OpenAI 发布最新的4o图像生成 API :gpt-image-1,该API支持基于文本提示生成、编辑和变体化图片。
gpt-image-1 是OpenAI目前最先进的模型,具有更强的理解能力、画面细节、现实世界知识以及更准确的文本渲染能力,推荐优先使用。
gpt-image-1 的主要亮点包括:
- 多样化风格支持:可生成多种风格图像,满足从手绘、插画到现实照片等多种需求。
- 高度自定义:能精准遵循定制化指令与品牌需求。
- 文本渲染准确:显著提升了图像中文字内容的生成准确性。
- 广泛的世界知识:具备较强的现实背景理解和知识驱动能力。
- 高可靠性 API 接入:开发者和企业可直接集成到自身工具和平台。


这些特性使其不仅适用于简单的图片生成,还能满足对图片风格和细节要求更高的应用场景。
API 三大核心端点
Generations(生成)
通过文本描述直接生成新图片。可设置图片数量、分辨率、质量、透明度等参数。代码调用简单,支持 Python、JS、Shell 等主流环境。- 典型用法:用 prompt 生成插画、头像、像素风格素材等。
Edits(编辑)
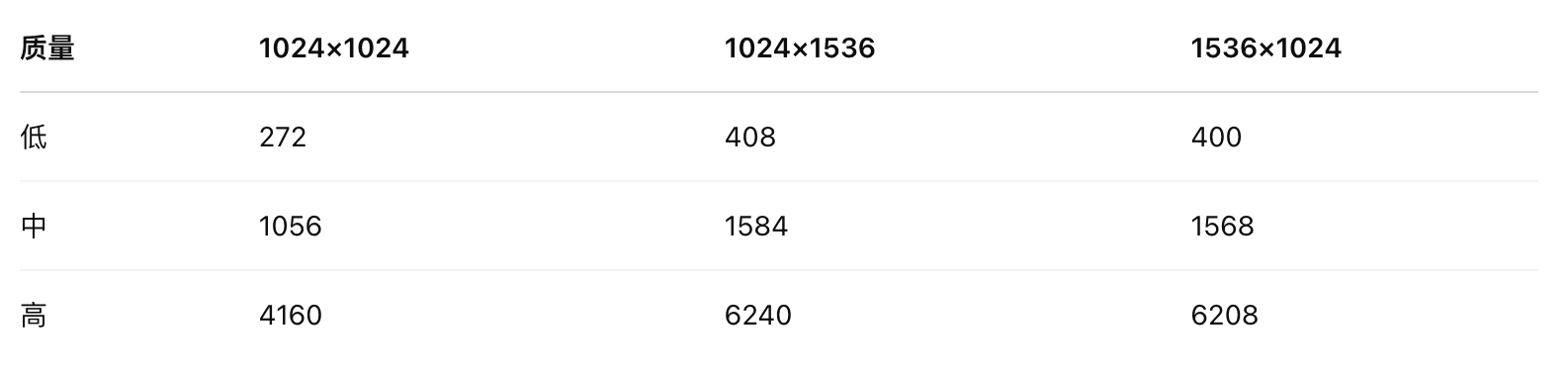
对已有图片进行编辑,可以:- 上传一张或多张图片作为参考,让 AI 组合生成新场景(如礼品篮案例)。
- 利用 mask(掩码),仅替换部分区域(如给房间加泳池等)。
- 支持 inpainting,本质是“局部魔改”。
- 图片和掩码尺寸需一致,掩码要有 alpha 通道。
- Variations(变体)(仅 DALL·E 2 支持)
上传一张图片,让模型生成风格、内容相似但不同的图片变体,常用于创意扩展或批量输出。
图像输出自定义
- 尺寸:支持正方形(1024x1024)、竖屏(1024x1536)、横屏(1536x1024)等主流分辨率,默认 auto 自动调整。
- 质量:low、medium、high,默认 auto。高质量意味着细节更丰富,但生成慢、成本更高。
- 格式:默认 PNG,支持 JPEG、WebP。后两者可自定义压缩比,适合网页加速等需求。
- 透明背景:gpt-image-1 可直接输出带 alpha 透明通道的 PNG/WebP,适合制作 UI、图标、素材。
- 多图批量生成:设置 n 参数即可一次生成多张图片,提升效率。
能力边界与限制
- 延迟:复杂场景或高质量大尺寸,生成时间可能长达 2 分钟,不适合强时效场景。
- 文本渲染:gpt-image-1 文字绘制能力已显著提升,但极高精度的排版/字形场景仍有概率出错。
- 一致性:多次生成同一角色、品牌形象时偶有不一致,需结合“图片参考”/“编辑”端点配合。
- 构图控制:对结构/版式高度敏感的画面,元素位置有时不够精准,需要反复迭代。
- 内容审核:所有请求都受官方内容安全政策(可选“auto”/“low”审核级别),不支持违规、敏感等内容生成。
费用与 Token 计价
按Token计费,文本输入、图片输入、图片输出分开计价:
- 文本输入:$5/百万tokens
- 图片输入:$10/百万tokens
- 图片输出:$40/百万tokens
换算到单张图片约为:
- 低质量约$0.02/张
- 中质量约$0.07/张
- 高质量约$0.19/张
生成图片成本由图片 token 数量决定,token 总数受分辨率、质量、输出格式等影响。
- 高分辨率和高质量图像,token 消耗(即费用)显著增加。
- 提示词本身也会计入输入 token,最终费用请参照官方 价格页面。
典型应用场景举例
- 设计与编辑(Canva):用 AI 生成/编辑平面设计、将手绘草图变为精美图像、精细化编辑等。
- Logo 和品牌资产生成(GoDaddy):一键生成/编辑 logo、移除背景、生成定制字体等,辅助用户打造品牌形象及社媒内容。
- 营销物料生成(HubSpot):为企业客户快速批量生成社交媒体、邮件推广、落地页等高质量视觉内容,无需专业设计师。
- 食谱与购物清单配图(Instacart):为食谱及购物清单自动生成吸引人的图片。
- 视频编辑辅助(invideo):提供更强大的文本生成、图像编辑、风格引导功能,提升视频创作体验。
最佳实践与Tips
- 复杂场景或高要求文本推荐先低质量小尺寸试错,再上高质量大图。
- 使用“图片编辑+掩码”功能,可以精准替换页面区域,适合 UI、包装等复用场景。
- 要多图一致性,可以用同一参考图反复编辑,或合成同一风格素材集。
- 尽量用详细、明确的 prompt(包括风格、元素、颜色等),结果更可控。
多家主流平台已集成或尝试该能力,包括:
- Adobe:Firefly 和 Express 应用将集成 gpt-image-1,为创作者带来更多审美选择。
- Figma:设计师可直接在 Figma 内用简短提示生成和编辑图片,加快创意探索与迭代。
HeyGen:提升头像生成和编辑,增强虚拟形象定制。
Wix:AI 设计平台 Wixel 让任何用户都能轻松生成专业级设计作品。
- Photoroom:帮助电商商家用单张产品照即可生成影棚级图片、场景照及模特图。
- 其它如 Instacart、InVideo、Canva、HubSpot 等团队也在测试工作流集成。
现在你可通过开发指南或 Playground 平台快速上手、调试和迭代图片生成。
好的,以下是该文档的准确翻译,保持原有格式和内容结构不变:
OpenA GPT Image 图像生成API指南
概览
OpenAI API 允许你通过文本提示生成和编辑图像,支持 GPT Image 或 DALL·E 模型。
目前,图像生成仅可通过 Image API 实现。我们正积极推进对 Responses API 的支持。
Image API 提供三个端点,每个端点具有不同的能力:
你还可以通过指定质量、尺寸、格式、压缩率,以及是否需要透明背景,自定义输出。
模型对比
我们最新、最先进的图像生成模型是 gpt-image-1,这是一款原生多模态语言模型。
我们推荐该模型,因为它在图像生成质量上表现优异,且能利用世界知识进行图像创作。当然,你也可以用 Image API 调用专用图像生成模型 DALL·E 2 或 DALL·E 3。
模型 支持端点 使用场景 DALL·E 2 Image API: Generations, Edits, Variations 成本较低、支持并发请求、修补(带掩码的图像编辑) DALL·E 3 Image API: 仅 Generations 图像质量高于 DALL·E 2,支持更大分辨率 GPT Image Image API: Generations, Edits – Responses API 即将支持 指令理解能力强,文本渲染优异,编辑细致,具备世界知识
本指南重点介绍 GPT Image,你也可以切换至 DALL·E 2 和 DALL·E 3 的文档。

生成图像
你可以使用 图像生成端点 ,基于文本提示创建图像。了解如何自定义输出(尺寸、质量、格式、透明度)可参见下方的自定义图像输出章节。
你可以设置 n 参数,在一次请求中生成多张图片(默认只返回一张图片)。
``` import OpenAI from "openai"; import fs from "fs"; const openai = new OpenAI();
const prompt =
A children's book drawing of a veterinarian using a stethoscope to
listen to the heartbeat of a baby otter.
;
const result = await openai.images.generate({ model: "gpt-image-1", prompt, });
// 保存图片到文件 const imagebase64 = result.data[0].b64json; const imagebytes = Buffer.from(imagebase64, "base64"); fs.writeFileSync("otter.png", image_bytes);
```
``` from openai import OpenAI import base64 client = OpenAI()
prompt = """ A children's book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter. """
result = client.images.generate( model="gpt-image-1", prompt=prompt )
imagebase64 = result.data[0].b64json imagebytes = base64.b64decode(imagebase64)
保存图片到文件
with open("otter.png", "wb") as f: f.write(image_bytes)
```
``` curl -X POST "https://api.openai.com/v1/images/generations" \ -H "Authorization: Bearer $OPENAIAPIKEY" \ -H "Content-type: application/json" \ -d '{ "model": "gpt-image-1", "prompt": "A childrens book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter." }' | jq -r '.data[0].b64_json' | base64 --decode > otter.png
```
编辑图像
图像编辑端点 可用于:
- 编辑已有图像
- 利用其他图片作为参考生成新图像
- 通过上传图像和掩码,仅替换部分区域(即修补/inpainting)
使用参考图像生成新图
你可以用一张或多张图片作为参考,生成新图片。
本例中我们用 4 张输入图片生成一个包含所有物品的礼品篮新图像。
``` import base64 from openai import OpenAI client = OpenAI()
prompt = """ Generate a photorealistic image of a gift basket on a white background labeled 'Relax & Unwind' with a ribbon and handwriting-like font, containing all the items in the reference pictures. """
result = client.images.edit( model="gpt-image-1", image=[ open("body-lotion.png", "rb"), open("bath-bomb.png", "rb"), open("incense-kit.png", "rb"), open("soap.png", "rb"), ], prompt=prompt )
imagebase64 = result.data[0].b64json imagebytes = base64.b64decode(imagebase64)
保存图片到文件
with open("gift-basket.png", "wb") as f: f.write(image_bytes)
```
``` import fs from "fs"; import OpenAI, { toFile } from "openai";
const client = new OpenAI();
const imageFiles = [ "bath-bomb.png", "body-lotion.png", "incense-kit.png", "soap.png", ];
const images = await Promise.all( imageFiles.map( async (file) => await toFile(fs.createReadStream(file), null, { type: "image/png", }), ), );
const rsp = await client.images.edit({ model: "gpt-image-1", image: images, prompt: "Create a lovely gift basket with these four items in it", });
// 保存图片到文件 const imagebase64 = rsp.data[0].b64json; const imagebytes = Buffer.from(imagebase64, "base64"); fs.writeFileSync("basket.png", image_bytes);
```
``` curl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64json' | base64 --decode > gift-basket.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAIAPI_KEY" \ -F "model=gpt-image-1" \ -F "image[]=@body-lotion.png" \ -F "image[]=@bath-bomb.png" \ -F "image[]=@incense-kit.png" \ -F "image[]=@soap.png" \ -F 'prompt=Generate a photorealistic image of a gift basket on a white background labeled "Relax & Unwind" with a ribbon and handwriting-like font, containing all the items in the reference pictures'
```
使用掩码编辑图片(修补)
你可以提供掩码,指定图片哪些区域需要编辑。掩码的透明区域将被替换,黑色区域则保持不变。
你可以用提示描述整个新图像,不只限于被擦除的区域。如果提供多张输入图像,掩码会应用于第一张图片。
``` from openai import OpenAI client = OpenAI()
result = client.images.edit( model="gpt-image-1", image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt="A sunlit indoor lounge area with a pool containing a flamingo" )
imagebase64 = result.data[0].b64json imagebytes = base64.b64decode(imagebase64)
保存图片到文件
with open("composition.png", "wb") as f: f.write(image_bytes)
```
``` import fs from "fs"; import OpenAI, { toFile } from "openai";
const client = new OpenAI();
const rsp = await client.images.edit({ model: "gpt-image-1", image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, { type: "image/png", }), mask: await toFile(fs.createReadStream("mask.png"), null, { type: "image/png", }), prompt: "A sunlit indoor lounge area with a pool containing a flamingo", });
// 保存图片到文件 const imagebase64 = rsp.data[0].b64json; const imagebytes = Buffer.from(imagebase64, "base64"); fs.writeFileSync("lounge.png", image_bytes);
```
``` curl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64json' | base64 --decode > lounge.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAIAPIKEY" \ -F "model=gpt-image-1" \ -F "mask=@mask.png" \ -F "image[]=@sunlitlounge.png" \ -F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
```
掩码要求
待编辑图片和掩码需为相同格式和尺寸(小于 25MB)。
掩码图片还必须包含 alpha 通道。如果用图片编辑工具创建掩码,请确保保存时包含 alpha 通道。
为黑白掩码添加 alpha 通道
你可以用程序方式给黑白掩码添加 alpha 通道。
为黑白掩码添加 alpha 通道
``` from PIL import Image from io import BytesIO
1. 加载黑白掩码为灰度图
mask = Image.open(imgpathmask).convert("L")
2. 转为 RGBA,以便有 alpha 通道
mask_rgba = mask.convert("RGBA")
3. 用掩码本身填充 alpha 通道
mask_rgba.putalpha(mask)
4. 转换为字节
buf = BytesIO() maskrgba.save(buf, format="PNG") maskbytes = buf.getvalue()
5. 保存结果文件
imgpathmaskalpha = "maskalpha.png" with open(imgpathmaskalpha, "wb") as f: f.write(maskbytes)
```
自定义图像输出
你可以配置如下输出选项:
- 尺寸:图像分辨率(如 1024x1024、1024x1536 等)
- 质量:渲染质量(如 low、medium、high)
- 格式:文件输出格式
- 压缩率:JPEG 和 WebP 格式下的压缩级别(0-100%)
- 背景:透明或不透明
尺寸和质量选项
正方形且标准质量的图片生成速度最快。默认尺寸为 1024x1024 像素。
输出格式
Image API 返回 base64 编码的图像数据。默认格式为 png,也可指定 jpeg 或 webp。
如果使用 jpeg 或 webp,还可通过 output_compression 参数控制压缩级别(0-100%)。比如 output_compression=50 表示压缩 50%。
透明度
gpt-image-1 模型支持透明背景。设置 background 参数为 transparent 即可。
仅 png 和 webp 格式支持透明背景。
透明度建议搭配 medium 或 high 质量使用。
生成透明背景图像示例
``` import OpenAI from "openai"; import fs from "fs"; const openai = new OpenAI();
const result = await openai.images.generate({ model: "gpt-image-1", prompt: "Draw a 2D pixel art style sprite sheet of a tabby gray cat", size: "1024x1024", background: "transparent", quality: "high", });
// 保存图片到文件 const imagebase64 = result.data[0].b64json; const imagebytes = Buffer.from(imagebase64, "base64"); fs.writeFileSync("sprite.png", image_bytes);
```
``` from openai import OpenAI import base64 client = OpenAI()
result = client.images.generate( model="gpt-image-1", prompt="Draw a 2D pixel art style sprite sheet of a tabby gray cat", size="1024x1024", background="transparent", quality="high", )
imagebase64 = result.json()["data"][0]["b64json"] imagebytes = base64.b64decode(imagebase64)
保存图片到文件
with open("sprite.png", "wb") as f: f.write(image_bytes)
```
``` curl -X POST "https://api.openai.com/v1/images" \ -H "Authorization: Bearer $OPENAIAPIKEY" \ -H "Content-type: application/json" \ -d '{ "prompt": "Draw a 2D pixel art style sprite sheet of a tabby gray cat", "quality": "high", "size": "1024x1024", "background": "transparent" }' | jq -r 'data[0].b64_json' | base64 --decode > sprite.png
```
限制
GPT-4o 图像模型是一款强大且多功能的图像生成模型,但仍需注意以下局限:
- 延迟:复杂提示可能需要最多 2 分钟处理。
- 文本渲染:虽较 DALL·E 系列大幅提升,但在精确文字排版和清晰度方面仍有一定难度。
- 一致性:模型有能力保持图像一致性,但多次生成同一角色或品牌元素时,偶尔仍会出现不一致。
- 构图控制:尽管指令理解已提升,模型在元素精准布局、结构化或版式敏感的图像生成上有时仍有困难。
内容审核
所有提示与生成图像都将根据我们的内容政策进行过滤。
使用 gpt-image-1 生成图像时,可以通过 moderation 参数控制审核严格度。支持以下两种取值:
- auto(默认):标准过滤,限制生成某些潜在不适宜内容。
- low:限制更少。
费用与延迟
本模型通过先生成专用图像 token 再渲染图片。图片尺寸越大、质量越高,token 数量越多,生成时延与成本也越高。
token 数取决于图像尺寸和质量:

此外还需计算提示文本使用的 输入 token。
详细价格信息可参考 价格页面。