在人工智能领域,训练大型语言模型(LLMs)已成为推动技术进步的重要方向。然而,随着模型规模和数据集的不断扩大,传统的优化方法 —— 特别是 AdamW—— 逐渐显露出其局限性。研究人员面临着计算成本高、训练不稳定等一系列挑战,包括梯度消失或爆炸、参数矩阵更新不一致及分布式环境下的资源需求高等问题。因此,迫切需要更高效、更稳定的优化技术来应对这些复杂性。
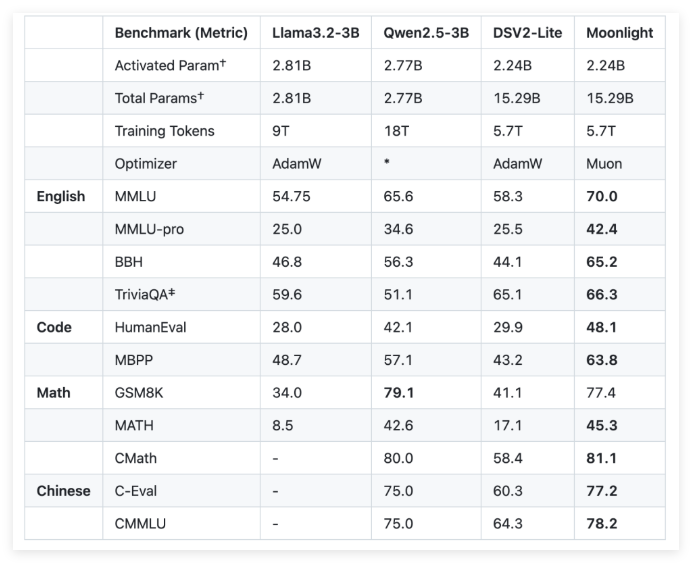
为了解决这些挑战,Moonshot AI (月之暗面)与加州大学洛杉矶分校(UCLA)联合开发了 Moonlight,一个使用 Muon 优化器的 Mixture-of-Expert(MoE)模型。Moonlight 提供两种配置:一种是激活参数为30亿,另一种为总参数为160亿,训练使用了5.7万亿个标记。Muon 优化器的创新在于利用牛顿 - 舒尔茨迭代法进行矩阵正交化,确保梯度更新在模型参数空间中的均匀性。这种改进为传统的 AdamW 提供了一个有前景的替代方案,提高了训练效率和稳定性。
在技术细节上,Moonlight 对 Muon 优化器进行了两项关键调整。首先,引入了权重衰减技术,以控制大模型和大量标记训练时权重的增长。其次,针对每个参数的更新幅度进行了校准,使其根据权重矩阵的最大维度的平方根进行缩放,从而实现更新的一致性。
通过对 Moonlight 的实证评估,研究人员发现其在中间检查点的表现优于传统的 AdamW 训练模型。例如,在语言理解任务中,Moonlight 在 MMLU 基准测试上获得了更高的分数。在代码生成任务中,性能提升更加明显,表明 Muon 的优化机制对任务表现有积极贡献。
Moonlight 项目的成功实施将为大型语言模型的训练带来新的标准。Muon 优化器的开源实现以及预训练模型和中间检查点的发布,预期将促进对可扩展优化技术的进一步研究。
github:https://github.com/MoonshotAI/Moonlight?tab=readme-ov-file
huggingface:https://huggingface.co/moonshotai/Moonlight-16B-A3B
论文:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
划重点:
🌟 Moonlight 模型是由 Moonshot AI 与 UCLA 联合开发的 Mixture-of-Expert 模型,提供30亿和160亿参数配置,训练使用5.7万亿个标记。
⚙️ Muon 优化器通过牛顿 - 舒尔茨迭代法和权重衰减技术,显著提高了大型模型训练的效率和稳定性。
📈 实证结果显示,Moonlight 在多个任务上优于传统的 AdamW 训练模型,表现出更好的语言理解和代码生成能力。