Ben Hylak对OpenAI 最新 o3 pro模型的的独家评测
o3 Pro 的定位:任务级超级推理助手
任务导向模型(Task-specific models):
- 和日常聊天型模型(如 GPT-3.5、GPT-4o)不同;
o3 Pro 被设计为:
✅ 面向复杂任务、深度分析
✅ 高度理性、冷静、非对话型
✅ 更像一个“执行型分析官”或“战略规划师”
评测方式:与传统 benchmark 无法评估的能力
作者评测策略:
- 不用对话测试;
- 构建“真实业务场景”+“完整上下文”;
- 观察其解决复杂任务的能力和具体执行建议输出质量。
🌟 评测示例:公司战略规划任务
作者将公司 Raindrop 的:
- 所有规划会议记录;
- 长期/短期目标;
- 语音备忘录;
- 团队历史内容 > 统一喂给 o3 Pro,提出:“请给出下一阶段业务战略计划”。
输出结果:
o3 Pro 给出了:
- 精确的目标指标(target metrics);
- 明确时间线(timelines);
- 严格优先级(prioritization);
- 建议删除的项目(cut list);
- 输出质量之高,促使团队改变了战略方向。
o3 Pro 的关键优势总结
1. 🧠 智力水平极高,但需要**“喂饱上下文”**才显现
- 不适合用简短 prompt 测试;
- 需要“大量背景+明确目标”才能发挥性能;
- 未必适合 casual 聊天。
2. 🧩 极强的环境感知与工具交互能力
- 能判断自己是否需要调用外部工具;
- 不会编造访问不到的信息,而是明确提示需要“你告诉它”;
- 非常擅长调度工作、使用外部函数、API、数据库等资源。
3. 🔄 系统提示与上下文极度重要
- system prompt 对其行为影响深远;
- 比如“你是一名产品经理”vs“你是一位安全专家”,将产生截然不同的风格与策略。
4. ⚠️ 潜在弱点:低上下文时容易过度分析
- 给出不充分的上下文会导致“思维过重”,容易陷入推理死胡同;
- 对“直接行动型”任务(如 SQL 查询)可能不如基础模型灵活。
模型对比:与同类模型的不同

OpenAI 正在走的“垂直强化学习”路径
- OpenAI 不仅教模型“如何调用工具”,还教它“何时调用工具”;
- 推进 LLM 像人类一样判断工具使用时机,是通用人工智能的关键路线之一;
- o3 Pro 是这一策略的产物。
使用建议与最佳实践(Prompt Engineering)
✅ 使用提示建议:
给足上下文(context is king):
- 相关文档、目标、角色描述都应写入提示;
- 可类比“喂给 cookie monster 饼干”。
明确目标:
- 不要说“帮我写点内容”,而要说“基于以下数据,写一份三阶段产品上线策略”。
强化系统提示:
- 系统提示中的角色设定、任务说明对模型的“行为风格”影响极大。
总结一句话
o3 Pro 并不是你“聊天”的朋友,它是你公司里那个不会说废话的高级战略分析师。
以下是文章 《God is hungry for Context: First thoughts on o3 pro》 的全文中文翻译:
上帝渴望上下文:对 o3 Pro 的初印象
作者:Ben Hylak
正如“泄露”所说,OpenAI 今天将 o3 的定价下调了 80%(从每百万 token 的 $10/$40 降至 $2/$8 —— 与 GPT-4.1 持平!!),为 o3-pro 的推出铺平道路($20/$80)。这支持了一个未经证实的社区理论,即“pro”变体是基础模型的 10 倍调用,并采用多数投票机制(该机制在 OpenAI 的论文和我们的《Chai》节目中都有提到)。
o3-pro 在人类测试中以 64% 胜率击败 o3,并在 4 项可靠性基准测试中略胜一筹。但正如 Sam Altman 所指出的,实际体验在你用“不同方式”测试它时才会真正显现……
过去一周我获得了 o3 pro 的早期使用权。以下是我的一些(早期)想法:

这是任务特定模型的时代。
一方面,我们有像 GPT-3.5 Sonnet 和 GPT-4o 这样的“普通”模型 —— 像朋友一样交谈、帮助我们写作、回答日常问题。
另一方面,我们有那些庞大、缓慢、昂贵、智商爆表的推理模型,它们专精于深度分析、一次性解决复杂问题,以及探索纯智能的边界。
如果你关注我在 X(原推特),你会知道我与 o 系列推理模型的“历程”。我对 o1/o1-pro 的第一印象非常负面。但随着我咬牙坚持下去,受到他人好评的驱动,我意识到:我其实用错了方法。
我写下了所有感想,被 @sama 怼了,还被 @gdb 转发引用。
我发现的关键是:不要和它“聊天”。
要把它当作一个报告生成器:
给它足够的上下文,明确目标,然后让它自己输出结果。
这就是我现在使用 o3 的方式。
但这也引出了评估 o3 pro 的难题。
它更聪明,真的聪明得多。
但如果你不给它足够的上下文,它的强大之处就不会显现。
我没法问它一个简单的问题就被震撼到。
然后我换了种方法。
我和我的联合创始人 Alexis 花时间整理了我们在 Raindrop 的所有过往规划会议记录、目标,甚至是语音备忘录,然后让 o3-pro 拿这些信息来制定一个计划。
我们被震撼了。它生成了我一直希望 LLM 能输出的那种具体的计划与分析 —— 包括目标指标、时间表、优先事项,以及明确指出哪些该舍弃。
o3 给我们的计划是“合理的”。
但 o3 Pro 给出的计划不仅具体,而且根植于我们自身的背景,以至于它真正改变了我们对未来的思考方式。
这很难通过评测来体现。
试用 o3 Pro 让我意识到,如今的模型在“孤立状态”下表现已非常强,我们已经没有“简单测试”能完全评估它们。
真正的挑战是:将它们融入社会。
就像一个 IQ 很高的 12 岁孩子去上大学。聪明归聪明,但如果无法适应社会,也不是一个好员工。
如今的“融入”主要依靠工具调用:
- 模型与人类、外部数据、其他 AI 协作的能力;
- 它是一个优秀的“思想者”,但还需要成长为一个优秀的“执行者”。
o3 Pro 在这方面真的跃进了:
- 明显更擅长理解自身所处环境;
- 能准确表达自己拥有哪些工具;
- 知道何时询问外部世界的信息(而不是假装知道);
- 能选择合适的工具来完成任务。
o3 pro(左) vs o3(右):
左边的 o3 pro 显然在理解自己所处环境方面更强。
从早期使用来看:
如果你不给它足够上下文,它会有过度思考的倾向。
它擅长分析、擅长借助工具做事,但不太擅长直接动手做事。
我认为它是一个出色的“编排者”。
比如,有些 ClickHouse SQL 问题,o3 做得比 o3 Pro 更好。
结果可能因人而异。
o3 Pro 与 Opus、Gemini 2.5 Pro 的区别:
- Claude Opus 看起来“很强”,但从未让我看到它“强”的证据;
- o3 Pro 的输出更好,完全是另一种维度的表现。
OpenAI 正在深入推进“垂直强化学习”路径(如 Deep Research、Codex):
不仅教模型如何使用工具,更教它何时使用工具。
如何提示推理模型并没有变:
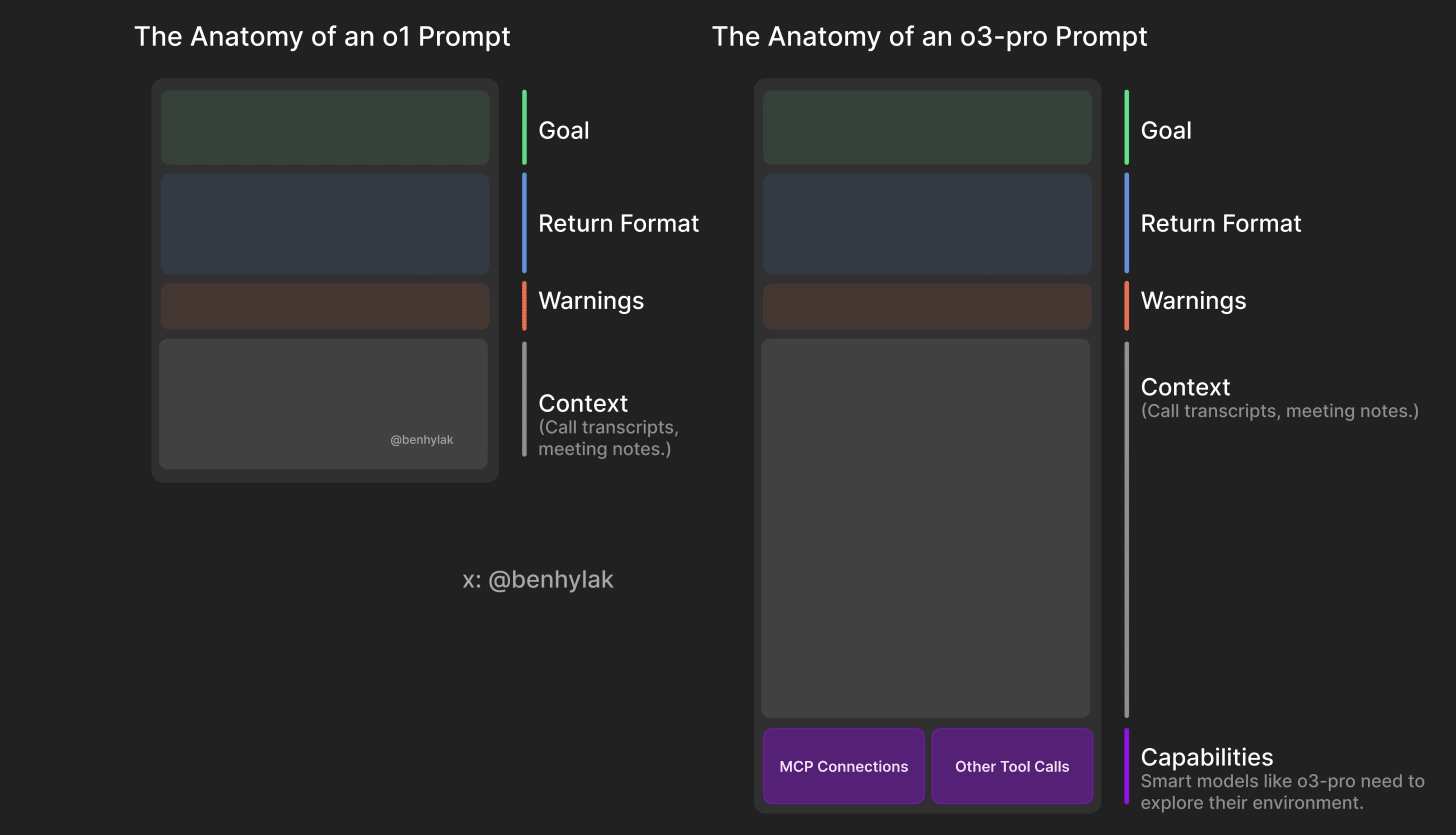
我的 o1 提示指南至今仍然适用。
上下文就是一切 —— 它就像给 Cookie Monster 喂饼干。
这是一种启动 LLM 记忆的方式,而且是有目标的,让它更有效。
系统提示(system prompt)也极为重要。
模型现在已经非常“可塑”,所以那些能教会模型其环境和目标的“提示框架”(harnesses)影响巨大。
正是这种“提示框架” —— 模型 + 工具 + 记忆 + 方法 —— 才让 AI 产品“好用”。
例如 Cursor 就是这种机制让它“大多数时间都能工作”。
其他零碎观察:
- 系统提示对模型行为的影响非常大(是积极的变化);
- o3 Pro 和 o3 相比,差异明显;
- 和 Claude、Gemini 相比更是天壤之别;
- OpenAI 的“工具增强推理”战略确实已经走在前面。