测量2025年初AI工具对资深开源开发者生产力的影响
我们进行了一项随机对照试验(RCT),研究2025年初的AI工具如何影响资深开源开发者在处理自己代码库时的生产效率。令人惊讶的是,我们发现开发者在使用AI工具时,完成任务的时间比不使用时延长了19%。换句话说,AI不仅没提高效率,反而拖慢了开发速度。
我们将此结果视作对2025年初AI技术水平的一个真实快照。考虑到AI技术仍在快速进步,我们未来还会继续使用类似方法监测AI工具对研发效率的影响【1】。
完整论文请查看这里。
为什么做这个研究?
当前,衡量AI能力多依赖于各种标准化评测(benchmarks)【2】,但这些评测通常为了方便、规模化,而牺牲了真实性。具体来说:
- 任务通常是独立且无需上下文的;
- 算法式评分忽视了现实中的许多重要能力。
这样的设定可能会让我们高估或低估AI在真实场景中的能力。我们希望通过真实环境下的评估,更准确地了解AI工具对研发的实际影响,尤其关注AI对自身研发速度的影响,因为过快的AI发展可能带来监管和安全方面的风险。
研究方法
我们邀请了16名经验丰富的开源开发者参与实验,他们均长期贡献于知名的开源项目(GitHub星数超过2.2万,代码行数超过百万)。开发者提供了246个真实的任务(如修bug、开发功能等),然后随机分配这些任务,允许或禁止使用AI工具完成。
- 允许使用AI时,开发者可自由选择工具(主要为Cursor Pro,搭载Claude 3.5/3.7 Sonnet等前沿大语言模型);
- 禁止使用AI时,开发者必须独立完成任务。
每个任务约耗时2小时,开发者会录屏并报告实际耗费的时间,我们以每小时150美元的报酬支付参与实验的开发者。

核心结果
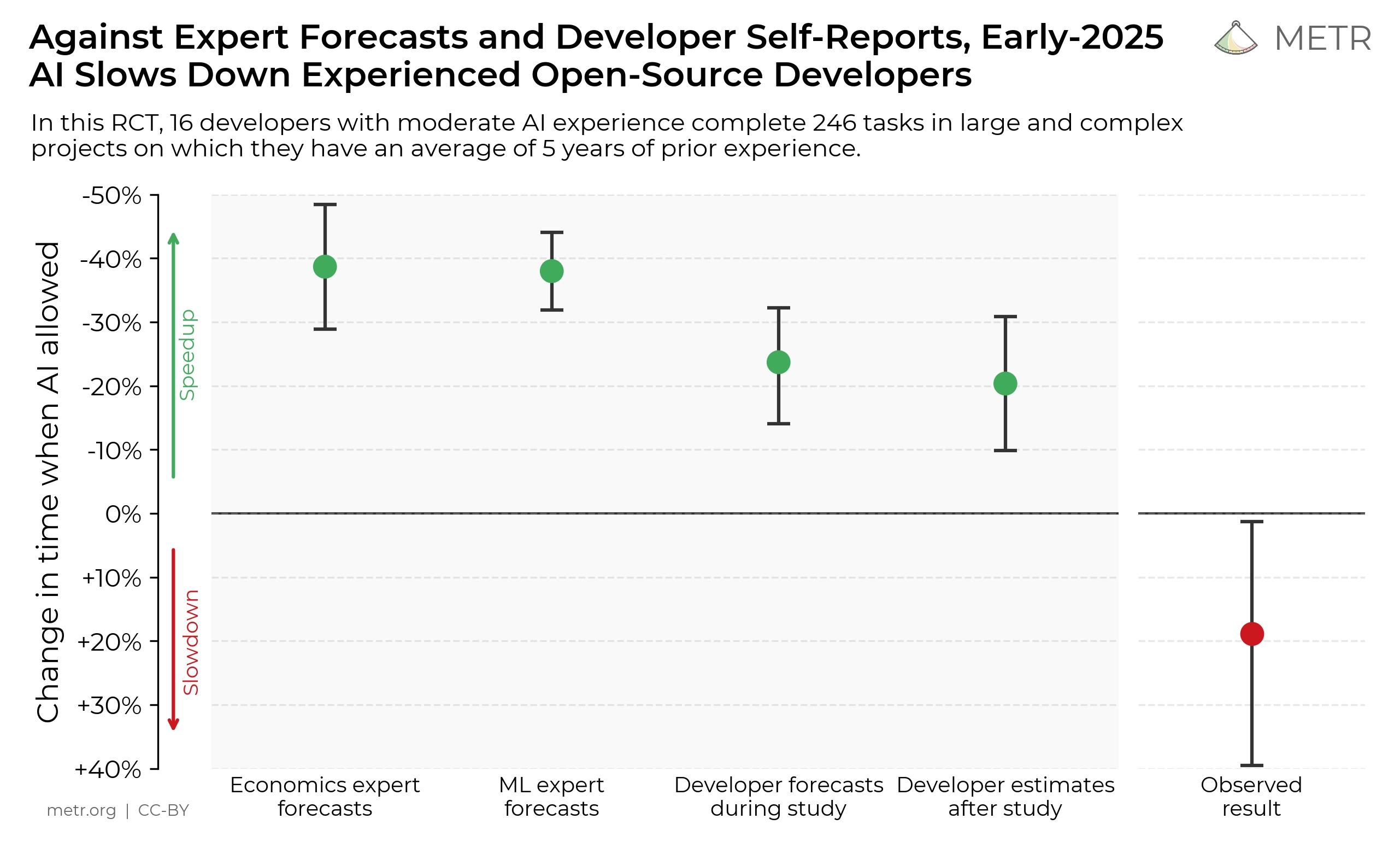
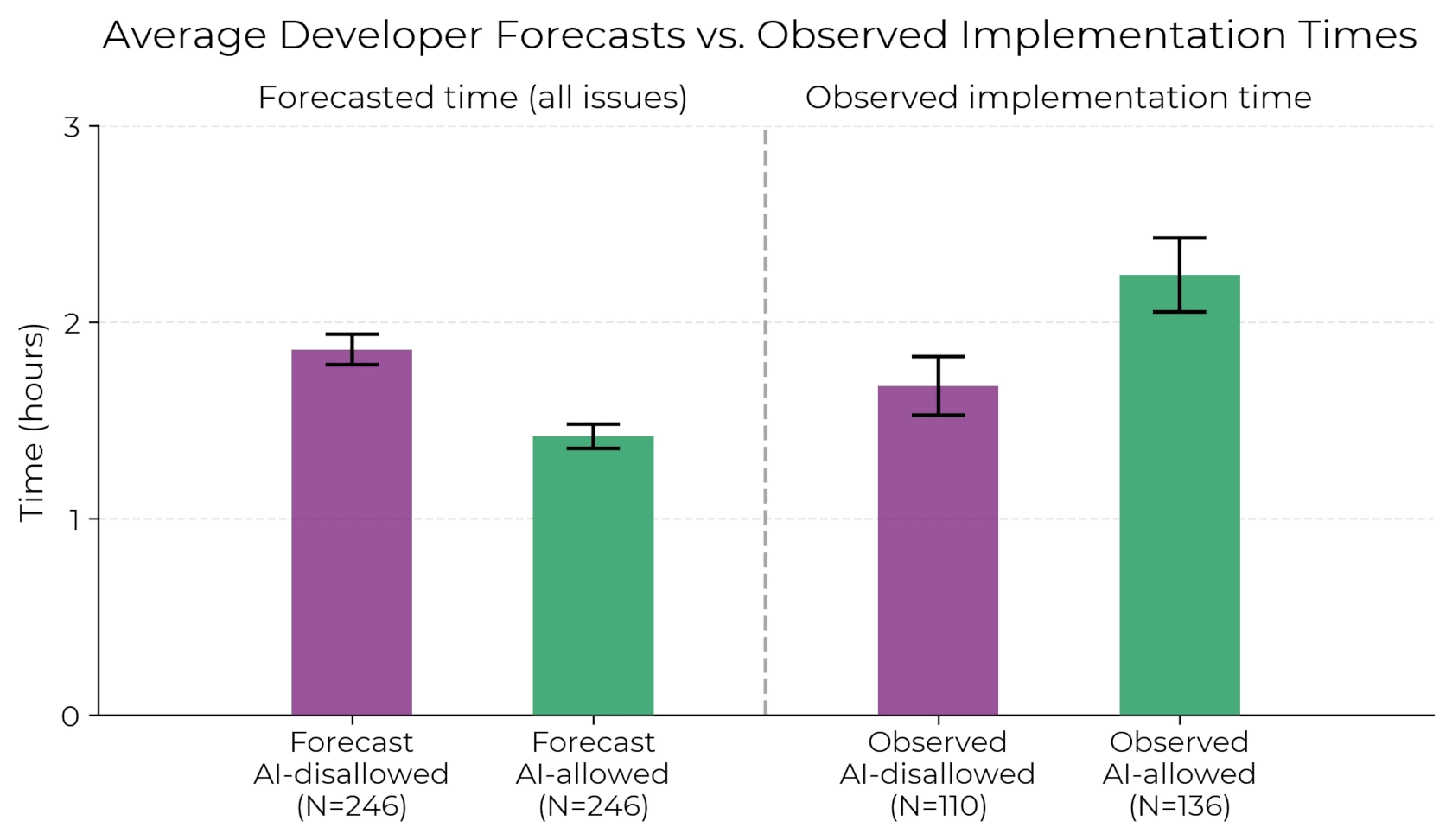
在允许使用AI工具的情况下,开发者完成任务所需时间增加了19%,这一结果与开发者的预期完全相反:
- 开发者原本认为AI工具可以让他们的效率提高24%;
- 即使经历了效率下降后,他们仍认为自己效率提高了20%。
下图清晰展示了开发者的预期时间与实际完成时间对比,明显可见使用AI工具时任务耗时更长:
 鉴于人们可能会过度概括或误解结果,我们特别澄清了以下几点本研究未提供的证据:
鉴于人们可能会过度概括或误解结果,我们特别澄清了以下几点本研究未提供的证据:
我们未提供以下证据
澄清说明
AI工具当前不会加速大多数开发者的工作
我们的研究并不能代表大多数开发者的工作场景
AI工具在其他领域不能提升效率
我们只研究了软件开发领域
近期AI工具在类似情境下也无法提速
AI发展迅速,未来情境可能有所不同
当前没有更有效的使用AI工具的方法
我们使用的工具可能并未达到最优状态,未来可能存在更高效的使用方法
因素分析
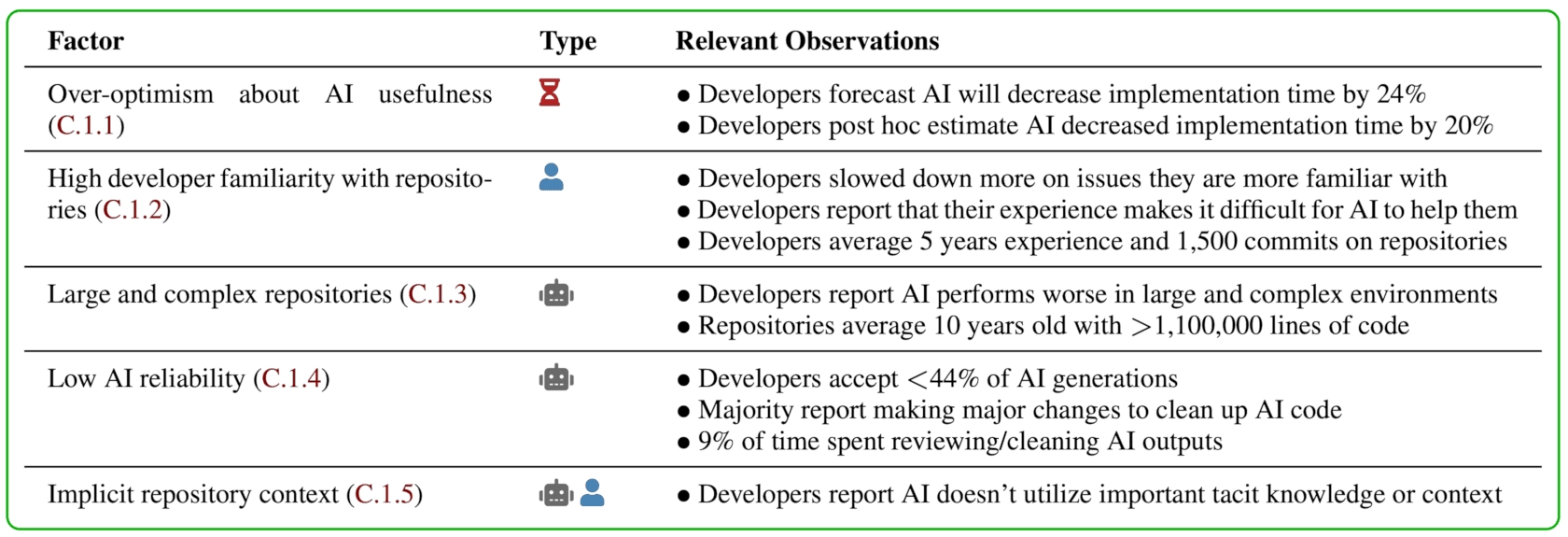
我们分析了可能导致减速的20个因素,发现有5个因素较为明显地导致了减速:
减速原因分析
因素
类型
相关观察
对AI工具过于乐观(C.1.1)
⏳
- 开发者原本预期使用AI后任务耗时将减少24%。- 即使亲身体会到了AI导致任务时间增加,他们事后仍估计AI节省了20%的时间。
开发者对代码库过于熟悉(C.1.2)
👤
- 开发者在自己更熟悉的任务上,被AI拖慢的情况更明显。- 开发者表示,丰富的个人经验使得AI很难有效地提供帮助。- 参与者平均有5年经验,且在相关代码库的贡献平均达到1500次提交。
大型复杂代码库(C.1.3)
🤖
- 开发者报告称,在大型复杂环境中AI表现更差。- 所选代码库平均已有10年历史,代码规模超过110万行。
AI生成结果可靠性低(C.1.4)
🤖
- 开发者接受的AI生成代码不足44%。- 大多数开发者表示需要对AI生成的代码做重大修改。- 大约9%的工作时间花费在审阅和修改AI生成的代码上。
隐含的代码库上下文(C.1.5)
👤🤖
- 开发者表示AI无法有效利用隐含的知识或代码库上下文信息。
我们排除了许多实验干扰因素,如模型选择、任务难度和质量差异等。更多细节请参阅论文原文。
结果讨论
如何解释AI工具在实际开发中表现不佳,而在标准评测及大众使用中却表现出色?
以下表格比较了几种证据来源的差异:
本次RCT实验
标准化评测(如SWE-Bench Verified)
大众普遍使用的反馈
任务类型
真实大型开源代码库中的问题修复和功能实现
独立、明确且易自动化评分的任务
多样化、范围广泛
成功标准
代码能满足真实审查需求(风格、文档、测试等)
算法自动评分
人类用户认为代码“有用”即可
AI形式
聊天、Cursor智能模式、自动补全
通常为全自动化的AI智能体
各种不同AI模型与工具
观察结果
在真实任务(约20分钟至4小时)中,AI让人类开发者变慢
AI在难度极高的标准任务中表现出色
很多人反馈AI对长时间任务(>1小时)非常有用
针对这些矛盾的现象,我们提出了三种可能的解释假设:
假设
简单说明
假设1: RCT低估了AI能力
实验方法或情境本身存在未知的问题
假设2: 标准评测和大众反馈高估了AI能力
标准评测和大众反馈存在偏差,夸大AI真实能力
假设3: 不同方法衡量了不同情境
三种评估方法各自准确,但针对的任务场景差异明显
未来展望
我们将继续开展类似的实验,以便长期监测AI对研发效率的影响。这种现实环境下的评估,有望避免标准评测容易“刷分”的缺陷。
如果未来AI明显提高开发者效率,这可能预示着AI研发能力的快速提升,同时也带来了监管、安全、权力集中等潜在风险。
我们欢迎更多开源开发者或企业合作,共同了解AI工具对实际工作效率的影响,有兴趣参与研究的伙伴请联系我们。