Kyutai STT 是由 Kyutai 团队开发的一个专为 实时语音转文字(speech-to-text) 场景优化的开源模型,主要特点是 低延迟、高准确率、强并发处理能力。
Kyutai STT 不仅能以低延迟转录语音为文字,还专为高并发和真实应用场景(如语音对话系统)设计,具备语义级语音活动检测能力。
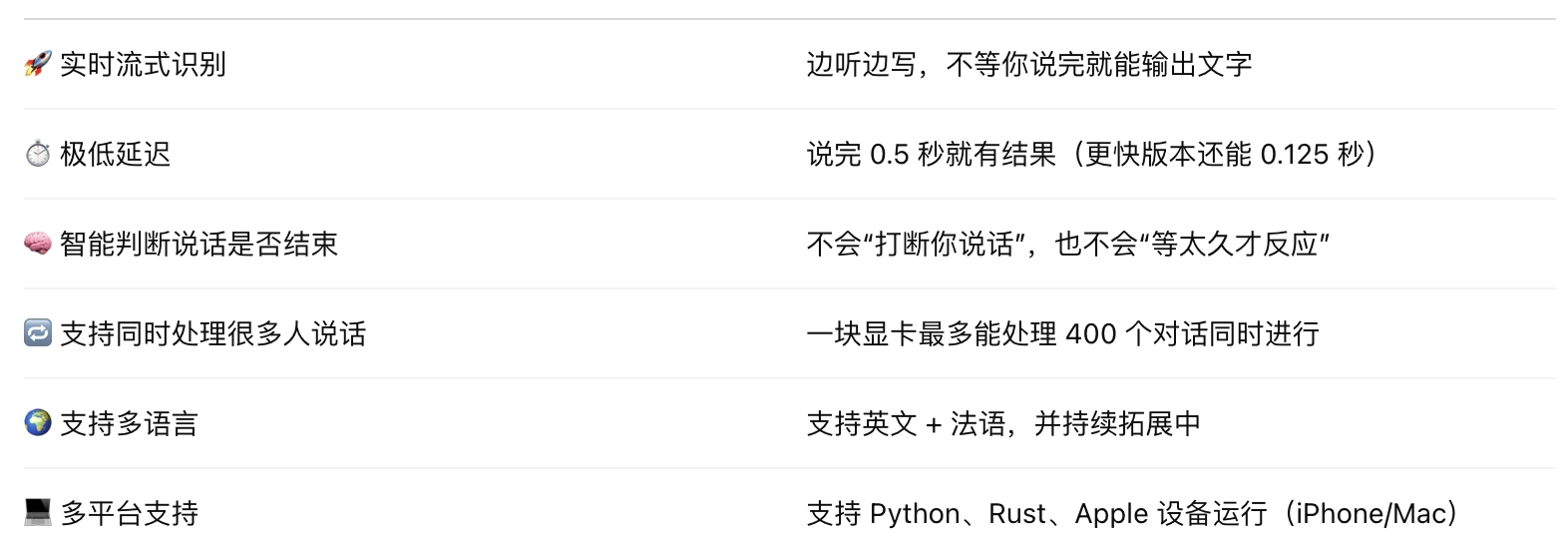
目前开源了两个版本的模型:
- kyutai/stt-1b-en_fr: 英语+法语,低延迟,适合交互式应用。
- kyutai/stt-2.6b-en: 英语,更大更准,适用于对准确率要求极高的场景。
之前介绍
[Kyutai 推出了 Unmute:它可以插入到任意的模型当中,让任意模型具有语音能力 | XiaoHu.AI 学院
Kyutai 推出了 Unmute,一个高度模块化的语音 AI 系统,可以为任何文本大语言模型(LLM)快速添加语音功能。 也就是它可以插入到任意的模型当中,让该模型具有语音能力。 Unmu...
https://www.xiaohu.ai/c/xiaohu-ai/kyutai-unmute
 ](https://www.xiaohu.ai/c/xiaohu-ai/kyutai-unmute)
](https://www.xiaohu.ai/c/xiaohu-ai/kyutai-unmute)
核心特性详解
1. 流式识别:边听边转文字
Kyutai STT 支持真正的流式语音识别,即:
- 音频边输入边处理,无需等待整段语音结束;
- 实时返回转录内容,包含标点符号和逐词时间戳;
- 在低延迟情况下,仍能维持媲美非流式模型(如 Whisper)的识别准确率。
这对实时语音助手、直播字幕生成、会议转录等应用非常关键。
2. 语义语音活动检测(Semantic VAD)
问题背景:
传统对话系统必须判断“用户说完话了没”,这通常通过检测是否“安静了一段时间”来判断。但这方法不可靠——人类说话时经常有停顿(比如思考),容易误判。
Kyutai 的解决方案:
Kyutai STT 内置了一个语义级语音活动检测模块,它不仅转录文字,还预测说话是否已结束。
- 判断依据:语音内容和语调语义(而不是静默时长);
- 能适应不同说话风格,更智能地“判断是否轮到系统回应”;
- 实验中能显著提升对话自然度,避免误打断或长时间无响应。
以前:判断“你说完了没”靠停顿时间,比如你停顿 1 秒,系统就认为你说完了。
问题:人有时候停顿不代表说完,比如“我想吃……火锅”,系统可能误判你说完了。
现在:Kyutai STT 用 AI 判断你说话的语义和语气,更聪明地判断“你真的说完了没”,准确率更高。
3. 极低延迟
- stt-1b-en_fr:延迟 500ms
- stt-2.6b-en:延迟 2.5 秒(为提高精度而牺牲部分实时性)
“Flush 技巧”:
为了进一步降低响应延迟,Kyutai 使用了一种“加速冲洗”机制:
- 检测用户说话结束后,立即触发模型加速处理剩余语音
- 模型以 4 倍实时速度完成最后部分音频处理,仅需 ~125ms
- 实际效果是让语音系统的反应更接近即时
4. 高并发性能
Moshi 特别适合大规模部署,核心优势在于其模型架构允许天然的并发处理:
- 在 NVIDIA H100 GPU 上可支持 400 路同时语音流处理
比 Whisper 等传统模型效率高很多,后者需要复杂的拼接处理(如 Whisper-Streaming)且不支持批处理,吞吐能力差

5. 多平台实现支持
Kyutai 提供了多个平台下的实现,以适应不同使用场景:
实现平台 适用场景 特点 PyTorch 研究与实验 易于在 Python 环境中调用 Rust 生产部署 稳定、性能强,支持 WebSocket MLX(Apple) iPhone / Mac 使用 Apple 硬件加速,本地运行
核心技术原理:延迟流建模(Delayed Streams Modeling)
这是一种不同于传统 Encoder-Decoder 的新方法,核心思想如下:
- 将语音和文本看作两个时间对齐的数据流;
- 文本流被“延迟”几个时间帧,允许模型看见未来一点的语音来提高准确性;
- 音频流保持不变,模型学习如何从音频流中逐步“填充”对应的文字;
- 推理时按时间步前进,无需整段音频;
该建模方式的另一个优势是可拓展性:
- 只需对流顺序和对齐方式进行调整,就能实现 TTS(语音合成);
- 当前团队正在基于此架构开发 Text-to-Speech 模型。
模型优势总结
特性 描述 低延迟 最快 500ms,适合实时语音交互 高精度 接近甚至优于非流式模型 高并发能力 支持数百路并发流处理,适合部署 语义级 VAD 判断说话是否结束更智能、更自然 多平台支持 支持科研、生产与移动端部署
- 🔗 在线体验:Unmute - 实时语音对话
📦 模型文件:
- 📁 源码地址:https://github.com/kyutai-labs/delayed-streams-modeling