OpenAI近日发布了一项重要的AI编程能力评估报告,通过价值100万美元的实际开发项目揭示了AI在软件开发领域的现状。这项名为SWE-Lancer的基准测试涵盖了1,400个来自Upwork的真实项目,全面评估AI在直接开发和项目管理两大领域的表现。
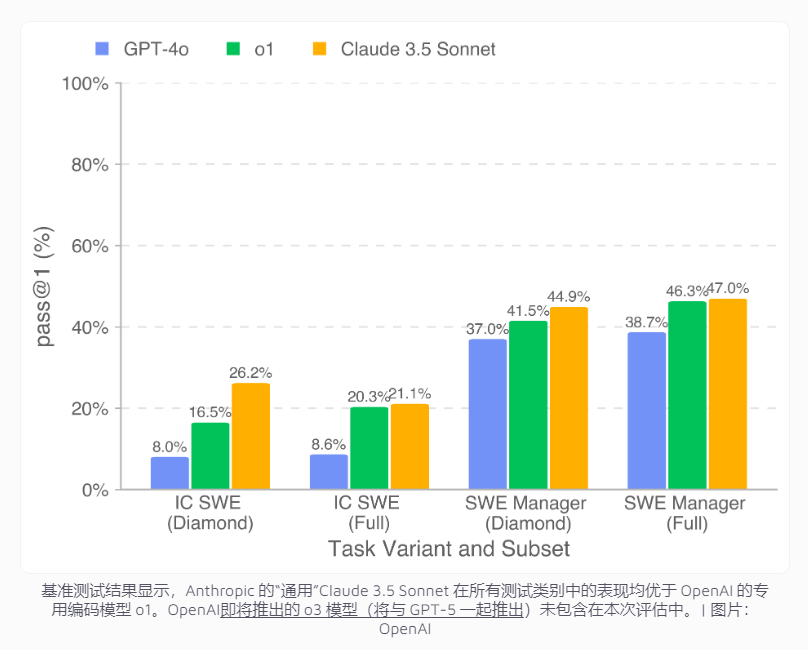
测试结果显示,表现最佳的AI模型Claude3.5Sonnet在编码任务中的成功率为26.2%,在项目管理决策方面达到44.9%。虽然这一成绩与人类开发者仍有差距,但在经济效益方面已展现出可观潜力。
数据显示,仅在公开的Diamond数据集中,该模型就能完成价值208,050美元的项目开发工作。如果扩展到完整数据集,AI有望处理价值超过40万美元的任务。
然而,研究也揭示了AI在复杂开发任务中的明显局限。虽然AI能够胜任简单的错误修复工作(如修复冗余API调用),但在面对需要深入理解和全面解决方案的复杂项目时(如跨平台视频播放功能开发)表现欠佳。特别值得注意的是,AI往往能识别问题代码,却难以理解根本原因并提供全面的解决方案。
为推动该领域研究发展,OpenAI已在GitHub上开源了SWE-Lancer Diamond数据集和相关工具,使研究者能够基于统一标准评估各类编程模型的性能。这一举措将为AI编程能力的进一步提升提供重要参考。