OpenAI 正式发布 GPT-4.5 研究预览版,这是目前最大、最先进的 GPT 模型。该模型在无监督学习(unsupervised learning)和推理能力(reasoning)上取得了重大进步,并优化了人机交互体验,减少了幻觉现象(hallucination)。
GPT-4.5 的设计目标是成为一款非推理型(non-reasoning)模型的巅峰之作,同时为未来的技术路线(如 GPT-5)铺路。它在多个领域表现出色,包括写作、编程和实际问题解决,同时显著减少了“幻觉”(hallucination,即生成不准确或虚构内容)的发生。
GPT-4.5 目前提供给 ChatGPT Pro 用户和开发者,并计划逐步推广至其他用户群体。
然而,它并非革命性升级,也没有超越推理模型在特定领域的表现。GPT-4.5 发布后,一些人表示了失望,对于用户而言,GPT-4.5 提供了一个更智能、更可靠的聊天体验,但其高昂的成本和部分功能缺失也引发了一些讨论。
同时GPT-4.5 在部分基准测试上不如 Claude 3.5 ,甚至不如 Deepseek V3。
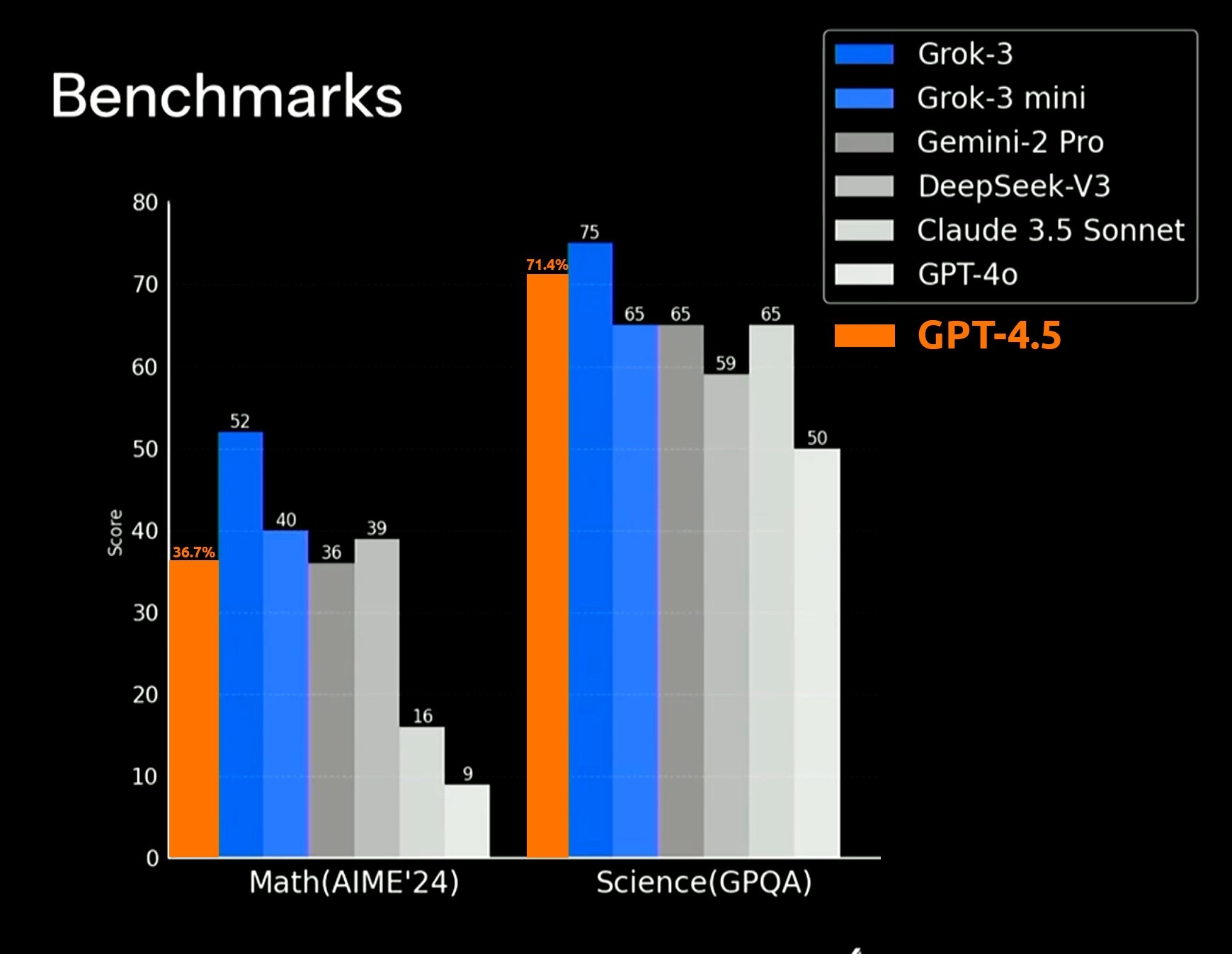
但是奥特曼对此有自己的说法,OpenAI 首席执行官 Sam Altman 表示,GPT-4.5 是其“最后一代非推理模型”,未来产品将整合更多技术(如推理能力)。
“这不是一个推理模型,也不会打破任何基准。这是一种不同的智能,我从未体验过这样的魔力。真的很期待大家来尝试!”

根据OpenAI官方的介绍,GPT‑4.5 是一个非常庞大且计算密集的模型,训练时使用了比以往更多的计算资源和数据,训练的计算量可能是GPT4 的10倍。

GPT‑4.5 是一个通过提升计算能力和数据规模,以及架构和优化创新,来扩展无监督学习的例子。GPT‑4.5 在微软 Azure AI 超级计算机上进行训练,最终形成了一个知识面更广、对世界理解更深的模型,从而减少了幻觉现象,并在多个主题上提供了更高的可靠性。

GPT 4.5主要特点
规模与知识深度:
• GPT-4.5 是 OpenAI 有史以来最大的模型,训练时使用了比以往更多的计算资源和数据。
• 与 GPT-4o 相比,其“世界知识”(world knowledge)更深,覆盖范围更广,能够理解更复杂的背景和语境。
• OpenAI 表示,模型规模的提升使其更少需要“凭空捏造”答案,幻觉现象显著减少。情感智能与对话自然性:
• GPT-4.5 在“情感直觉”(emotional intelligence)方面有所突破,能够更好地捕捉人类意图和情绪。
• 用户反馈显示,与 GPT-4o 相比,GPT-4.5 的对话更自然,尤其在日常查询、专业任务和创意写作(如诗歌创作)中表现更优。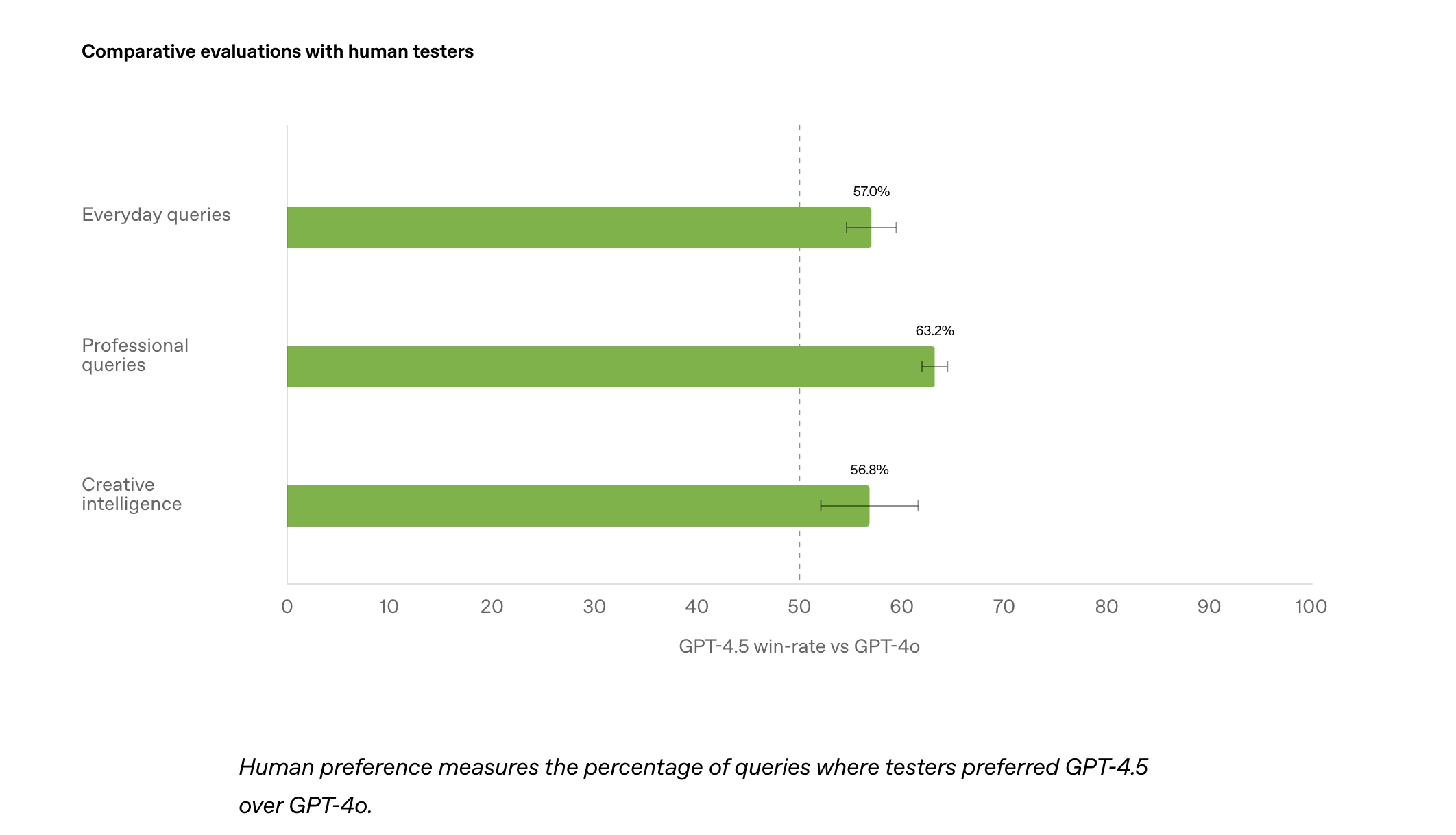
通用性设计:
• 与 OpenAI 的“o系列”(如 o1、o3-mini)推理模型不同,GPT-4.5 并非专注于数学或科学推理,而是定位为通用型模型。
• 它适用于广泛的应用场景,包括写作、编程、问题解决等。功能支持:
• 支持实时网页搜索、文件和图像上传,以及 ChatGPT 的 Canvas 工具。
• 暂不支持语音模式(Voice Mode)、视频或屏幕共享功能。
性能表现
OpenAI 提供了多项基准测试数据,以展示 GPT-4.5 的能力:
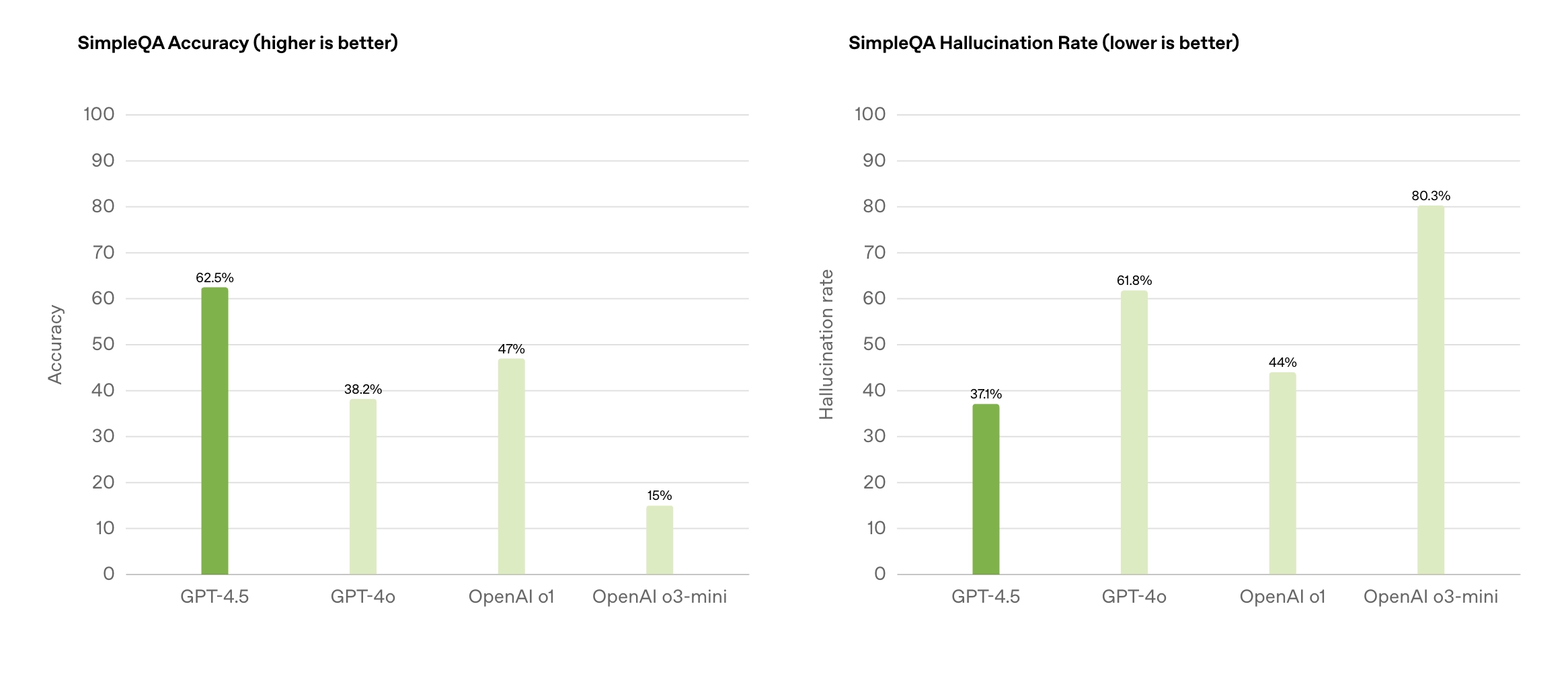
- SimpleQA 测试(OpenAI 开发的一个常识性问答基准):
- GPT-4.5 得分 62.5%,显著高于 GPT-4o 的 38.6% 和 o3-mini 的 15%。
幻觉率:GPT-4.5 为 37.1%,低于 GPT-4o 的 59.8% 和 o3-mini 的 80.3%。
MMLU 测试(语言理解基准):
• 与 GPT-4o 相比提升有限,但在语言任务中略有优势。
• 数学与科学测试:
• GPT-4.5 在这些领域的表现不如 o3-mini 等推理模型,表明其并非专注于 STEM(科学、技术、工程、数学)任务。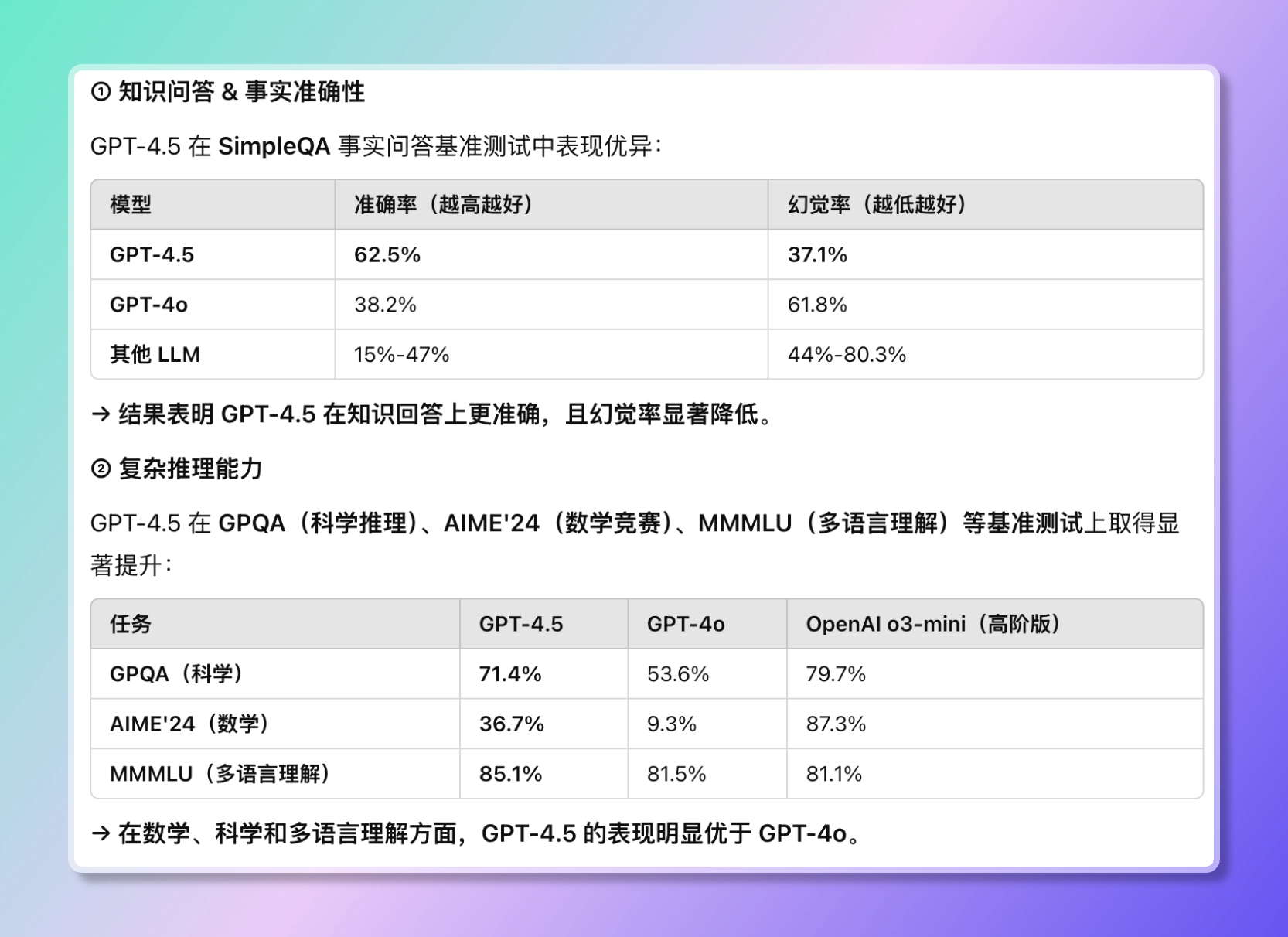
研究人员指出,基准测试无法完全反映 GPT-4.5 的实际体验。用户可能在写作、编程等非量化任务中感受到更显著的进步。
与前代模型的对比
与 GPT-4o 的差异:
• GPT-4.5 在预训练阶段投入了更多资源,规模相当于从 GPT-3.5 到 GPT-4o 的跳跃。
• 它减少了幻觉,提升了写作能力和对话流畅性,但未引入突破性的新功能。与推理模型(o1、o3)的区别:
• o系列模型擅长逐步推理(chain-of-thought),适合数学和科学问题。
• GPT-4.5 则更注重即时响应和通用性,不以推理为核心。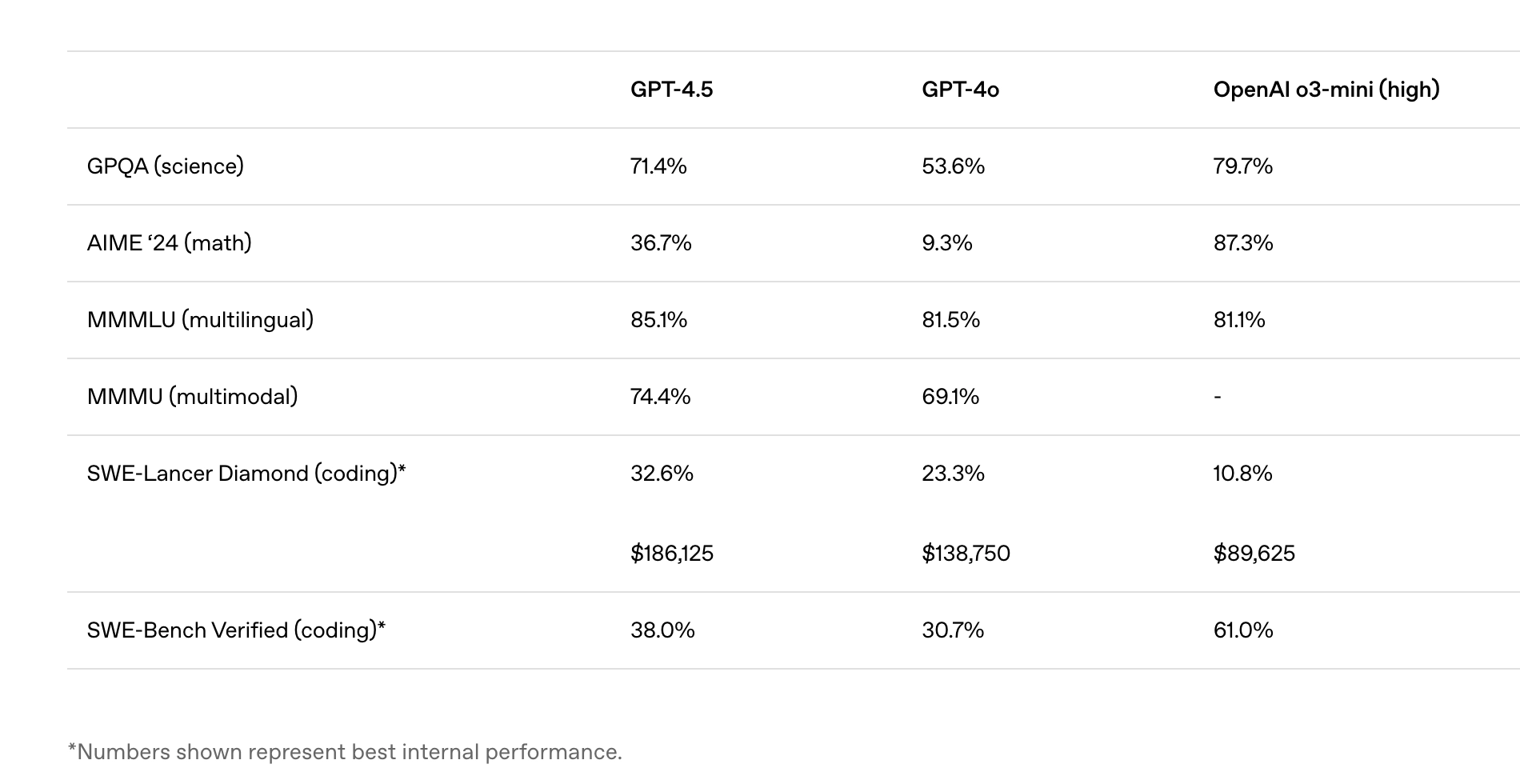
OpenAI 首席执行官 Sam Altman 表示,GPT-4.5 是其“最后一代非推理模型”,未来产品将整合更多技术(如推理能力)。
GPT-4.5 目前已在 ChatGPT Pro 版本中开放,未来将逐步开放:
- 下周:ChatGPT Plus 和 Team 版 用户可使用 GPT-4.5。
- 再后一周:企业版(Enterprise)和教育版(Edu) 用户可使用。
API 预览版已开放:
- 支持文件和图像输入
- 支持函数调用、结构化输出、流式响应
- 不支持语音模式、视频、屏幕共享(未来可能增加)
Price 价格信息
Input: 输入内容:
$75.00 / 1M tokens $75.00 / 100 万代币
Cached input: 缓存的内容:
$37.50 / 1M tokens 每百万代币 $37.50
Output: 输出内容:
$150.00 / 1M tokens $150.00 / 100 万代币

GPT-4.5 各方评价
X 平台用户对 GPT-4.5 的评价呈现两极分化。一部分用户对其在对话自然性、知识广度和创意写作方面的进步表示认可;另一部分用户则对其性能提升有限、定价过高以及在编程和推理任务中的不足表示失望。以下是详细分析:
正面评价
对话自然性和创意写作
• 许多用户称赞 GPT-4.5 在对话中的自然流畅性,尤其是在创意任务中表现突出。例如,有用户表示,它在写作故事和诗歌时展现出“强烈的直觉和有趣的个性”。
• 一位用户提到,虽然 GPT-4.5 的回答有时过于华丽冗长,但通过调整提示词,可以使其风格更符合个人需求。
知识广度和图像理解
• 用户反馈 GPT-4.5 在知识储备和图像处理方面有所提升。一位用户指出,它能准确处理复杂视觉信息并提取数据,表现优于前代模型。
• 此外,GPT-4.5 的多语言能力有所改进,即便用户主要关注英文内容,也有人提到它在非英语语言中的表现更强。
人性化改进
• 一些推文指出,GPT-4.5 减少了拒绝回答的情况,回复更具人性化,格式也更规范,整体体验更友好。
负面评价
性能提升有限
• 多位用户认为 GPT-4.5 的性能提升不够显著。一则推文称,与 GPT-4o 相比,“差异微妙且不明显”,普通任务中几乎察觉不到进步。
• 另有用户抱怨 GPT-4.5 的响应速度明显慢于 GPT-4o,影响日常使用体验。
定价争议
• GPT-4.5 的定价引发广泛不满。API 费用为每百万输入 tokens 75 美元、输出 tokens 150 美元,远高于 GPT-4o 的 2.5 美元和 10 美元。用户质疑其性价比,认为“太贵了”。
• ChatGPT Pro 订阅费高达每月 200 美元,许多用户表示不愿支付,宁愿等待免费版本或选择更经济的替代品。
编程和推理能力不足
• 在编程和推理任务中,GPT-4.5 的表现令人失望。一些用户称其不如 Claude 3.7 Sonnet,尤其在编码方面差距明显。
• 一位用户表示,经过 30 分钟的测试,GPT-4.5 虽能提供有趣建议,但在解决实际技术问题时帮助有限。
规模化策略质疑
• 有用户认为,OpenAI 仅靠扩大模型规模提升性能的做法已接近极限。推文指出,GPT-4.5 验证了“规模化红利递减”,建议未来需更多创新。
中立评价
模型定位
• 部分用户认为,GPT-4.5 定位于提供自然对话和广泛知识,而非专注推理或编程,因此在某些任务中表现平庸属正常。
• 另有推文提到,其语言细腻度和情感智能有所提升,但这些优势难以通过测试量化,需实际使用才能体会。
观望态度
• 一些用户建议暂不订阅 ChatGPT Pro,等待更多评测。他们认为,目前的性能提升可能不足以支撑高昂费用。