大语言模型(LLM)到底是怎么运作的?(配图通俗讲解)
在讲LLM之前,我们得先搞懂什么是条件概率。
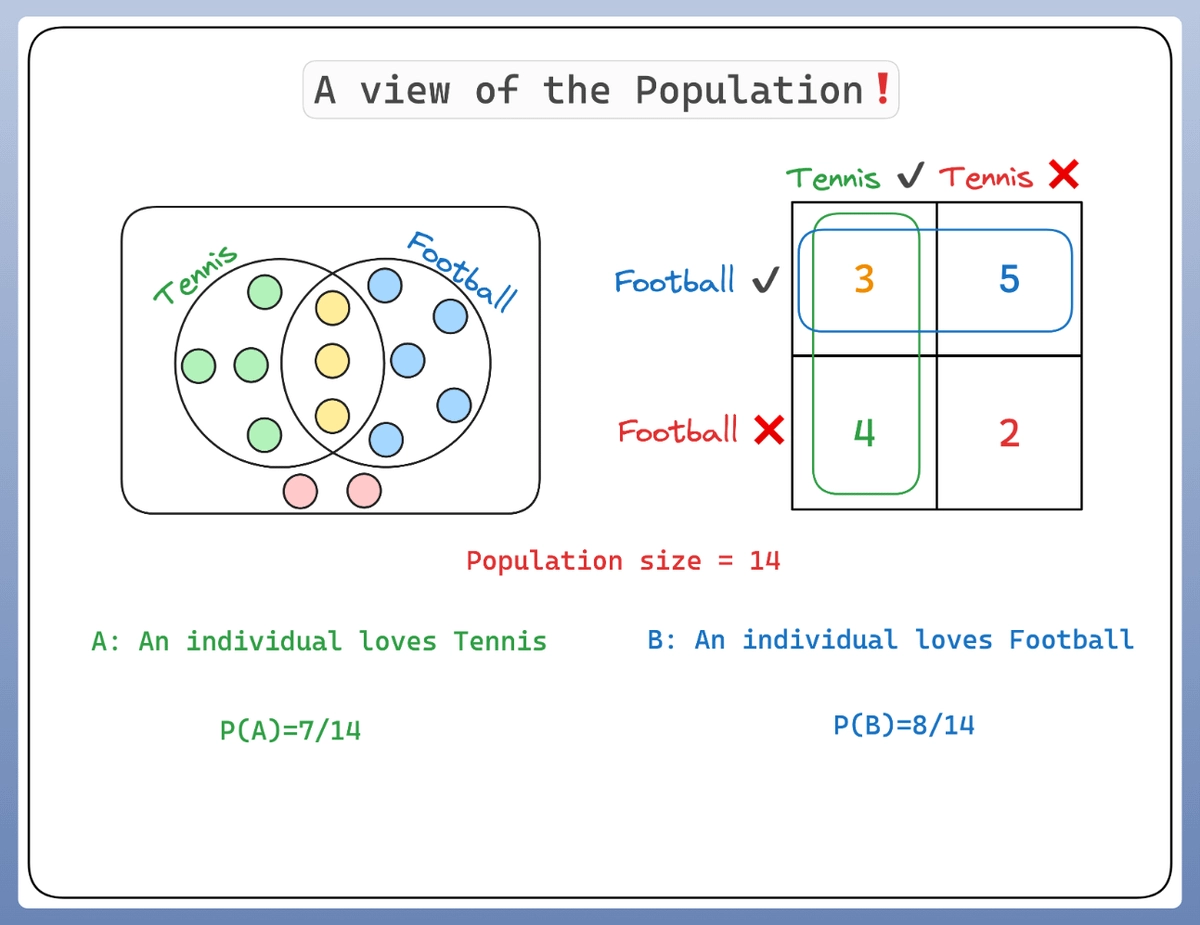
比如我们现在有14个人:
- 有些人喜欢网球🎾
- 有些人喜欢足球⚽
- 还有少数人同时喜欢两种运动🎾⚽
- 而另外一些人,两种都不喜欢
我们可以用下面的图清晰地表示这群人的偏好👇:
 那到底什么是条件概率呢?
那到底什么是条件概率呢?
条件概率就是指,在已知某个事件发生的前提下,另一个事件发生的概率。如果我们用事件A和事件B来表示,可以写作P(A|B),读作“在B发生的条件下,A发生的概率”。
看看下面这个直观的图示👇:
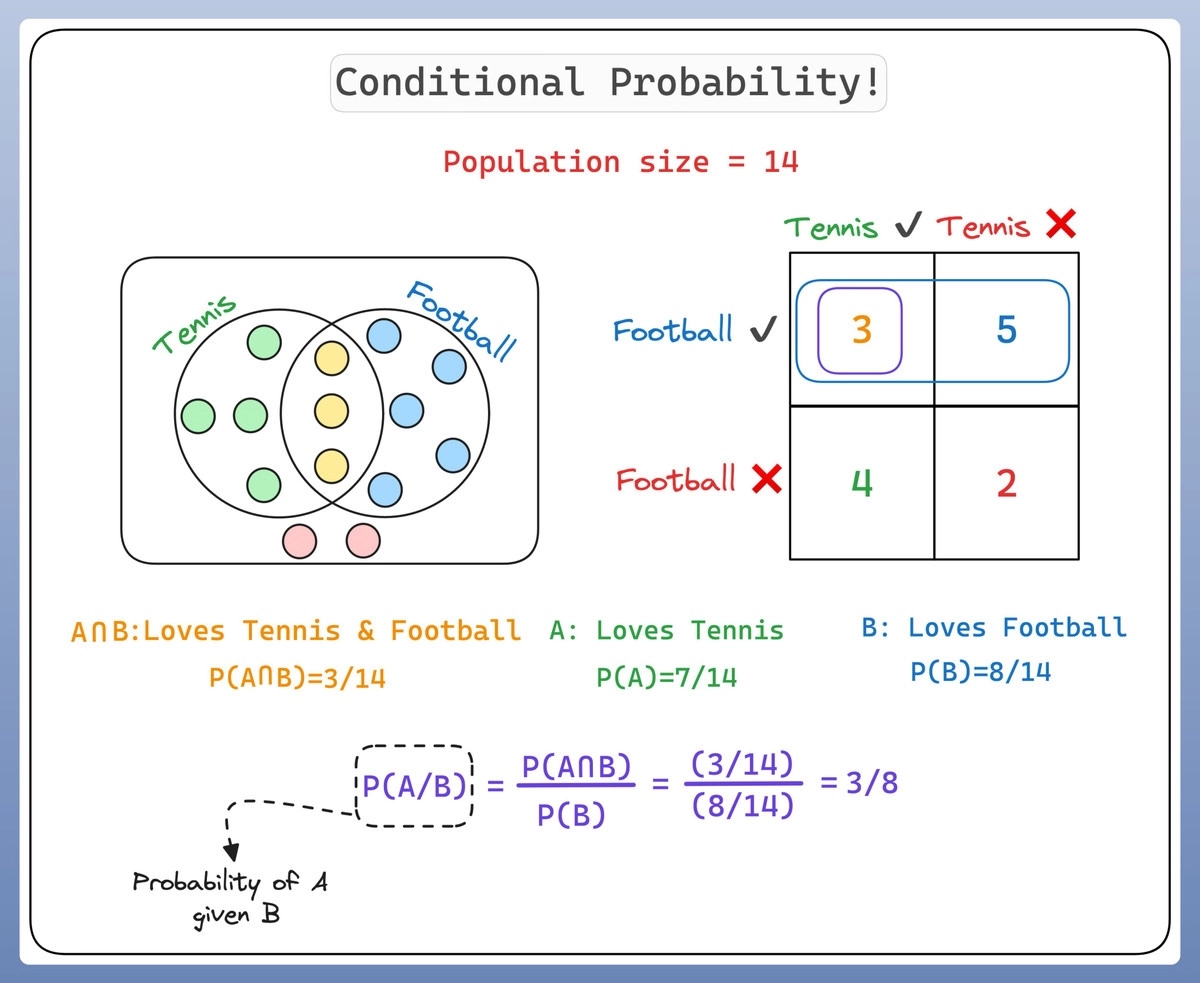 比如,我们预测今天是否下雨(事件A),如果已知天空阴云密布(事件B),我们预测下雨的可能性就会增加,这时我们就说条件概率P(A|B)比较高。这就是条件概率!
比如,我们预测今天是否下雨(事件A),如果已知天空阴云密布(事件B),我们预测下雨的可能性就会增加,这时我们就说条件概率P(A|B)比较高。这就是条件概率!
那么,这和GPT-4这样的LLM有什么关系呢?
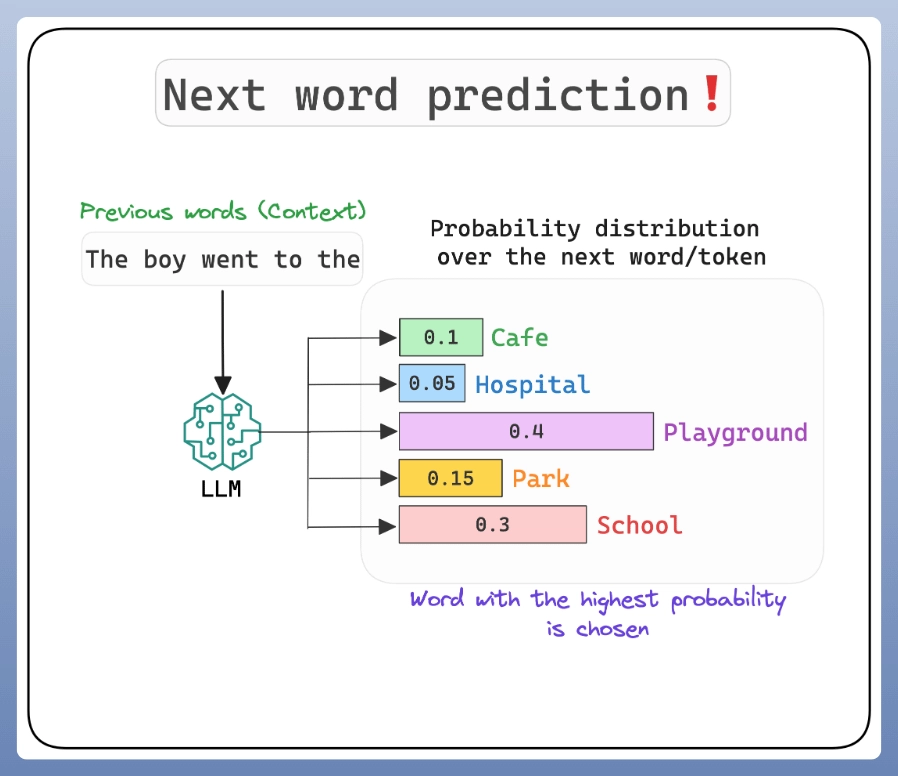
大语言模型的任务就是预测句子里下一个单词会是什么,这本质上就是一个条件概率的问题:
已知前面出现的一系列单词(上下文),下一个单词最可能是什么?
为了预测下一个单词,模型会计算所有可能的单词在给定上下文条件下的条件概率,然后选择概率最高的那个单词作为预测结果。
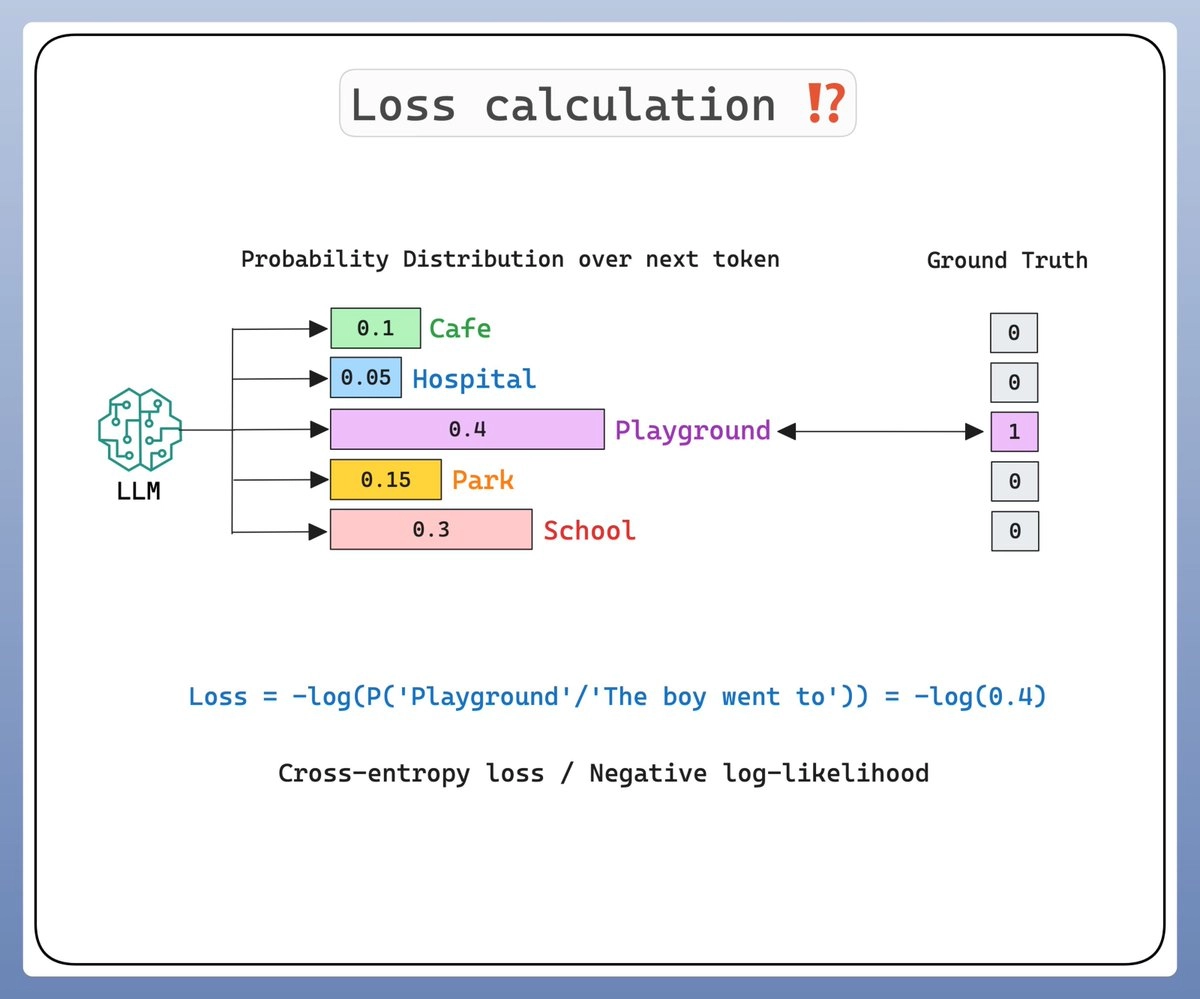
 大语言模型其实是在学习一个高维的单词序列的概率分布,而训练过程中调整的那些“参数”,就是这个概率分布中的权重。这个训练过程(或更准确地说是预训练过程)是有监督的。下一次,我会再深入介绍训练的具体过程,先看下面这张图理解一下👇:
大语言模型其实是在学习一个高维的单词序列的概率分布,而训练过程中调整的那些“参数”,就是这个概率分布中的权重。这个训练过程(或更准确地说是预训练过程)是有监督的。下一次,我会再深入介绍训练的具体过程,先看下面这张图理解一下👇:
不过,直接挑选概率最高的单词存在一个问题!
如果每次都选概率最高的单词,那么模型输出的内容就会变得非常重复、单调,让LLM变得毫无创意。这时候就要用到温度(Temperature)这个概念了。
先看下面的图,再来具体讲讲温度是什么👇:
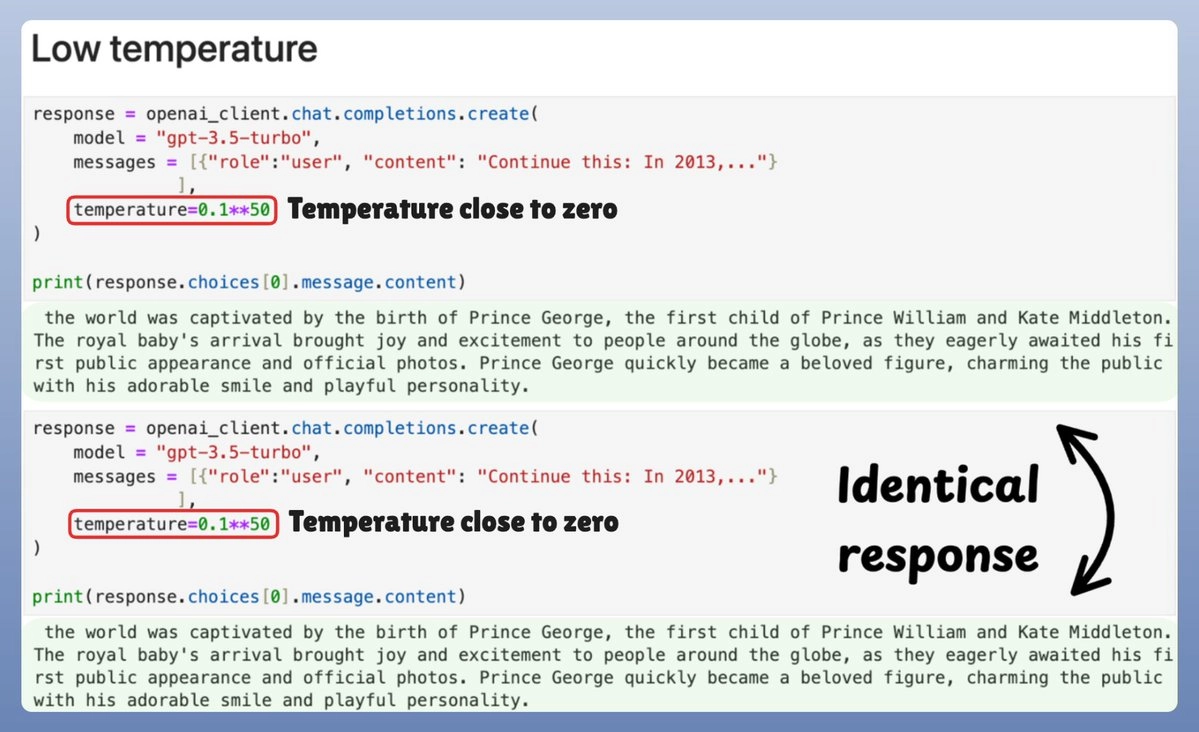 但如果温度设置得太高,又会产生乱七八糟、毫无意义的内容。到底发生了什么呢?看下图👇:
但如果温度设置得太高,又会产生乱七八糟、毫无意义的内容。到底发生了什么呢?看下图👇:

到底什么是温度(Temperature)?
大语言模型并不是简单地选择得分最高的那个“词”(为简单起见,我们把token视为单词),而是会从概率分布中随机抽样(sampling):
即使“词1”的概率最高,也不一定会选中它,因为我们是从分布里抽样的。
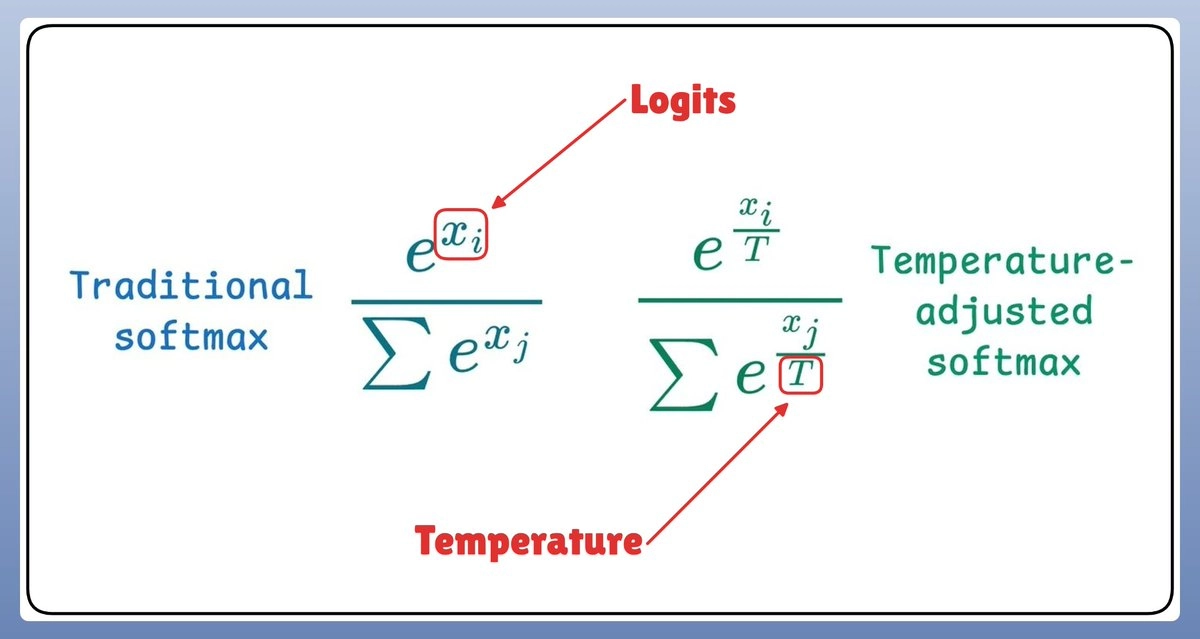
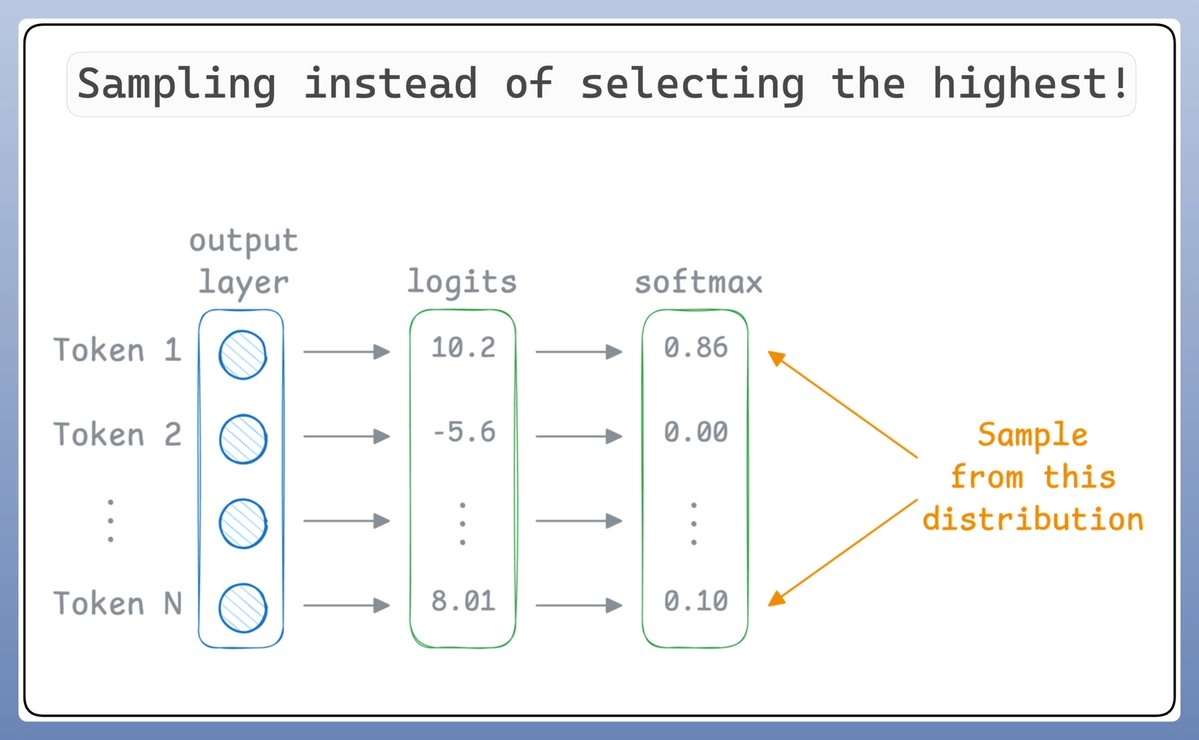 温度值(T)在这个过程中,会对概率分布进行调整,影响抽样的结果:
温度值(T)在这个过程中,会对概率分布进行调整,影响抽样的结果:
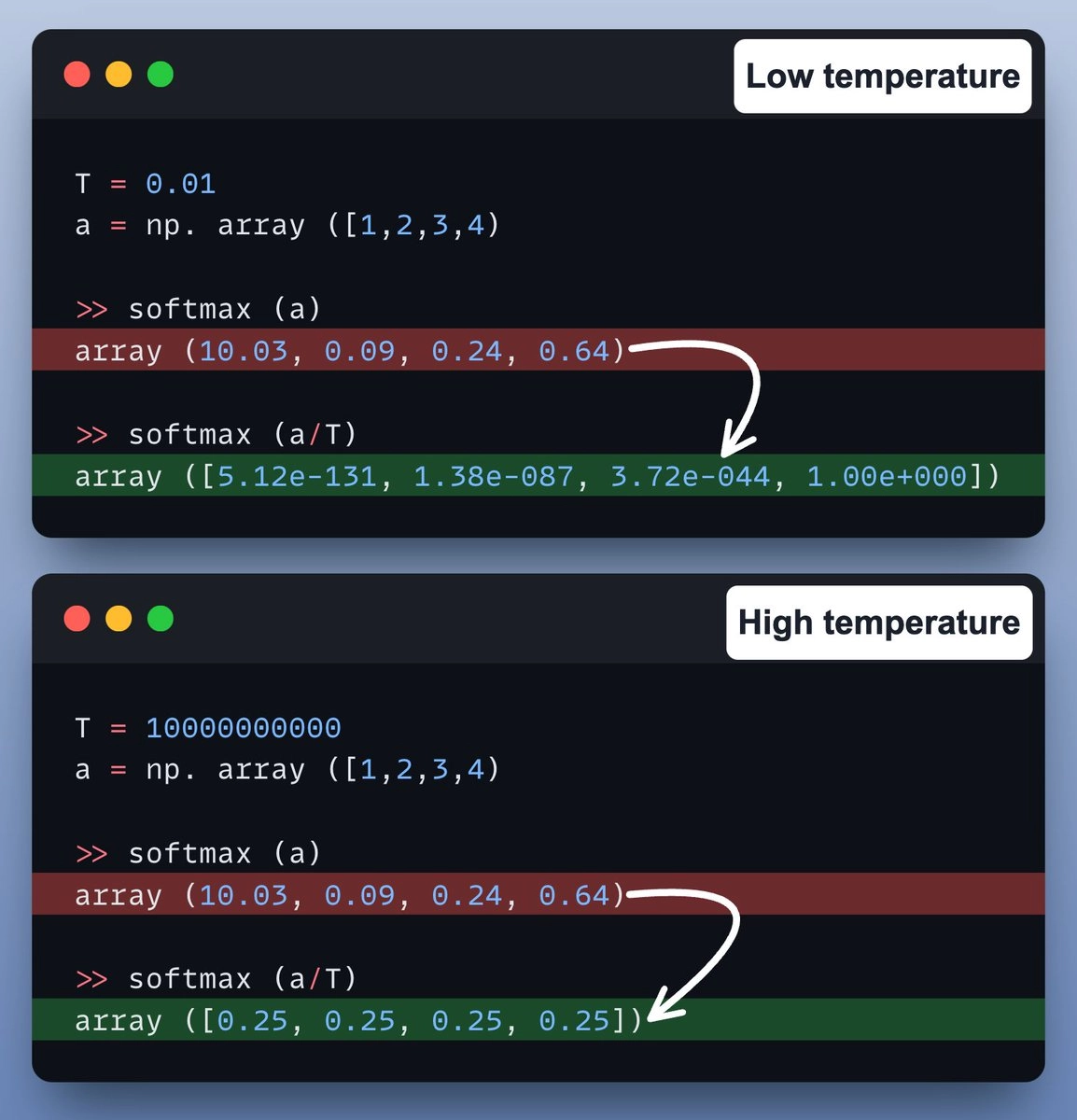
 我们再通过一段代码示例来更直观地理解:
我们再通过一段代码示例来更直观地理解:
- 当温度较低时,概率集中在最可能的单词附近,输出更倾向于确定的结果(几乎是“贪心”的)。
- 当温度较高时,概率变得更加均匀,输出的结果也更加随机和多样化。
看下面的示例代码图就更清楚了👇:
总结一下:
- LLM本质上是学习单词序列的条件概率。
- 每次预测下一个单词时,会根据已出现的上下文计算条件概率。
- 使用温度(Temperature)是为了控制生成结果的多样性和创造性。
如果你觉得这篇讲解对你有帮助,欢迎分享给更多人!