近日,Meta AI 团队推出了视频联合嵌入预测架构(V-JEPA)模型,这一创新举措旨在推动机器智能的发展。人类能够自然而然地处理来自视觉信号的信息,进而识别周围的物体和运动模式。机器学习的一个重要目标是揭示促使人类进行无监督学习的基本原理。研究人员提出了一个关键假设 —— 预测特征原则,认为连续感官输入的表示应该能够相互预测。
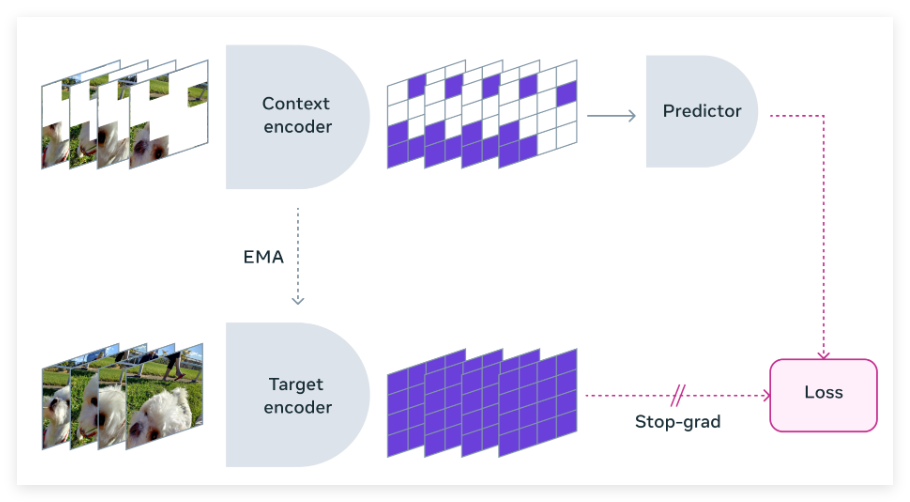
早期的研究方法通过慢特征分析和谱技术来保持时间一致性,防止表示崩溃。而现在的许多新方法则结合了对比学习和掩蔽建模,确保表示能够在时间上不断演变。现代技术不仅专注于时间不变性,还通过训练预测网络来映射不同时间步的特征关系,从而提升了表现。针对视频数据,时空掩蔽的应用进一步提高了学习表示的质量。
Meta 的研究团队与多所知名机构合作,开发了 V-JEPA 模型。这一模型以特征预测为核心,专注于无监督的视频学习,与传统方法不同的是,它不依赖于预训练编码器、负样本、重建或文本监督。V-JEPA 在训练过程中使用了两百万个公共视频,并在运动和外观任务上取得了显著的表现,且无需微调。
V-JEPA 的训练方法是通过视频数据构建对象中心的学习模型。首先,神经网络从视频帧中提取对象中心的表示,捕捉运动和外观特征。这些表示通过对比学习得到进一步增强,以提升对象的可分性。接下来,基于变压器的架构处理这些表示,以模拟对象之间的时间交互。整个框架经过大规模数据集的训练,以优化重建准确性和跨帧一致性。
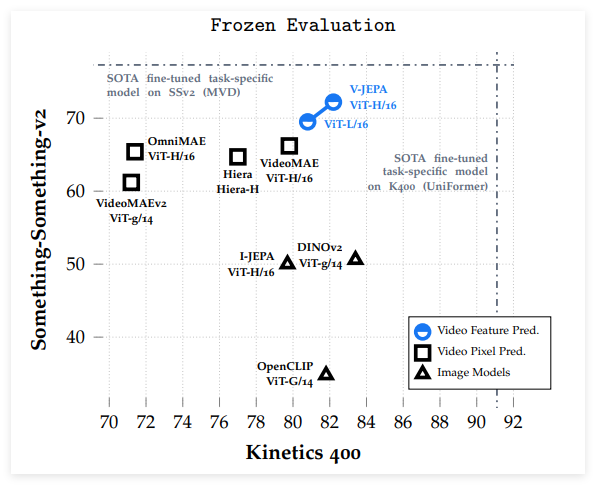
V-JEPA 在与像素预测方法的比较中表现优越,特别是在冻结评估中,除了在 ImageNet 分类任务中稍显不足。经过微调后,V-JEPA 在使用更少的训练样本的情况下,超越了基于 ViT-L/16模型的其他方法。V-JEPA 在运动理解和视频任务上表现出色,训练效率更高,且在低样本设置下仍然能够保持准确性。
这项研究展示了特征预测作为无监督视频学习独立目标的有效性,V-JEPA 在各类图像和视频任务中表现出色,并且在无需参数适应的情况下超越了以往的视频表示方法。V-JEPA 在捕捉细微运动细节方面具有优势,显示出其在视频理解中的潜力。
论文:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
博客:https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
划重点:
📽️ V-JEPA 模型是 Meta AI 推出的一种新型视频学习模型,专注于无监督的特征预测。
🔍 该模型不依赖于传统的预训练编码器和文本监督,直接从视频数据中学习。
⚡ V-JEPA 在视频任务和低样本学习中表现出色,显示出其高效的训练能力和强大的表示能力。