微软 Phi 模型家族推出了两款新开源模型:Phi-4-multimodal 和 Phi-4-mini。这两款 小型语言模型(SLMs) 旨在为开发者提供先进的 AI 能力,优化跨文本、语音和视觉的多模态处理,同时提供高效的推理能力和低计算需求。
其优势包括高性能、低资源需求、边缘兼容性和成本效益,适用于金融、医疗等多个行业。
Phi-4-Multimodal:一款多模态模型,能够同时处理语音、视觉和文本,适用于需要跨多种数据类型进行理解和推理的创新应用。
Phi-4-Mini:一款专注于文本任务的紧凑型高性能模型,强调准确性和低资源消耗,适合需要高效计算的场景。
Phi-4-multimodal:多模态 AI 语言模型
Phi-4 多模态模型采用全新架构,提升了效率和可扩展性。它拥有更丰富的词汇量以提高处理能力,支持多语言功能,并将语言推理与多模态输入相结合。

Phi-4 多模态音频与视觉基准
核心特点
- 多模态融合:能够 同时处理语音、视觉和文本,不需要额外的管道或单独的模型来处理不同输入类型。
- 长上下文窗口:可处理和推理大型数据集,如文档、网页或代码。
- 高效推理 & 低计算开销:优化了 设备端运行,适用于移动端和边缘计算。
- 提升跨模态学习:通过跨模态学习技术,使 AI 设备能够更自然地理解上下文,实现更智能的交互。
行业领先的性能:
- 在 自动语音识别(ASR) 和 语音翻译(ST) 任务中,超过 WhisperV3 和 SeamlessM4T-v2-Large。
- 在 Hugging Face OpenASR 排行榜中取得 6.14% 词错误率(WER),优于之前最佳的 6.5%。
- 在 数学和科学推理、OCR(光学字符识别)、文档和表格理解 方面表现强劲,优于 Gemini-2-Flash-lite-preview 和 Claude-3.5-Sonnet。
Phi-4-Multimodal 的基准测试结果
Phi-4-multimodal 是一个 5.6 亿参数的多模态模型,能够同时处理语音、视觉和文本。以下是其在基准测试中的关键表现:
语音相关任务:
- 自动语音识别(ASR):在 Hugging Face OpenASR 排行榜上,Phi-4-multimodal 以 6.14% 的单词错误率(WER)位居第一,超越了此前的领先模型(6.5%,截至 2025 年 2 月)。它优于专业 ASR 模型 WhisperV3。
- 语音翻译(ST):表现超过 SeamlessM4T-v2-Large 等专用语音翻译模型。
- 语音问答(Speech QA):与 Gemini-2.0-Flash 和 GPT-4o-realtime-preview 等模型相比仍有差距,因其较小的模型规模限制了事实性知识的保留能力,但仍表现强劲。
语音摘要(Speech Summarization):作为首个开源模型实现此功能,性能接近 GPT-4o。

视觉相关任务:
- 在数学和科学推理、文档与图表理解、光学字符识别(OCR)以及视觉科学推理等常见多模态任务中,Phi-4-multimodal 的表现与 Gemini-2-Flash-Lite-Preview 和 Claude-3.5-Sonnet 等热门模型相当,甚至在某些方面领先。
在涉及视觉和音频输入的综合测试中,Phi-4-multimodal 大幅优于 Gemini-2.0-Flash,并在与专为多模态设计的开源模型 InternOmni(参数量更高)比较时占据优势。
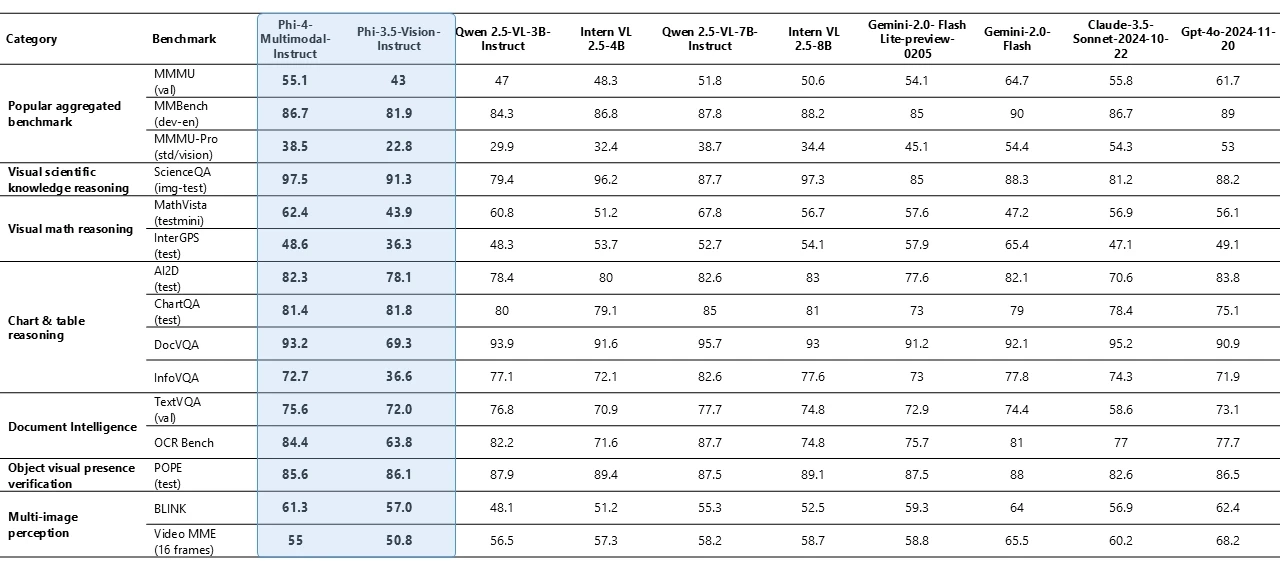
与其他模型比较:
- 在语音任务中优于 WhisperV3 和 SeamlessM4T-v2-Large,在多模态任务中与 Gemini-2.0-Flash 和 Claude-3.5-Sonnet 竞争,接近 GPT-4o 的水平。
在视觉和音频综合测试中大幅领先 Gemini-2.0-Flash,显示其多模态处理的独特优势。
总体表现:
- 在微软内部的多项视觉数据处理基准测试中,平均得分达到 72 分,略低于 OpenAI 的 GPT-4(差距不到 1 分),而 Gemini Flash 2.0 得分为 74.3 分。这种接近顶级模型的表现显示其在多模态任务中的竞争力。
Phi-4-mini:高效文本 AI 模型
核心特点
文本专精:擅长文本任务,如财务计算、报告生成和多语言文档翻译。
更小但强大:3.8B 参数,采用 密集解码器架构,支持 200,000 词汇量,针对文本任务优化。
- 高效计算:支持 128,000 token 长上下文,擅长 推理、数学、编程、指令跟随、函数调用等任务。
外部知识访问能力:
- 通过 函数调用,可与外部工具和API集成,执行查询数据库或控制智能系统等任务。(如智能家居控制)
资源需求低,适合边缘设备等计算受限环境。适用于制造、医疗、零售等多个行业。

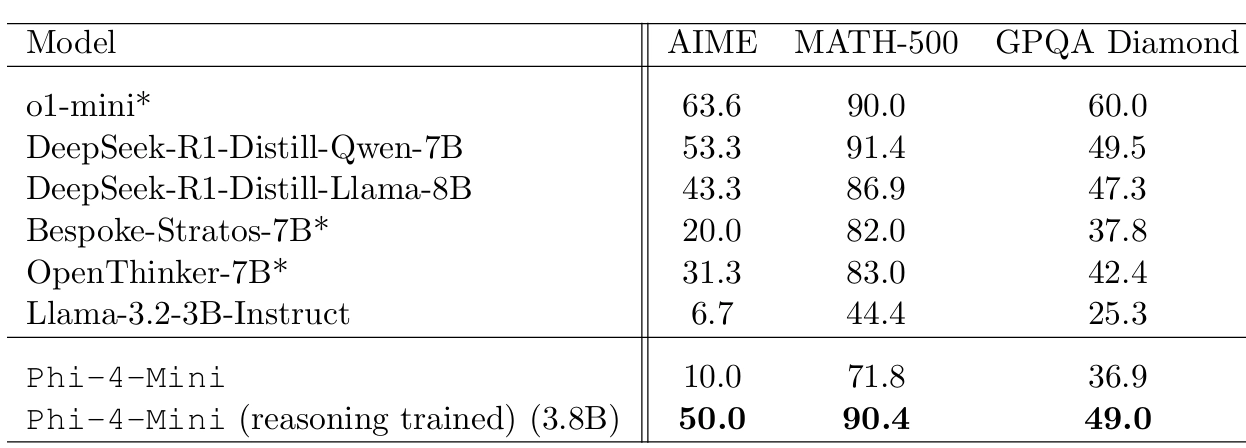
Phi-4-Mini 的基准测试结果
Phi-4-mini 是一个 38 亿参数的文本专用模型,专注于高效性和文本任务。以下是其基准测试的关键表现:
文本任务:
- 数学和编码任务:在需要复杂推理的数学和编码任务中,Phi-4-mini 的准确性显著优于同等规模的其他语言模型。文章未提供具体数值,但强调其在这些领域的表现“显著更好”。
- 多语言支持:在多语言文本处理(如翻译)中表现出色,相较于 Phi 家族早期模型有明显提升。
推理能力:通过长上下文窗口(未具体说明长度,但提到支持大量文本输入)和函数调用功能,能够高效处理财务计算、报告生成等任务。
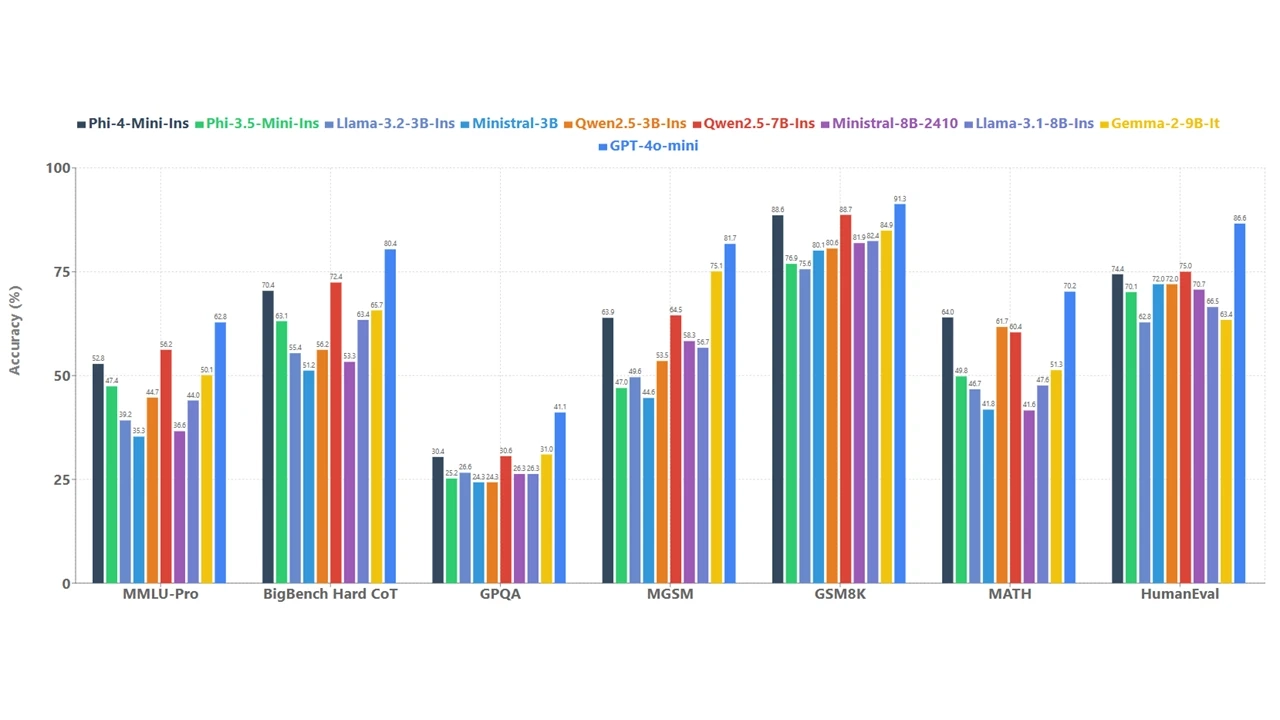
总体表现:
- 微软表示,Phi-4-mini 在内部测试中显示出超越同等规模模型的能力,尤其是在需要推理能力的任务中表现突出。然而,文章未提供与其他知名模型(如 GPT-4o-mini 或 Llama 系列)的直接数值对比。
Phi-4 的应用场景
智能手机集成:
- 处理语音命令、图像识别、文本理解,提供实时语言翻译、智能助手、增强照片和视频分析等功能。
自动驾驶 & 车载助手:
- 识别驾驶员语音指令、分析视觉输入(如手势、面部表情)、提供驾驶安全警报等。
金融 & 业务自动化:
- 进行复杂金融计算、生成报告、翻译财务文件,优化全球客户关系。
这些模型已在 Azure AI Foundry, HuggingFace, and the NVIDIA API Catalog 目录中上线
Model: https://huggingface.co/microsoft/Phi-4-multimodal-instruct
Blog: https://azure.microsoft.com/en-us/blog/empowering-innovation-the-next-generation-of-the-phi-family/