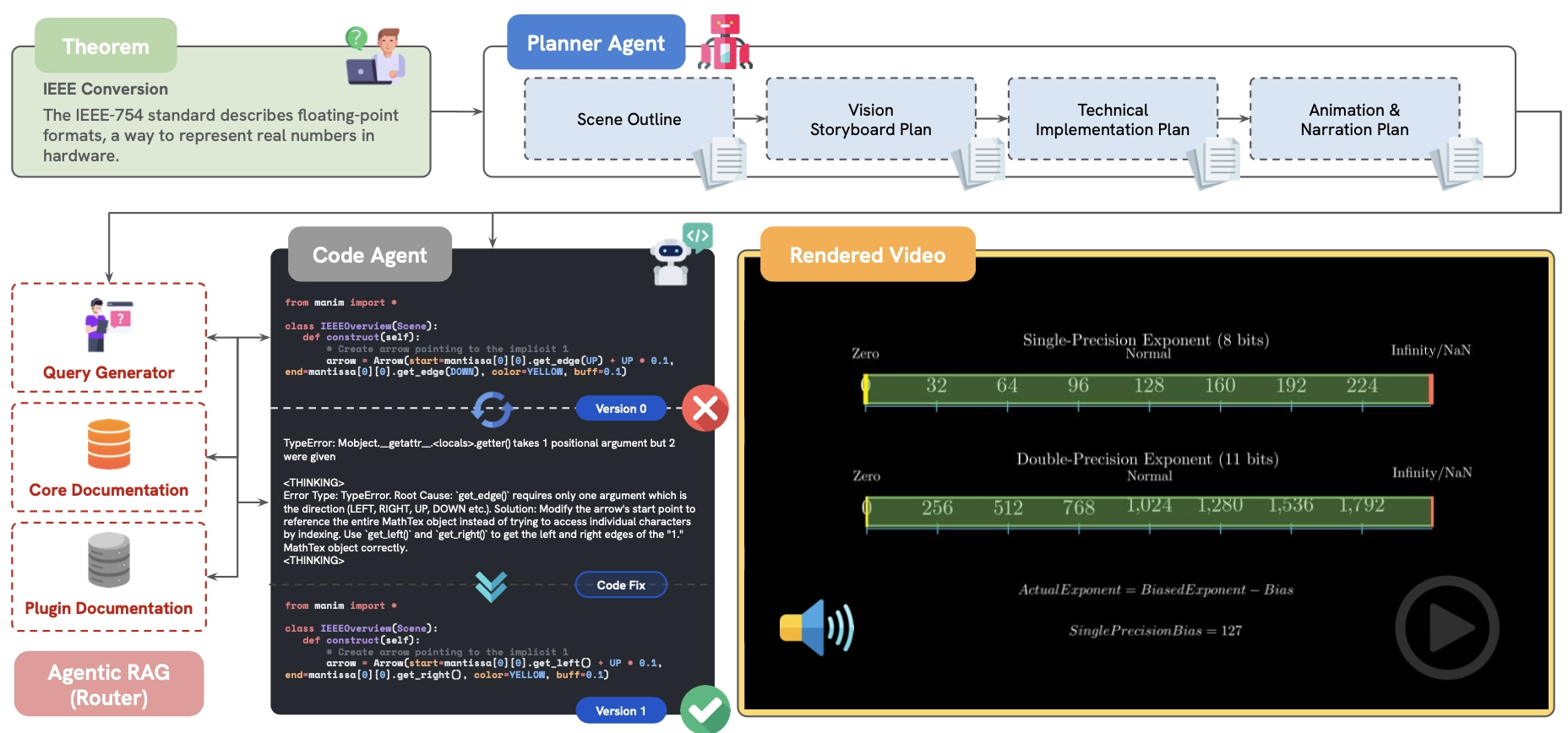
- 任务定义:
• 输入:一个定理及其简短描述,提供上下文。
• 输出:结合动画、结构化推导和画外音叙述的视频,长度超过1分钟,逐步讲解证明和应用。 - 系统架构:
• 规划代理(Planner Agent):根据定理生成高级视频计划,分解为多个场景,每个场景包括标题、目的、描述和布局。
• 编码代理(Coding Agent):将场景描述转换为使用 Manim(一个开源Python数学动画库)的可执行脚本,生成动画。画外音通过文本转语音服务生成。
• 错误修正:若代码出错,编码代理会迭代修正,最多尝试5次,否则标记为失败。 - 技术细节:
• 使用 Manim 作为可视化工具,因其在数学教育视频中的广泛应用(如3Blue1Brown频道)。
• 引入检索增强生成(RAG),利用Manim文档优化代码生成,分阶段检索视觉示例、代码片段和错误解决方案。
评估框架:TheoremExplainBench (TEB)
为了系统评估AI生成的多模态解释,作者开发了 TheoremExplainBench
数据集:
• 包含 240个定理,覆盖数学、物理、化学和计算机科学四个STEM学科。
• 来源于OpenStax和LibreTexts,按难度分为简单(高中)、中等(本科)、困难(研究生),每类80个。
• 涉及68个子领域,确保多样性。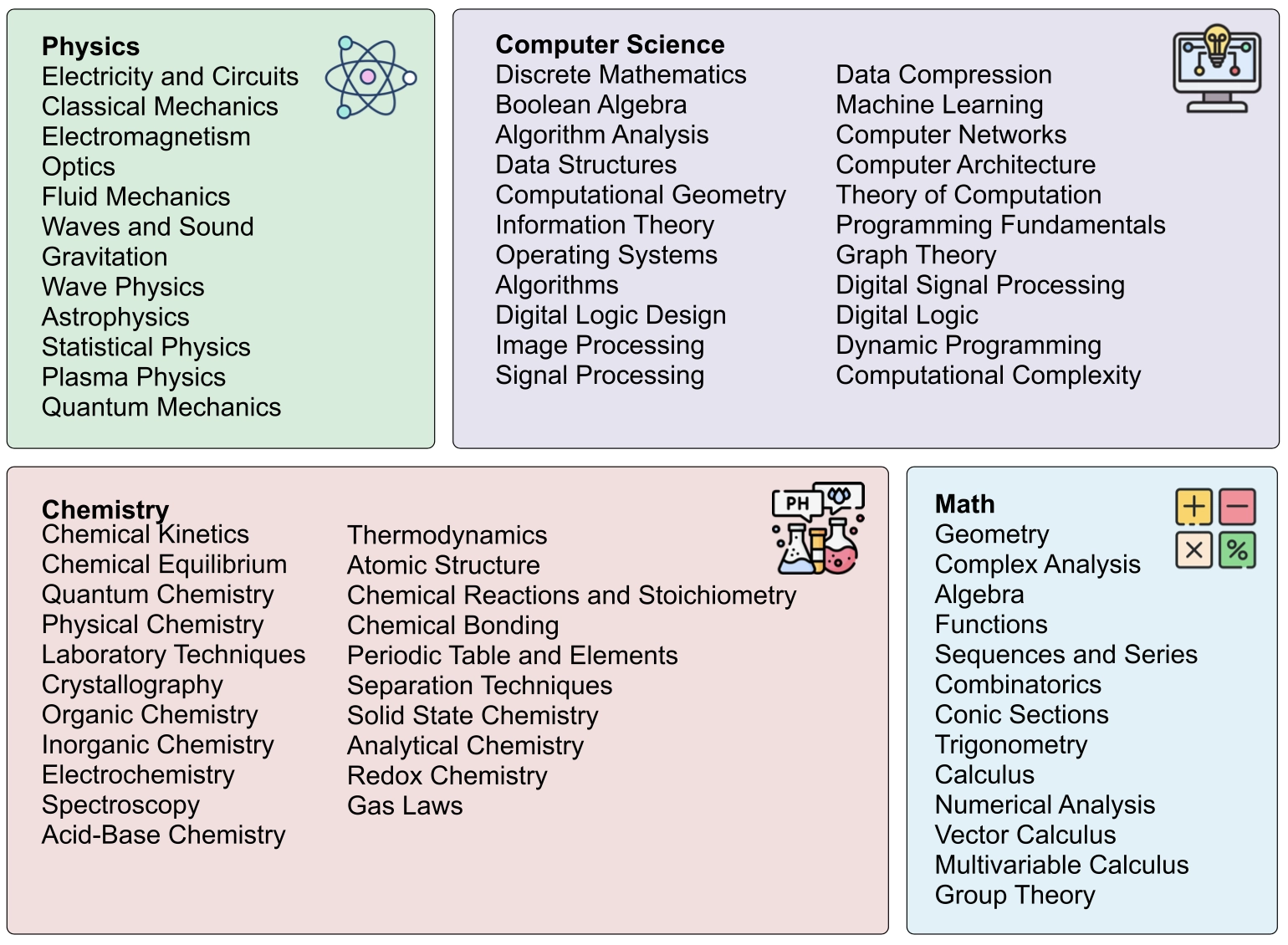
- 评估指标:
• 事实正确性:
• 准确性和深度:叙述是否准确且结构化,提供直观和严谨的解释。
• 视觉相关性:视频帧是否与定理概念对齐。
• 逻辑流程:视频结构是否清晰连贯。
• 感知质量:
• 元素布局:视觉元素是否摆放得当,无重叠且清晰。
• 视觉一致性:动画是否流畅,风格是否统一。
• 评分方法:使用GPT-4o评估文本维度,Gemini 2.0-Flash分析视觉一致性,总体得分取几何平均值(0-1)。 - 验证:
• 通过小规模人类研究(12名STEM学生)验证指标,与自动评估的相关性通过Spearman系数和Krippendorff’s alpha衡量。
实验结果
成功率:
• o3-mini 模型表现最佳,成功率达 93.8%,在不同难度和学科中均稳健。
• GPT-4o随复杂度增加成功率下降,Gemini 2.0-Flash表现最差。
• 数学领域成功率最高(95%),化学最低(93.3%),可能因化学中复杂对象(如分子)难以可视化。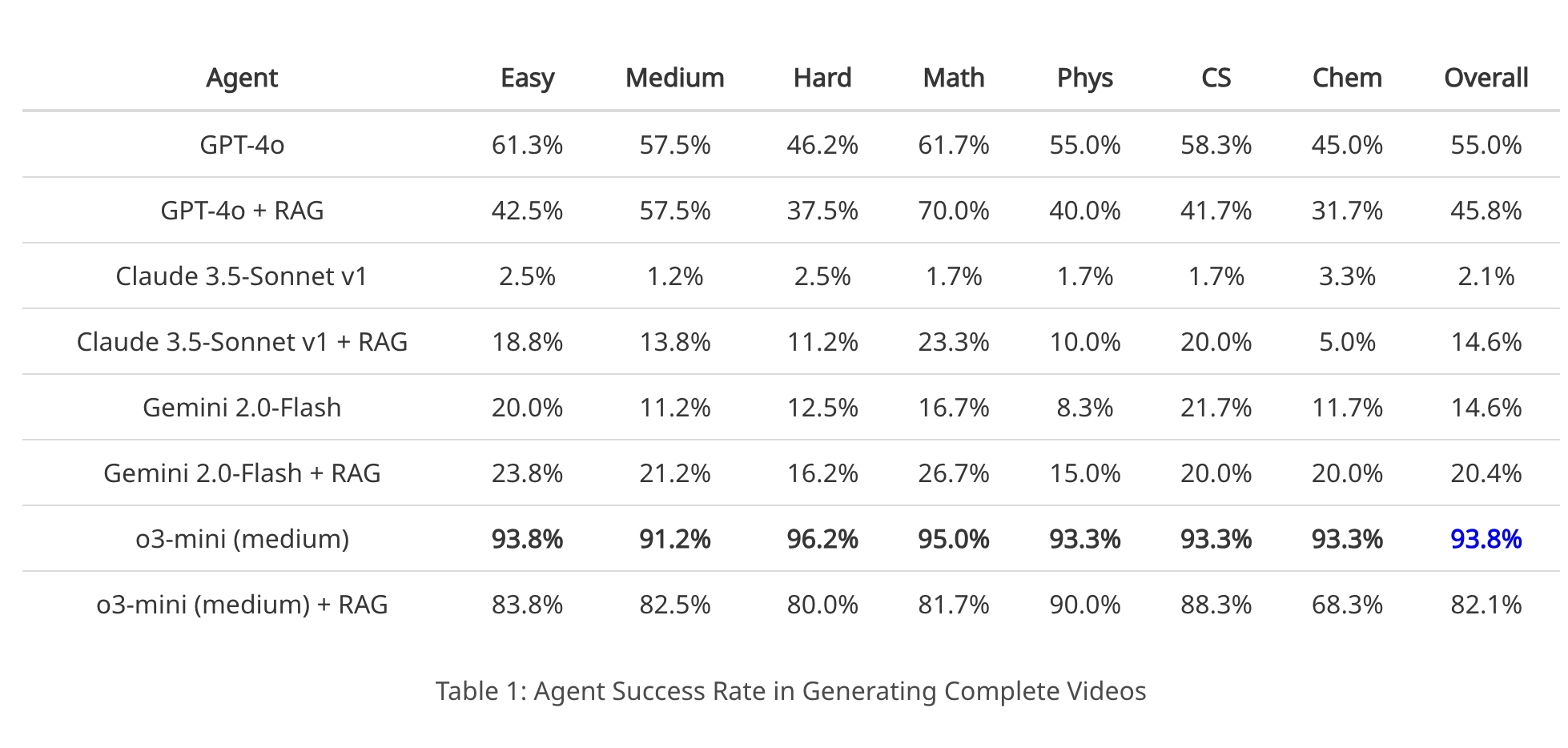
指标表现:
• o3-mini总体得分为 0.77,在逻辑流程(0.89)和视觉一致性(0.88)上表现优异,但在元素布局(0.61)稍弱。
• 人类制作的Manim视频在视觉相关性(0.81)和元素布局(0.73)上得分更高,但逻辑流程(0.70)较低。
• AI视频常见问题:轻微的视觉布局问题,如文本未对齐、形状重叠。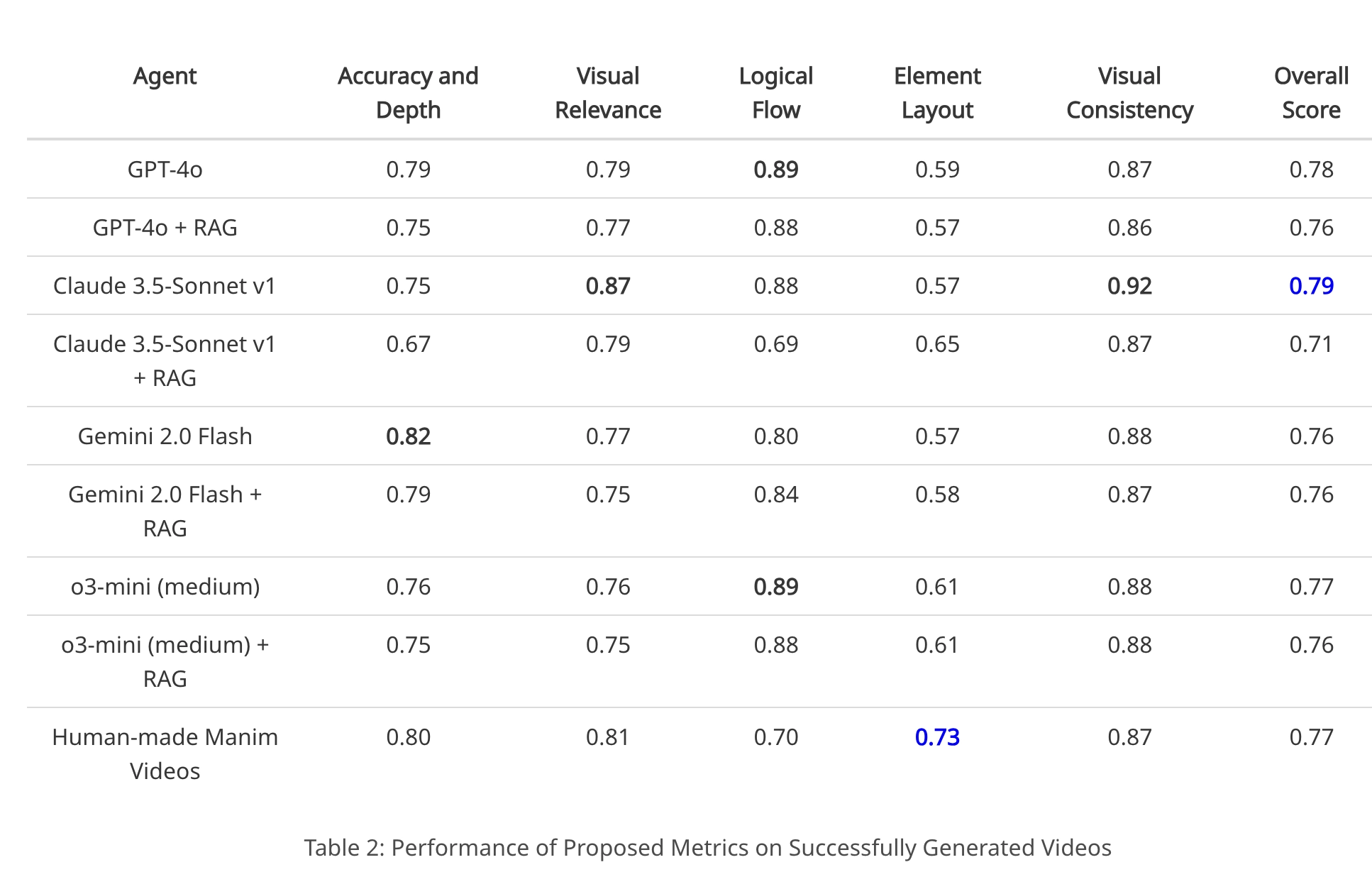
- 关键发现:
• 代理规划的重要性:无代理方法仅生成20秒视频,而TEA可达10分钟。
• 多模态暴露缺陷:视频解释揭示了文本评估忽略的深层推理错误。例如,链码定理视频中错误的方向编码清晰暴露了模型误解。
• 学科差异:数学和计算机科学视频质量高于化学,因后者依赖简单几何图元描绘复杂结构。 - 错误分析:
• 失败原因包括:
• Manim代码幻觉:调用不存在的函数或错误参数。
• LaTeX渲染错误:数学表达式语法问题。
• 编码错误:如缺少导入或计算错误。
局限性与未来方向
- 局限性:
• AI在视觉元素布局上仍有不足,如重叠和大小不一致。
• RAG增加计算成本,检索质量不稳定。 - 未来方向:
• 增强视觉结构技术,提升空间推理能力。
• 改进代理协调,优化视频生成流程。
• 推进视频理解,完善多模态评估指标。