Qwen VLo 是一个统一的多模态大模型(Unified Multimodal Model),能够既理解图像,又能生成、编辑图像,并通过自然语言指令灵活控制整个过程。
它不仅能“看懂”图像内容,还能根据理解进行精细的修改或全新创作,实现从 视觉感知到视觉生成 的闭环。
目前为预览版本,可通过 Qwen Chat 使用。
核心能力
1️⃣ 精准图像理解与内容重构
- 能准确识别图像中的物体类别、结构特征、风格风貌。
- 在进行图像修改时(如更换颜色、风格迁移),能保留原图重要结构,避免“变形”或“失真”。
举例:
用户上传一张汽车照片,说“把颜色换成蓝色”。
传统模型可能改变了轮廓或品牌识别失败;Qwen VLo 不仅识别出车型,还保留车体结构,仅自然改变颜色。
2️⃣ 开放式语言控制的图像编辑
Qwen VLo 支持用户用自然语言自由表达创作意图,比如:
- “把这张照片改成 19 世纪油画风格”
- “让天空变得晴朗”
- “让人物背景变成城市夜景”
👉 这些命令不需要固定格式,模型可灵活理解,并精准完成修改。
它还可执行组合操作,如:
- 同时修改背景 + 风格 + 添加对象;
- 实现图像风格迁移、场景重建、插画细节补全等多种用途。
3️⃣ 多语言支持,跨语言交互无障碍
Qwen VLo 支持 中文、英文 等多语言指令输入,用户可直接用母语与系统交互,大幅提升使用体验。
4️⃣ 支持感知类任务(视觉理解任务)
不仅能生成图像,Qwen VLo 还能处理传统 CV(计算机视觉)任务:

这些功能使得模型具备“像人一样分析图像”的基础能力,并可用于下游视觉任务。
Qwen VLo 在生成图像时,不是一下子生成整张图,而是像画画或打印一样,按顺序从图像的左上角开始,一块一块地往右、往下逐步生成内容,直到完成整幅图。
这种方式的优点:
- 更容易控制细节和整体一致性;
- 支持长图、复杂排版;
- 更接近人类绘画的逻辑。
简单理解:它是**“边理解边绘制”**,而不是“全部生成后再修图”。
演示与能力展示
✅ 图像生成与创作
Qwen VLo 能够直接生成图像,并对其进行修改,例如替换背景、添加主体、进行风格迁移,甚至可以完成基于开放指令的大幅修改,包括检测和分割等视觉感知任务。
- 支持输入纯文本(如:“画一个可爱的柴犬”)→ 生成图像
- 支持上传图片并修改(如:“给它戴顶帽子”)→ 编辑图像
使用逐步生成机制(从左至右、从上至下)提高细节稳定性
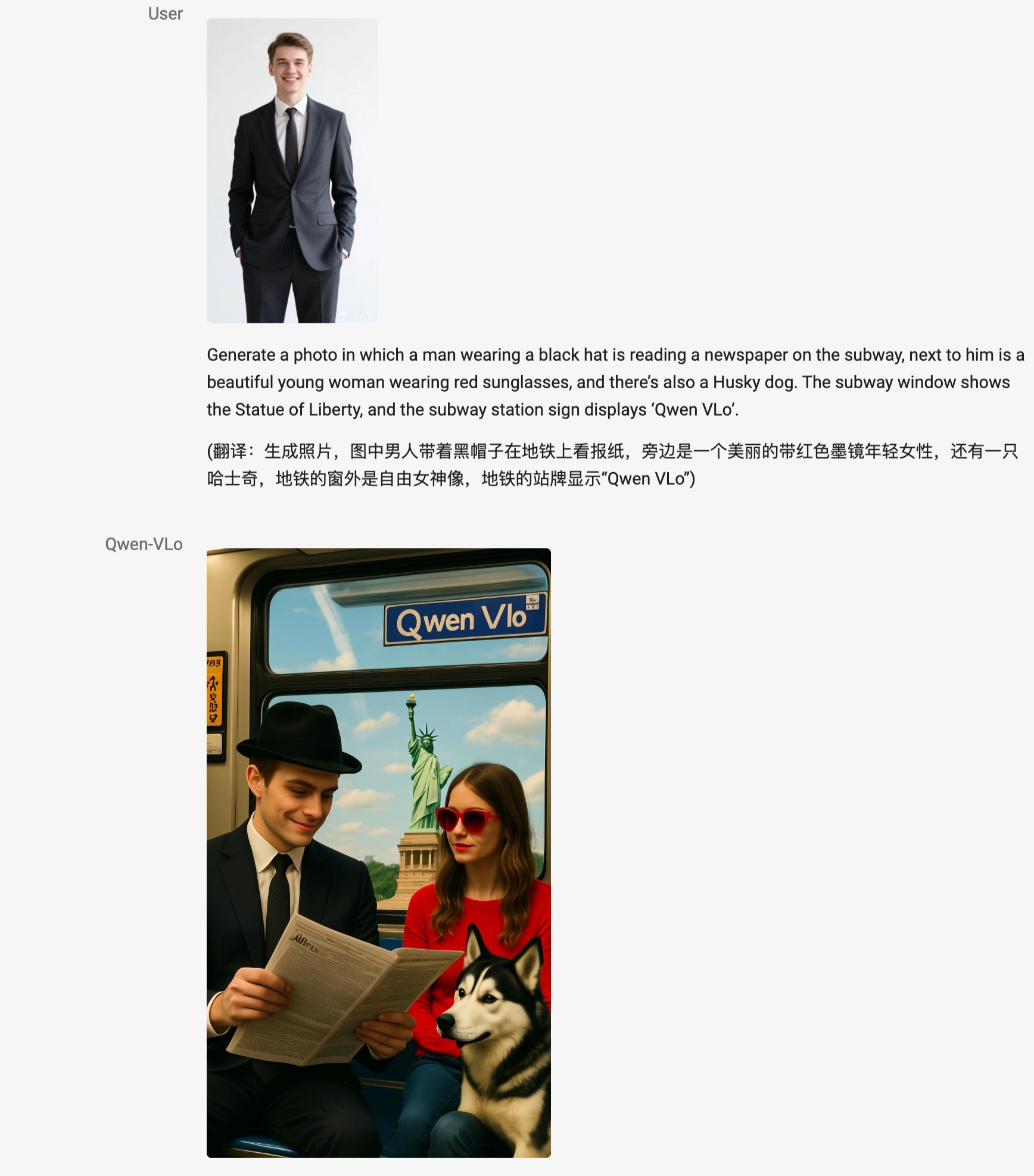
✅ 多步复杂指令响应
支持多操作组合,如“做成复古风格、换背景、添加文字”,一次完成。
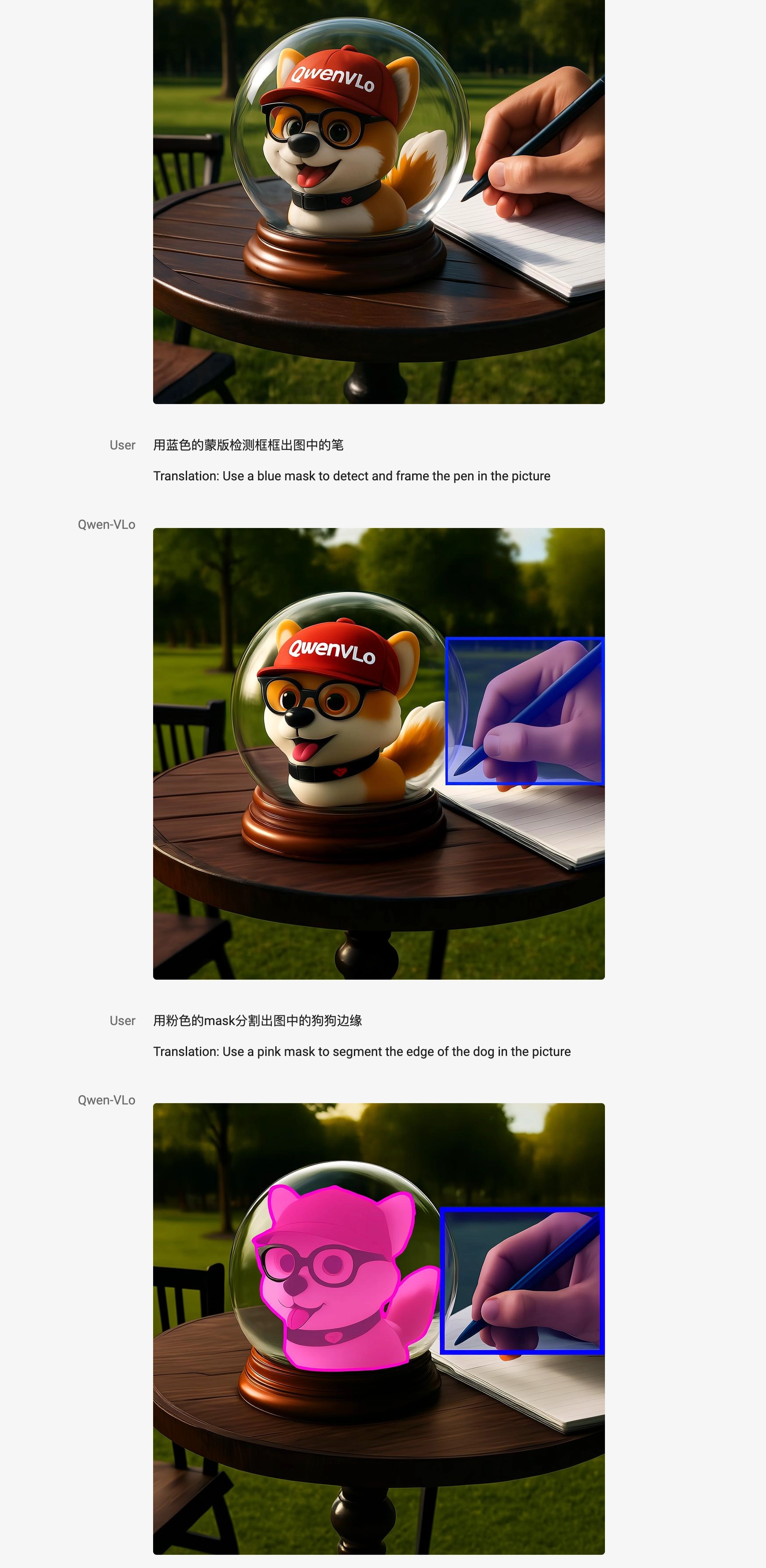
✅ 感知与理解任务
可生成检测框、分割图、边缘图等视觉感知中间结果;

可以支持多张图像的输入理解和生成。(多图输入的功能还没有正式上线,敬请期待。)

与旧版本(VL Plus / VL Max)相比的关键升级
