LiveCC 是由新加坡国立大学和字节跳动 Show Lab开发的首个可实时视频评论(commentary)的大型视频大语言模型(Video LLM),聚焦于视频内容理解与生成自然、流畅的实时解说/弹幕评论。
能够处理动态的视频流输入,并通过实时语音转录增强模型对视频内容的理解能力。传统的视频处理模型通常针对离线视频(即预录制的完整视频)进行优化,难以应对直播、监控等实时场景。LiveCC 通过引入流式处理技术和多模态融合,填补了这一技术空白。
- 多模态能力:模型能够同时处理视频的视觉信息(如画面内容)和听觉信息(如对话或背景音),并生成相应的输出,例如字幕、问答回复或内容分析。
- 应用场景:支持在观看视频流的同时,自动生成专业级的实时解说文本,适用于体育赛事、游戏直播、教程、实时监控等等多场景。
解决了什么问题?
想象一下:
- 你在看奥运会篮球决赛,AI能像解说员一样边看边说:“法国队拿球,快攻,传球,三分,进了!”
- 这种AI如果用在视频直播、赛事讲解、教育、甚至游戏主播,都会非常有用。
- 但要训练出这种AI,得有大量**“看视频+听解说”的数据**。如果全靠人类手工标注,成本高到天文数字。
所以问题来了:
- 如何低成本、大规模收集到“视频-文本解说”数据?
- 如何让AI像人一样“流畅、实时地边看边说”?
- 如何科学评价这种AI的解说水平?
怎么解决的?
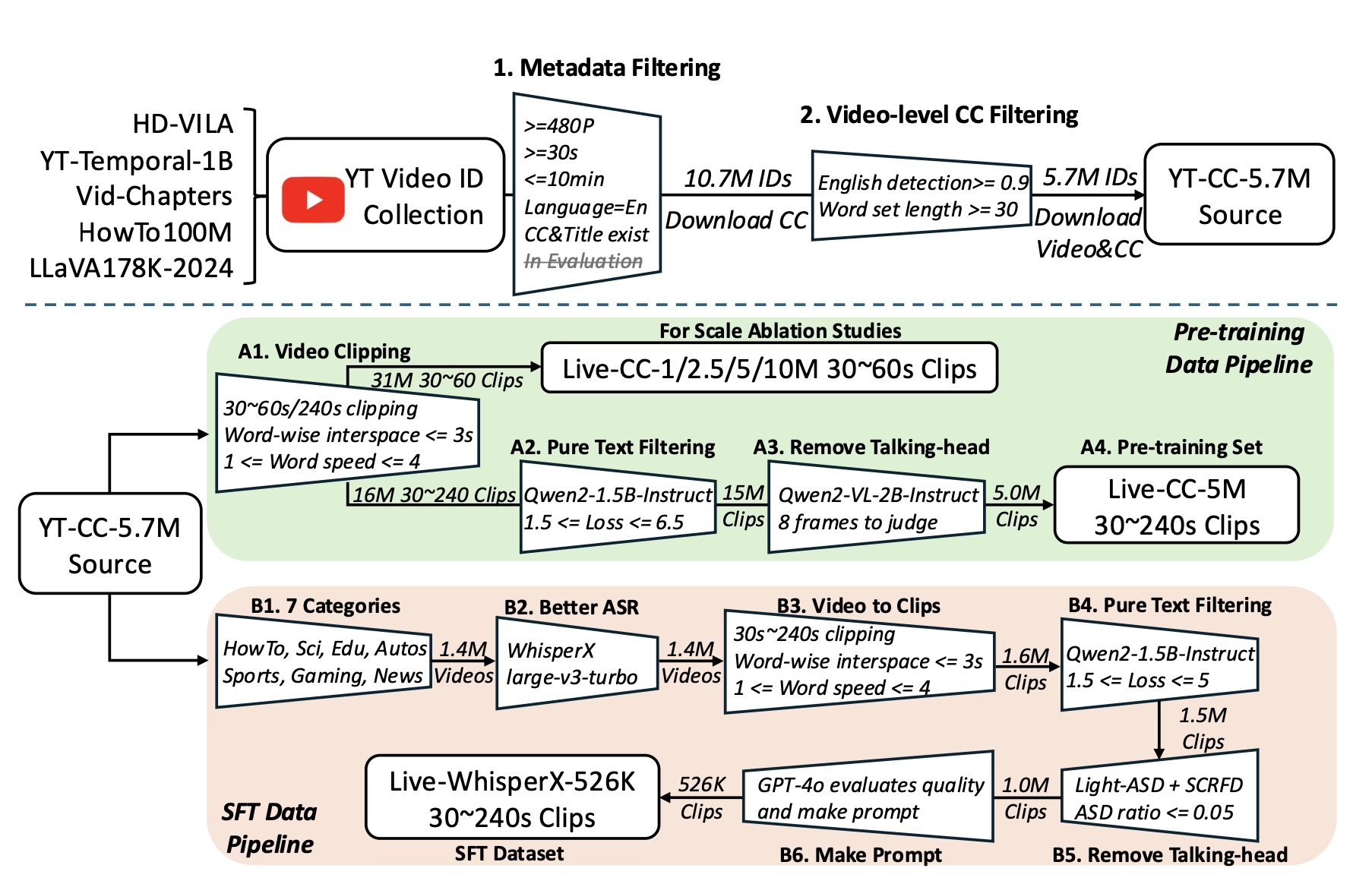
1. 用自动语音识别(ASR)+YouTube大规模视频,自动生成训练数据!
- YouTube视频很多都有自动字幕(Closed Caption, CC),这些其实就是机器听视频后自动生成的“解说”。
- 作者发现:虽然机器生成的字幕质量一般,但便宜、量大!可以用来大规模训练AI。
为了进一步提升数据质量,他们还用先进的WhisperX模型,对视频做更精准的转录。
举例:
- 一场篮球比赛的视频,有自动字幕“he passes the ball... he shoots... he scores!”(他传球,他投篮,他得分!)
AI看到每一帧的画面,配上那一刻的字幕,就能学会“看图说话”。

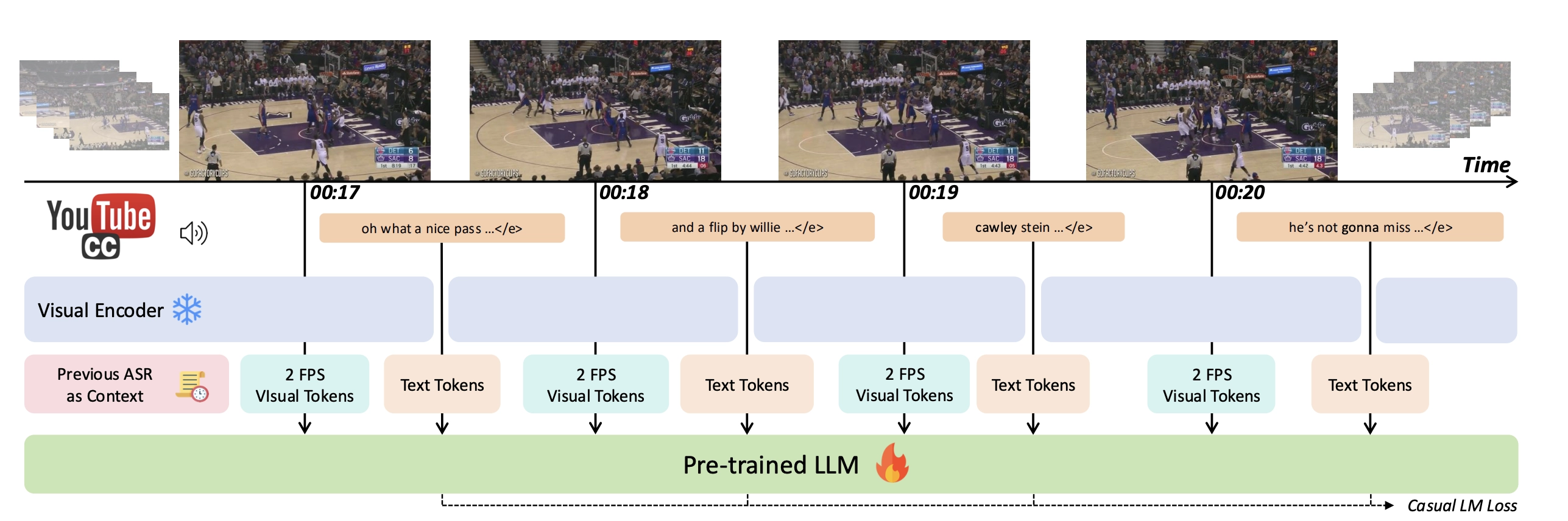
2. 创造“流式训练”方法——让AI学会“边看边说”
- 传统方法:看完一段视频,再总结性地写一段解说,不适合实时需求。
- 作者的方法:把视频切成很多小片段,每2秒配一组画面和对应ASR文本,让AI学会每来一帧、每有新字幕就即时生成解说,仿佛AI在“现场直播”。
类比理解:
就像你边看比赛,边嘴里不断地“碎碎念”场上发生的事情,而不是等比赛结束再来一大段复盘。
3. 精细筛选数据,保证训练有效
- 筛掉内容无关的、说人头的(比如一直对着摄像头讲废话、无实质动作的视频)。
- 只保留那些“声音和画面强相关”的片段,让AI学的就是“看到什么说什么”。
- 用工具自动检测视频是不是“优质内容”,比如是否分辨率够高、字幕够多、语速正常。
怎么评价AI的表现?
主观对比解说质量
- 让AI对一段视频做实时解说,同时用GPT-4o等大模型“当裁判”,两者PK,看看谁的解说更贴近真实、更自然流畅。
问答能力测试(QA)
- 给AI看一段视频后,问它“谁做了什么?什么时候?为什么?”,看看它是否理解了视频内容细节。
效果如何?
- 低延迟:AI能做到每帧延迟不到0.5秒,真的可以“边看边说”,适合直播、AR眼镜等场景。
- 泛化能力强:不仅能做解说,还能做视频问答,甚至比很多大模型做得更好。
- 模型小巧:用7B参数(算小的了),效果已经比不少72B等大模型还要好,训练和推理成本低。
实际应用价值
- 体育直播:AI可以像主持人一样随时解说,不受人工时间和语言限制。
- 教育视频:AI能实时标注、解说每一步操作,辅助学习。
- 辅助残障人士:AI可自动解说视频内容,帮助视障用户理解画面。
- 内容审核与检索:AI能理解每一帧的细节,大幅提高视频管理效率。
项目地址:https://showlab.github.io/livecc/