Enigma Labs 推出了 Multiverse,一个突破性的 AI 生成多人游戏,让玩家能实时共同构建和影响模拟世界。
该模型旨在解决现有世界模型只能模拟“单一主体”的局限,构建支持 多代理(multi-agent)在共享环境中感知、预测和交互的架构。
整个项目仅花费 $1.5K,却在架构、数据采集和模型设计上实现重大创新,并已完全开源。
- 多人互动:多个玩家可以同时进入这个由 AI 模拟的世界,并且每个人的行为都会实时影响这个世界。比如你加速、漂移、超车,都会让这个世界发生变化。
- 低成本高效果:他们只花了不到 1500 美元 就完成了训练和研发,能在普通 PC 上运行。秘诀不是用很多算力,而是技术创新。
- 完全开源:他们把整个项目都开放了,包括代码、数据、模型参数、架构、研究成果,让任何人都可以学习、使用或改进。
- 用途不限于游戏:这个“多人世界模型”的意义不仅仅是游戏,它还能应用在更广泛的模拟环境中,比如机器人训练、AI 协作等。
🏗️ 核心技术架构详解
🔹 单人世界模型的基本结构(Baseline)
传统单人世界模型通常由以下三个部分组成:
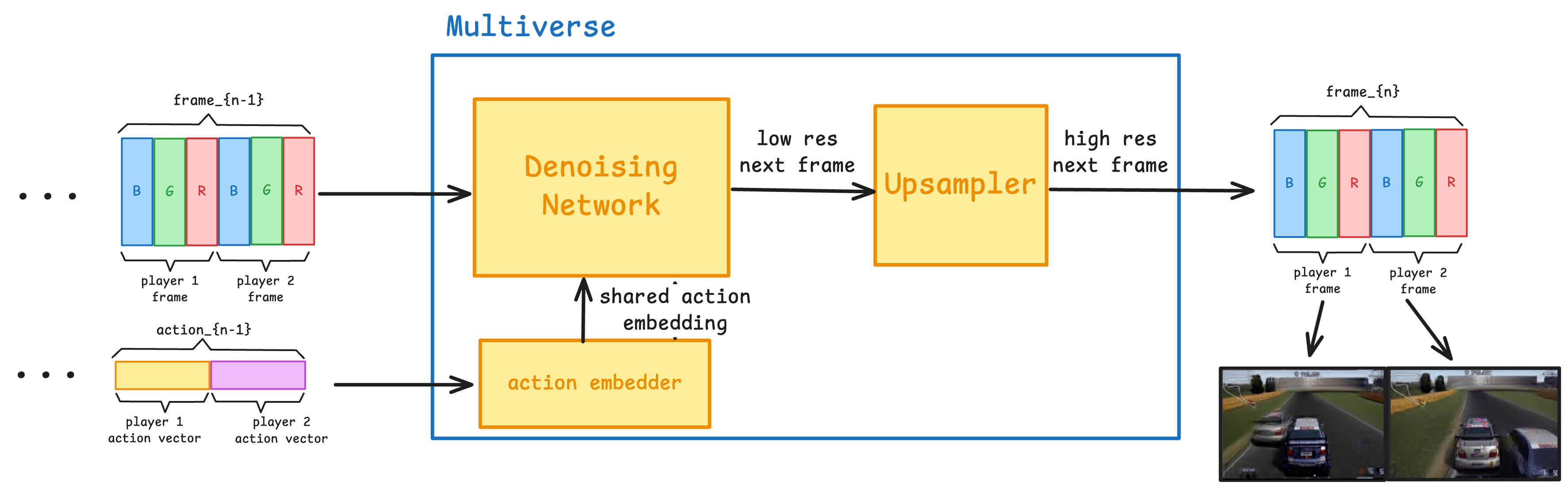
- 动作编码器(Action Embedder)
将玩家输入(如按键)转化为向量表示。 - 去噪网络(Denoising Network)
基于 Diffusion 模型,使用输入动作和前几帧视频预测下一帧。 - 上采样器(Upsampler)
对低分辨率图像进行增强,生成高清输出。
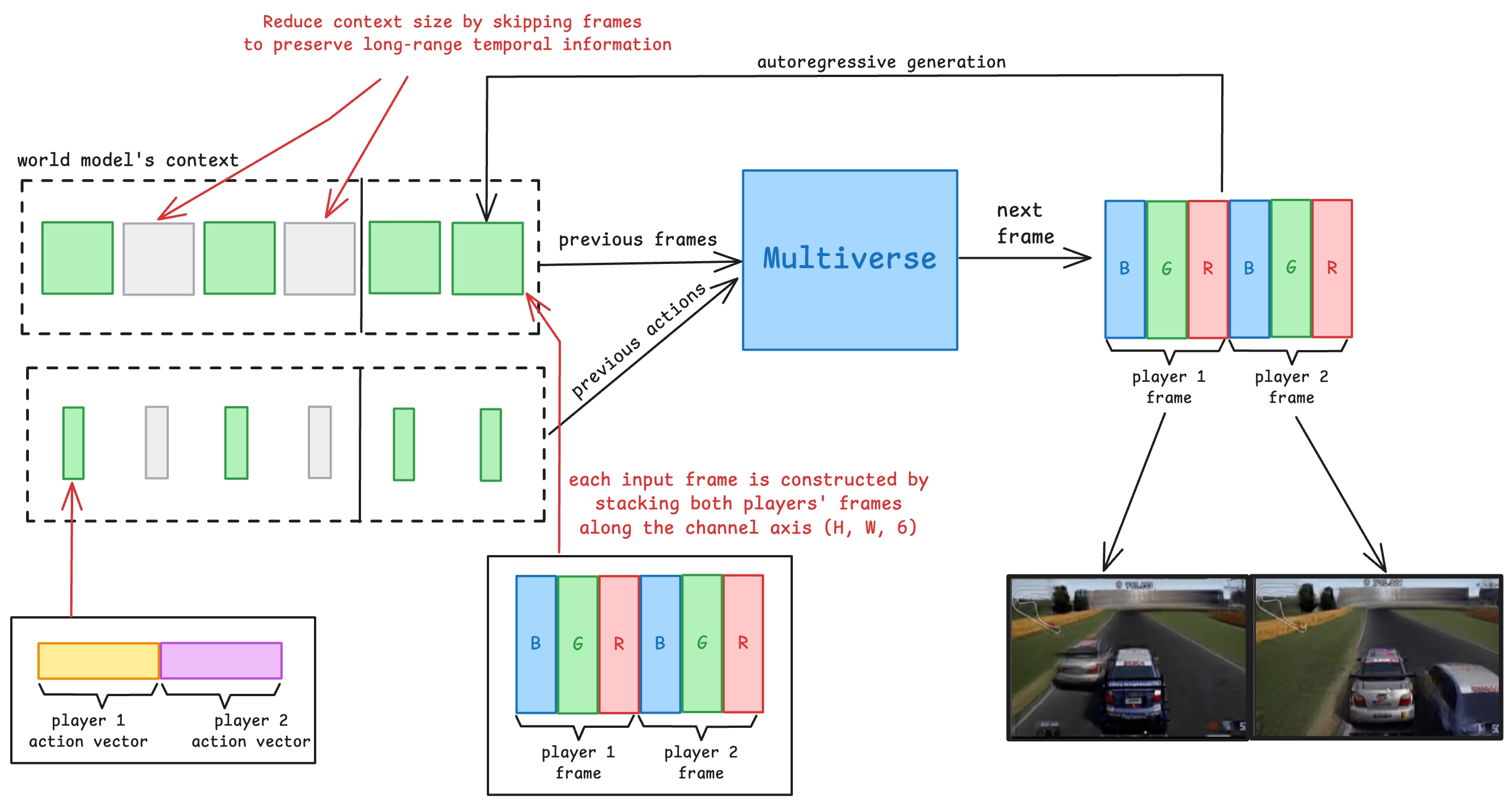
🔸 Multiverse:多人模型的结构创新
为适配多人场景,Multiverse 重新设计了上述架构:
- 双人输入动作编码器:同时接收两位玩家的控制输入,构造一个联合向量。
- 共享去噪网络:在一个统一模型中,生成两个玩家视角下的视频帧,并确保时空一致性。
- 并行上采样器:将两个低分辨率帧分别上采样,但保持一致的图像风格与动态信息。
📌 关键问题:多人场景下,AI 必须同时生成两个视角的画面,但画面内容必须对齐。也就是说,你看到车撞过来,我也必须看到车撞过来。
🖼️ 输入数据结构设计:视觉视角的融合方式
为实现共享感知,团队尝试了两种视觉融合方法:
- 垂直堆叠(Split-screen):像传统分屏游戏一样,将两个画面上下拼接。
- 通道轴融合(Channel Stacking):将两个图像帧沿 RGB 通道维度堆叠(即每个像素变成6个通道)。
结果表明:通道轴融合更优,因为这种方式可以让 U-Net 网络在所有卷积层中同时处理两个视角的信息,提升画面逻辑一致性。
📏 长时序建模与上下文优化
🎯 问题:多车交互的物理现象(如相对移动、刹车影响)变化缓慢但关键,需要更长时间窗口。
- 短期动态(例如刹车):用 8 帧(0.25 秒)建模足够。
- 长期交互(例如超车、碰撞):需要 0.5~1 秒甚至更长时间跨度。
✅ 解决方案:稀疏时间采样 + 层级预测
- 使用最近 4 帧 + 每隔 4 帧取1帧(总共8帧) → 在不增加显存压力的前提下获得更长时间感知。
- 引入 Curriculum Learning(课程式训练):先训练短期预测,逐步过渡到最长达 15 秒的预测范围,兼顾学习效率与表达能力。
🧪 数据集构建与训练流程
🎮 游戏平台选择:Gran Turismo 4(GT4)
- 使用 Tsukuba Circuit 场景,便于建模与复现。
- 游戏原生不支持 1v1 模式,团队通过 逆向工程 强行启动真实 1v1 比赛。
📹 数据采集策略
- 每场比赛录制双视角回放(每个玩家的视角),后期同步合成。
- 控制输入(油门、刹车、转向)通过计算机视觉读取 HUD 元素,不需手动记录。
⚙️ 自动化生成机制
- 利用 GT4 中的 B-Spec 模式(AI 驾驶)+ 脚本发送控制命令 → 批量生成可用视频数据。
- 实验接入 OpenPilot 自动驾驶模型进行控制,但出于稳定性和资源优化,最终选用 B-Spec。
研究价值与应用前景
核心突破:
- 实现多人视角下的一致性世界建模(synchronized multi-perspective generation)。
- 引入高效训练策略和可复现的数据管道,支持开放社区复现和验证。
潜在应用:

官方介绍:https://enigma-labs.io/blog