如何使用 Gemini 把播客转成格式良好文本
很多朋友跟我一样,日常有把视频、播客、会议记录音频转成文本的需求,尤其是要识别出发言人,把发言人和发言内容对上,这样可以节约大量时间去听几个小时视频,而且不会漏掉重点,毕竟文字阅读速度还是快多了。而且有了文本,还可以进一步生成摘要、写一篇文章。
我自己一般会用 Google 的 Gemini 2.0 pro 模型来做这事,尤其是在 AIStudio(https://aistudio.google.com/)中使用 Gemini 所有模型还是免费的,只是麻烦的是 AIStudio 只对部分国家地区开放,在国内是无法直接访问的,可惜这方面我也没什么办法。
这里重点还是分享一下日常我是如何借助 AI 来转换音视频文稿的。通常我有几种场景:
- 生成带发言人和时间戳的
- 生成段落格式友好的文稿(还可能加上翻译)
提示词怎么写?
这两种提示词会略有差别,但要点都是:
- 要求:你希望模型做的事情,比如让 AI 提取音频文稿
- 背景信息:这个音频主题是什么?参与人都有谁?一些专有名词(可以避免识别时的拼写错误)是什么?
- 输出格式:你可以规范输出的格式,而且你可以用大括号包起来的占位符来描述各个部分的位置。
比如下面是我用过的两套提示词供参考:
请按照 Speaker 提取文稿
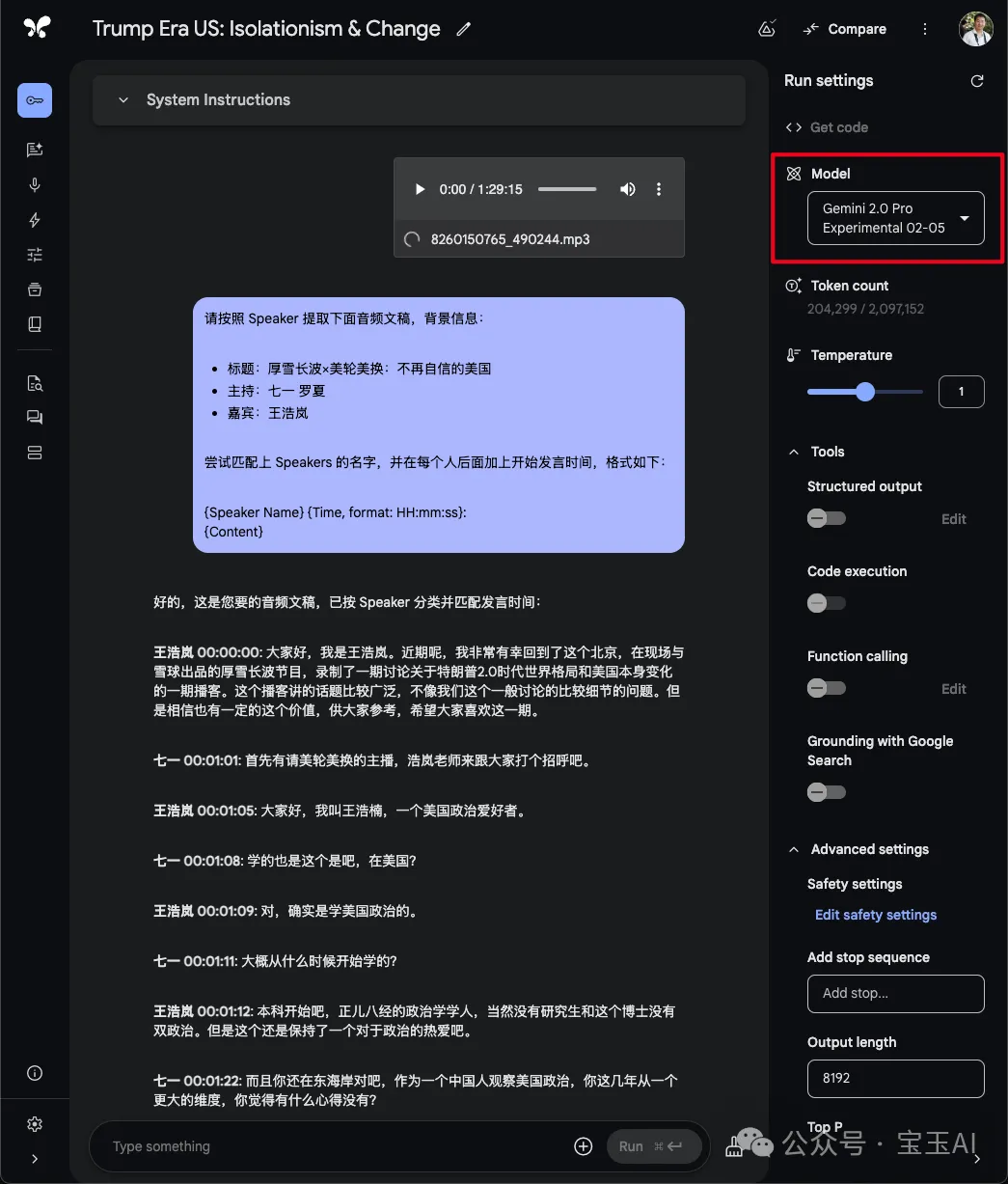 ```
请按照 Speaker 提取下面音频文稿,背景信息:
```
请按照 Speaker 提取下面音频文稿,背景信息:
标题:厚雪长波×美轮美换:不再自信的美国
主持:七一 罗夏
嘉宾:王浩岚
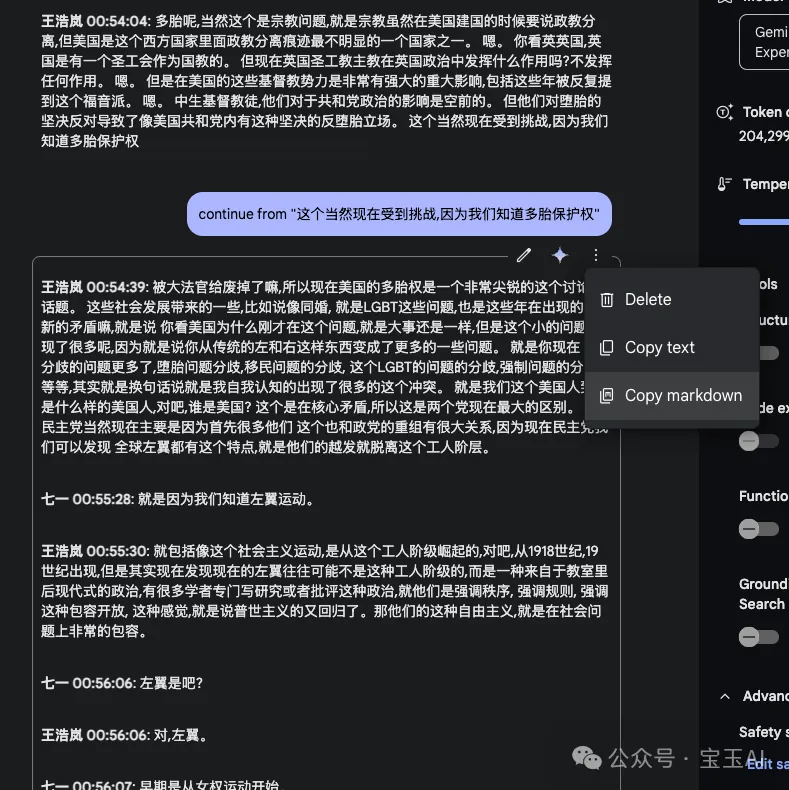
尝试匹配上 Speakers 的名字,并在每个人后面加上开始发言时间,格式如下:
{Speaker Name} {Time, format: HH:mm:ss}: {Content} ``` 按照段落格式整理文本并翻译成中文
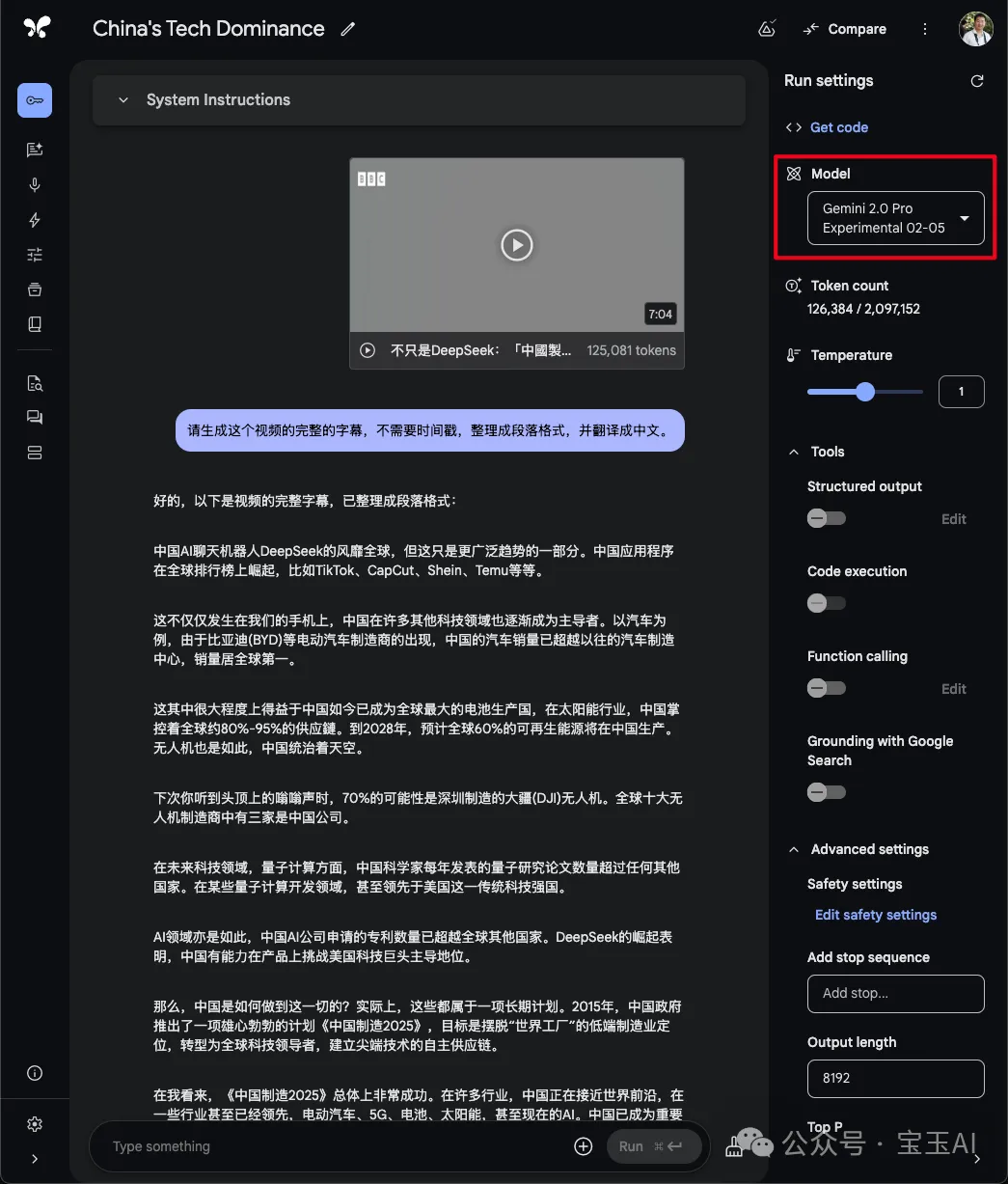
请生成这个视频的完整的字幕,不需要时间戳,整理成段落格式,并翻译成中文。
模型怎么选?
优先使用 Pro 模型,虽然速度慢一些,但是输出质量最好,无论是 Gemini 1.5 Pro 还是 Gemini 2.0 Pro 都可以。Lite 模型会幻觉比较严重。
视频文件还是音频文件?
- 如果你只需要音频转成文本,那么就把视频先转换为 mp3 或者 wav 等音频格式减少输入体积;
- 如果视频文件体积很小,就没必要费事直接发过去简单;
- 如果你的文稿依赖于视频画面,并且视频文件不是很大,那也可以直接用视频,尤其是有些只有画面没有声音的视频,Gemini 的多模态做得很好,视频音频都可以识别。
如果一次输出不完整怎么办?
AI Studio 上,每次输出的 Token 限制最大 8K,超过了就会自动停止,通常每次只能输出 20-30 左右的音频长度,当出现输出中断后,只需要输入“continue”或者“继续”就可以让它继续输出。但是当音频长度超过 2 小时,可能继续输出会幻觉很严重,输出内容和音频对不上。所以这种情况下要把视频分割成若干段,每一段不要超过 2 小时,甚至更短。
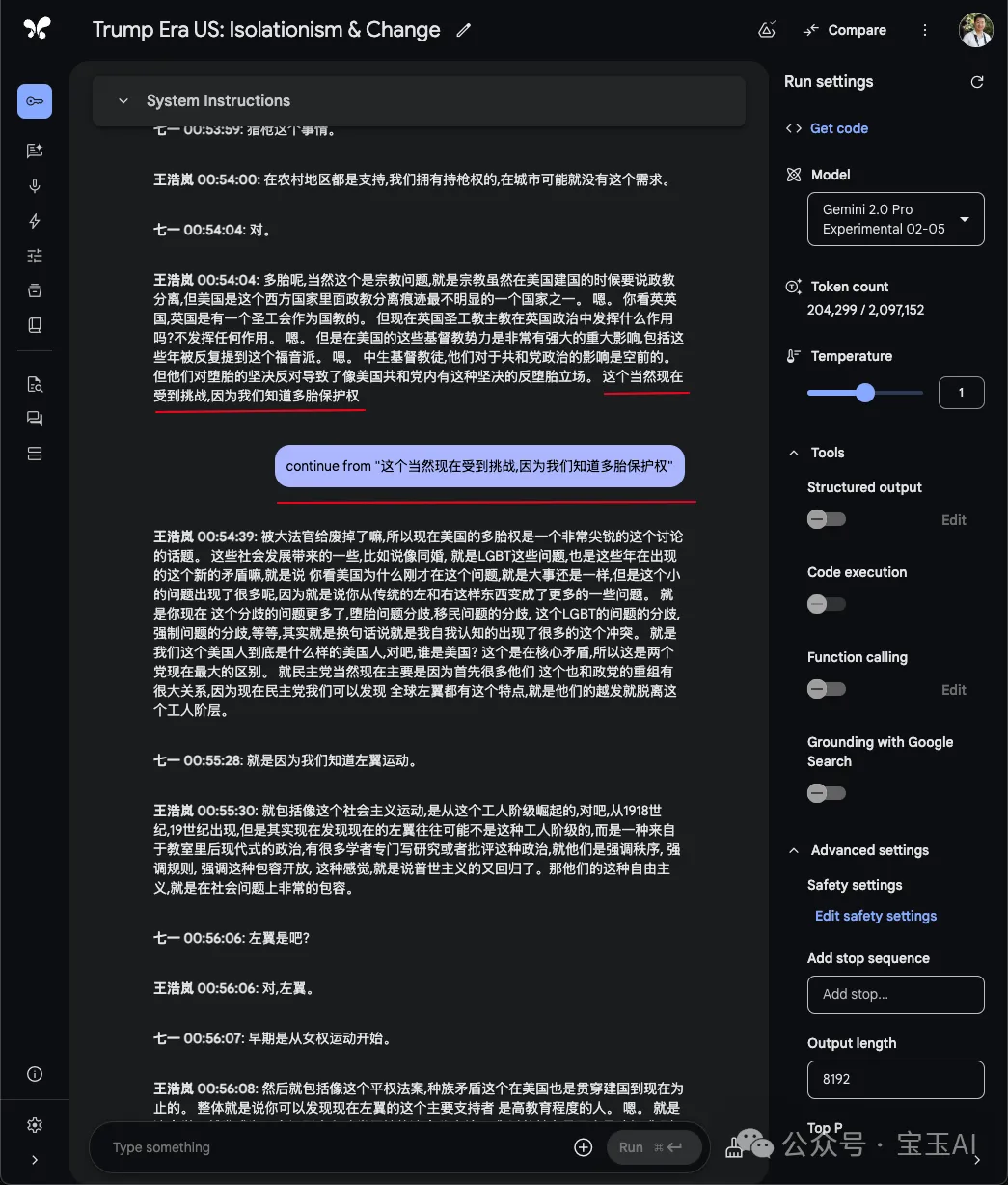
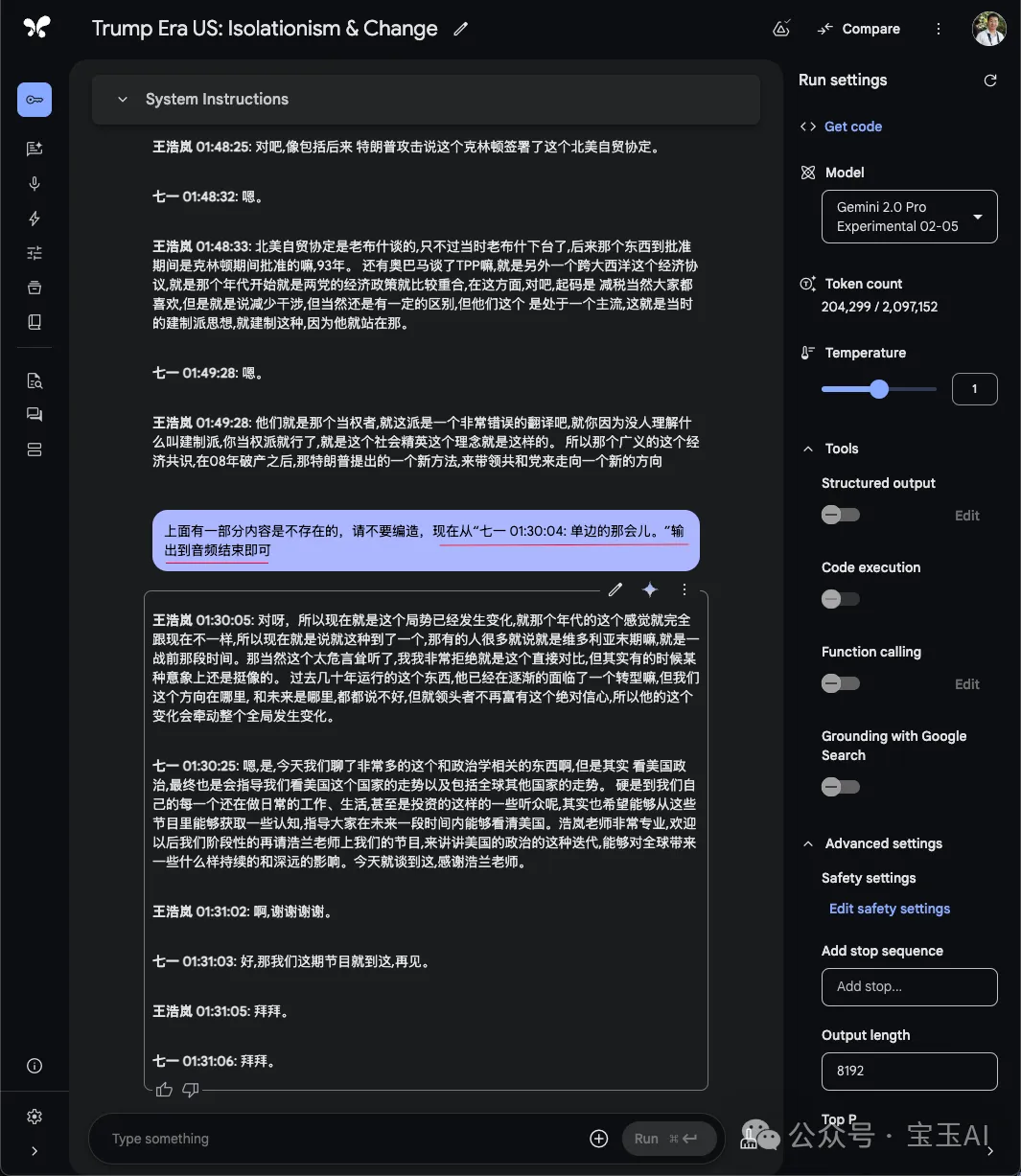
出现幻觉怎么办?
大语言模型在输出时,可能会有幻觉,有时候明明音频已经结束了,但在继续编造后续内容,音频长度越长越可能出现幻觉,所以一定要校对,对一些关键位置对照一下输出的内容。
每一次输入“continue”继续输出后,最好检查一下,如果发现幻觉了,可以把这一段删除,重新开始。如果最后出现幻觉的内容不多,也可以不删除,在输入“continue”的时候,可以加上继续输出的位置,这样它可以从你要求的位置重新生成,这样也可以有效避免。
怎么导出输出的内容?
AIStudio 在导出对话历史上做的很糟糕,你只能一条一条复制粘贴出去,在每条消息菜单上,都有一个复制文本或者复制 Markdown 的菜单项,建议复制为 Markdown,并且结合 Markdown 编辑器,这样可以保留加粗等格式。
除了 Gemini 还有没有其他选择?
很多人没条件访问 Gemini,或者隐私数据不想被泄露,这种情况下建议使用 Whisper 模型相关,Mac 下我推荐使用开源的 WhisperKit:https://github.com/argmaxinc/WhisperKit,用 Python 的话可以试试:
- stable-ts:https://github.com/jianfch/stable-ts
- WhisperX:https://github.com/m-bain/whisperX
商业的飞书妙记和 MemoAI 也不错,这都是我自己用过的靠谱的,唯一的问题就是 Whisper 这类模型不能直接识别发言人,要识别发言人还要配合其他模型。