我们知道:
- 人类的 DNA 就像一个巨大的说明书。
- 其中有些地方“编码”蛋白质,但其实 98% 是“非编码区域”,这些区域负责控制基因何时、在什么细胞中表达。
- 这些区域的功能难以预测,小小的变异可能对健康有很大影响(比如某些癌症或罕见病)。
AlphaGenome 是一种新型 AI 模型,旨在更准确、全面地预测单个 DNA 变异对基因调控过程的影响,尤其关注非编码区(占基因组98%)的调控功能。
它能更精准地揭示这些非编码区域的功能和它们在不同细胞中的表现,以及变异可能带来的后果。

你可以想象它像一个 “基因调控雷达”,能扫描百万级别的DNA序列,告诉你:
- 某个突变会不会让一个癌症基因被意外激活?
- 哪个剪接点可能被破坏,导致基因“拼错”?
- 哪段序列适合“定制”用在神经细胞里使用?
与以往模型相比,AlphaGenome 在 DNA 序列长度、预测分辨率和多模态建模能力上实现了重大突破。它构建了一个统一框架,可用于研究基因表达、剪接、蛋白结合位点等调控机制。
它能做什么?
AlphaGenome 可以:
✅ 1. 输入超长 DNA 序列
- 可分析 长达100万个碱基(DNA字母) 的序列 —— 比以往模型处理得更远、更全面。
✅ 2. 预测数千个调控特性
包括:
- 哪些位置可能是基因起点或终点;
- 哪些区域会参与 RNA 剪接(重要生物过程);
- 哪些 DNA 区域对某些蛋白质有吸引力;
- 不同细胞类型中 RNA 表达的活跃程度。
✅ 3. 快速评估变异影响
- 比较突变前后的序列预测结果;
- 能判断这个变异可能会不会导致疾病、影响基因表达或破坏调控功能。
✅ 4. 覆盖剪接突变预测
- 这是一个重要突破,尤其在理解 罕见遗传病 中非常有用,比如脊髓性肌萎缩症等。
技术原理:它是怎么实现的?
技术架构
- 卷积层:检测短序列模式(如DNA的motif)
- Transformer:在超长序列中建立全局信息流动
- 高效训练:使用TPU集群,仅需4小时,计算资源为前作Enformer的一半
AlphaGenome 采用了多个 AI 领域的先进技术:
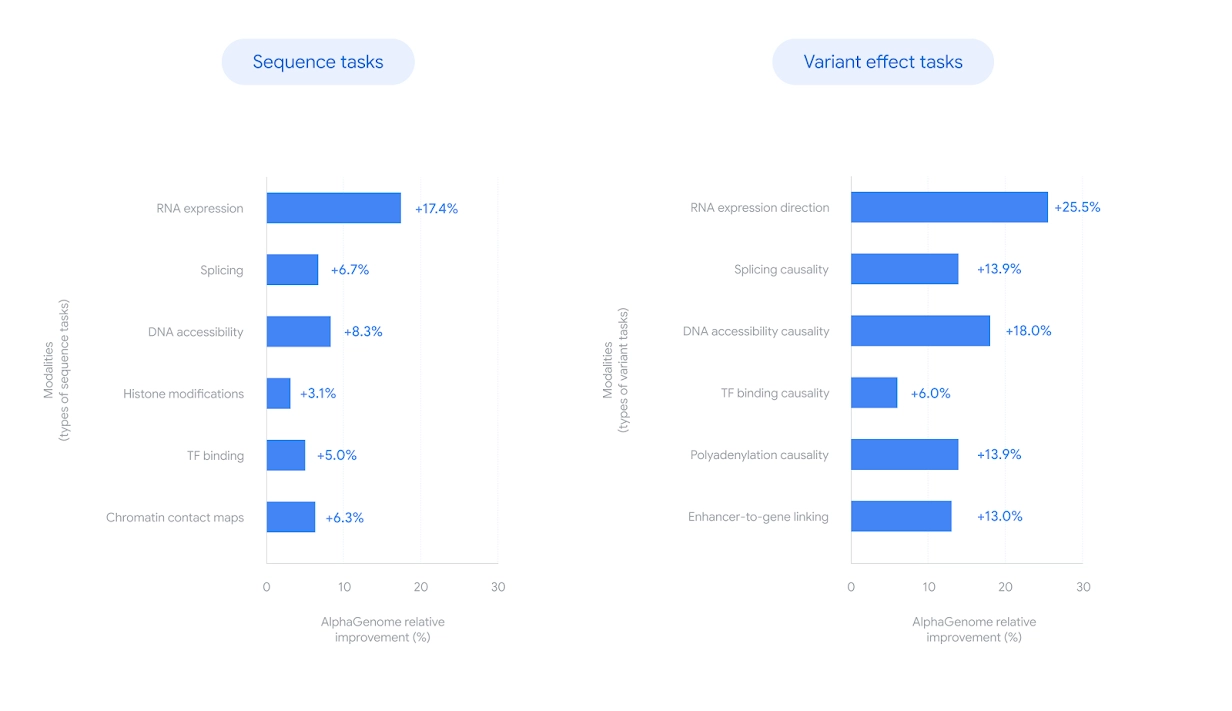
模型表现与验证
- 在24个DNA序列预测任务中,AlphaGenome超越当前最优模型22项;
- 在26个变异效应预测任务中,匹配或超过现有最佳模型24项;
- 为首个可统一建模所有预测模态的模型;
支持 API调用,为科学家提供跨模态一体化预测能力。
实际应用场景
AlphaGenome 并不是一个只停留在理论层面的工具,它具备很强的应用价值:
🔬 1. 疾病机制研究
- 可用于揭示哪些突变会影响基因表达,从而可能导致癌症或罕见遗传病。
- 官方展示:预测出 T-ALL 白血病患者中的特定突变会激活 TAL1 癌基因,模拟已知机制。
🧫 2. 合成生物学
- 帮助设计具有特定功能的 DNA 元件(如只在神经细胞中启动的启动子)。
🧠 3. 基因功能图谱构建
- 协助科学家系统性地绘制不同细胞中基因调控机制全图。
为什么它是突破性的?
它解决了多个关键限制:

AlphaGenome 在 24 个预测任务中有 22 个超越当前最佳模型,在变异效应预测上也表现突出。
局限与未来发展
尽管进步明显,但 AlphaGenome 并非“万能”:
- 📏 对于 超远距离调控(>100kb)仍有难度;
- 🧫 某些 组织特异性预测能力 仍在改进;
- ❌ 不适用于个人临床基因预测;
- 🌱 复杂表型(如环境或多基因互作)仍需结合其他工具分析。
未来,DeepMind 计划扩大训练数据、支持更多物种和功能模态,并逐步开放完整模型。
目前,AlphaGenome 通过 API 提供给全球科研人员非商业用途使用。研究者可以:
- 在不同生物学项目中测试变异;
- 快速提出并验证机制假设;
- 构建属于自己的下游模型或任务;
官方介绍:https://deepmind.google/discover/blog/alphagenome-ai-for-better-understanding-the-genome/