Profluent是一家位于加州伯克利的AI优先蛋白设计公司,他们开发了一个新一代蛋白质生成基础模型 ProGen3
该模型借鉴了自然语言处理(NLP)中的大规模语言建模技术,用于“编写”新型蛋白质,应用于生物医学、农业和工业领域。
ProGen3 基于大型、语言模型架构,能够设计全新蛋白质或优化已有蛋白结构,以满足药物研发、基因编辑等生物工程需求。
它的本质是把蛋白质序列看作“语言”,用类似于ChatGPT那样的模型来“说”出有功能的新蛋白。这种方式被称为蛋白语言模型(Protein Language Model)。
✅ 它是干什么的?
ProGen3 是一种由人工智能驱动的“蛋白质设计引擎”,可以生成全新的蛋白质,包括治疗用抗体和基因编辑工具。
🌟 有哪些特别厉害的功能?
- 能“一次就设计成功”很多过去需要反复试验的药物蛋白。
- 不仅速度快,而且能生成更“独特”的蛋白质,表达能力和功能都很强。
- 模型越大,设计出的蛋白就越聪明、越有用!
💥 解决了什么问题?
- 解决了传统抗体药物研发慢、贵的问题。
- 提供了能“塞进小型病毒载体”的超级小型基因编辑工具。
ProGen3 并不仅仅是一个模型,更代表了AI主导蛋白质设计的成熟与商业化转折点。它解决了以下关键问题:

ProGen3 将蛋白质设计从“基于自然选择的慢演化”推进到“基于数据驱动的加速合成”,标志着AI 在生命科学中的实用性跃升。
核心亮点和技术细节
1. 模型规模与数据支撑
训练数据集:Profluent Protein Atlas v1(PPA-1)
- 收录了 34亿个全长蛋白质序列
- 共计 1.1万亿个氨基酸 token,为目前已知最大规模
模型最大版本:ProGen3-46B
- 拥有 460亿参数
训练数据总量达 1.5万亿 token
2. 架构优化
- 使用稀疏架构(sparse architecture),在不牺牲精度的前提下,推理速度提升4倍,便于产业化部署。
3. Scaling Law(规模定律)在生物中的首次验证
- 类似自然语言模型的发展,ProGen3 展示出“模型越大、设计能力越强”的规律。
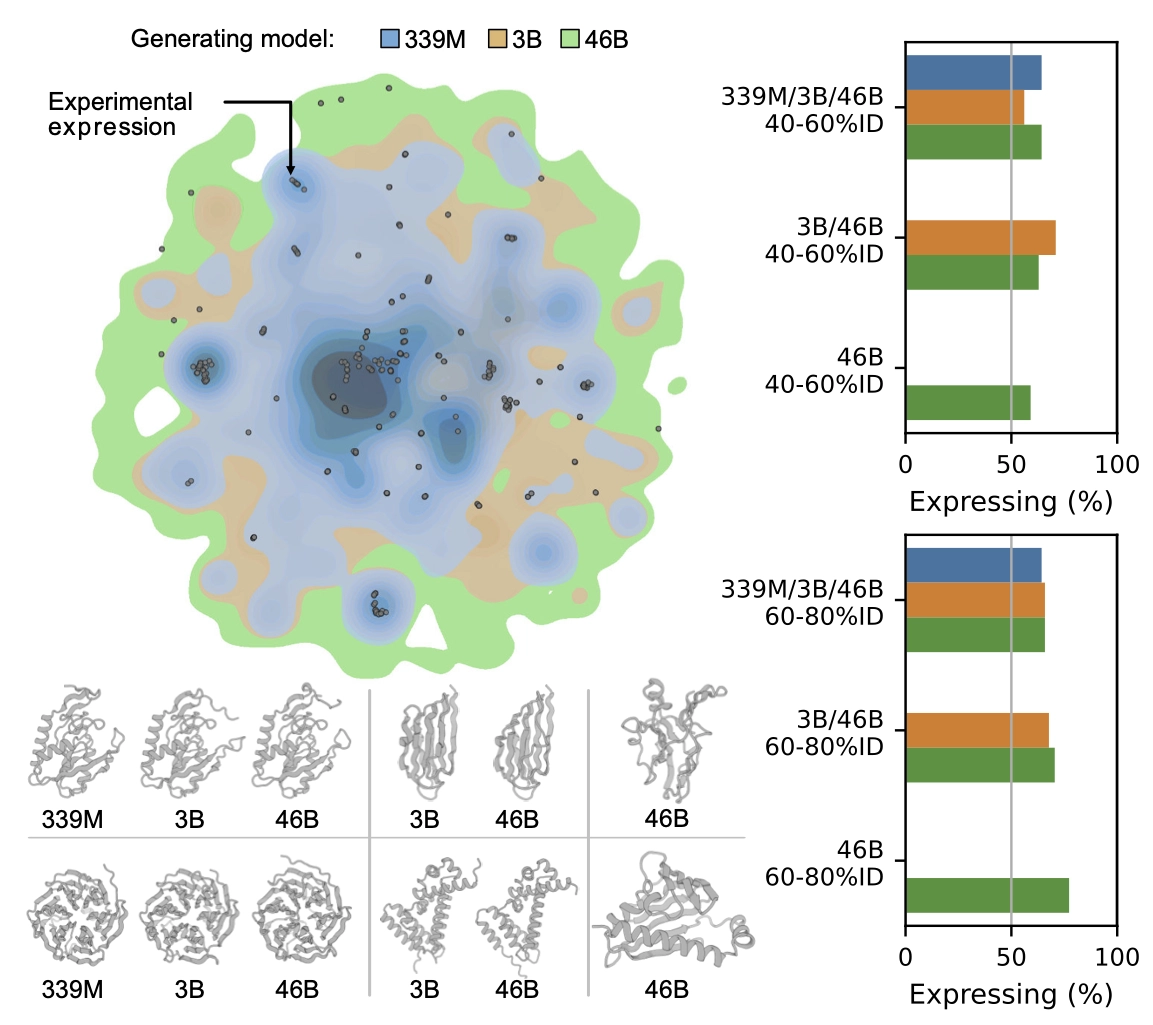
ProGen3-46B 能覆盖的蛋白家族远大于小模型,生成序列的多样性提升显著:
- 比3B版本多出 59% 多样性
比339M版本多出 198% 多样性
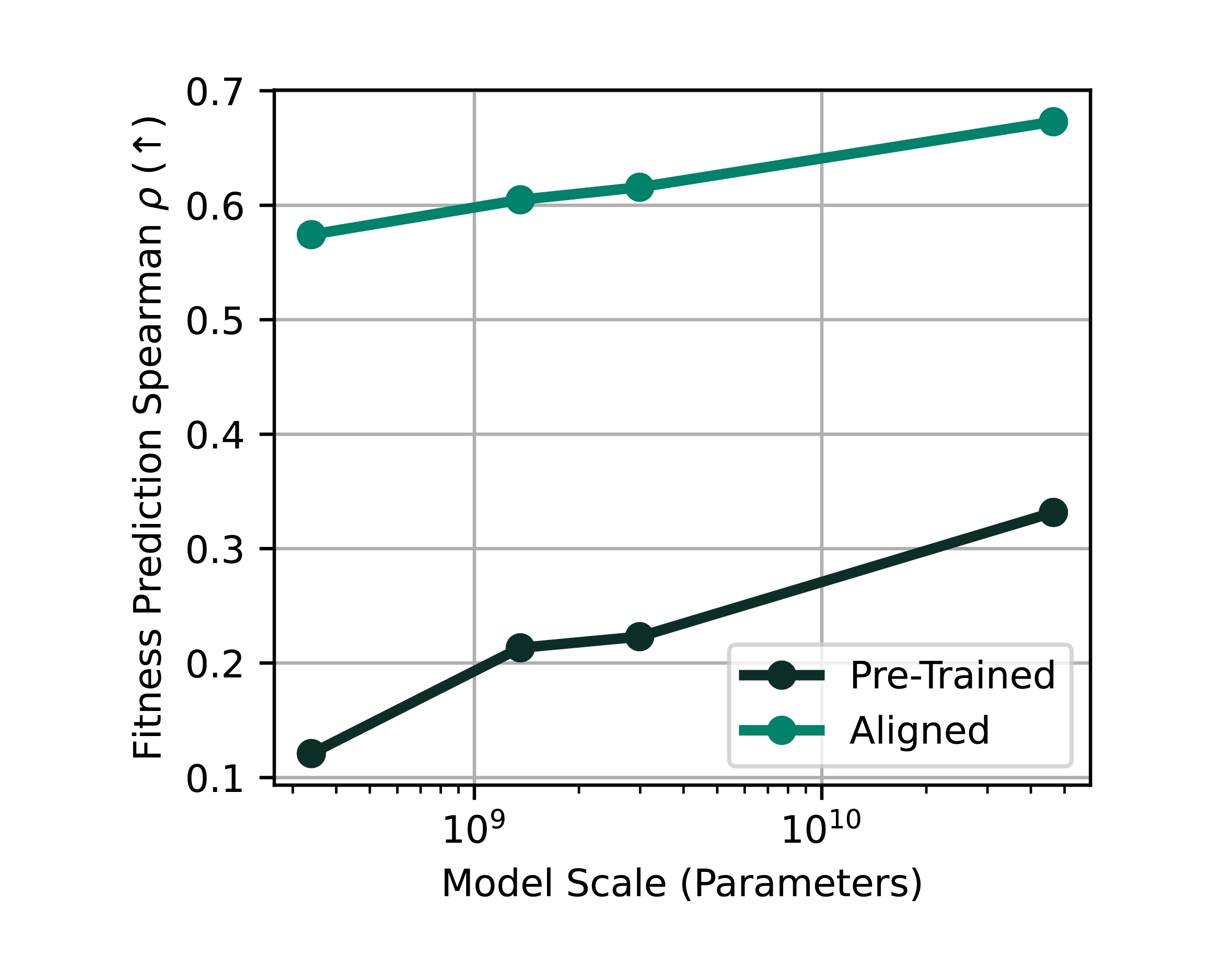
4. 模型对实验数据的对齐能力
- 通过少量实验数据,可以让模型对齐实际需要的性能指标,如活性、表达量、稳定性、结合亲和力。
- 例子:ProGen3-46B 的蛋白适应度预测相关性从 33.1% 提升至 67.3%,效果提升显著。
三、代表性应用场景
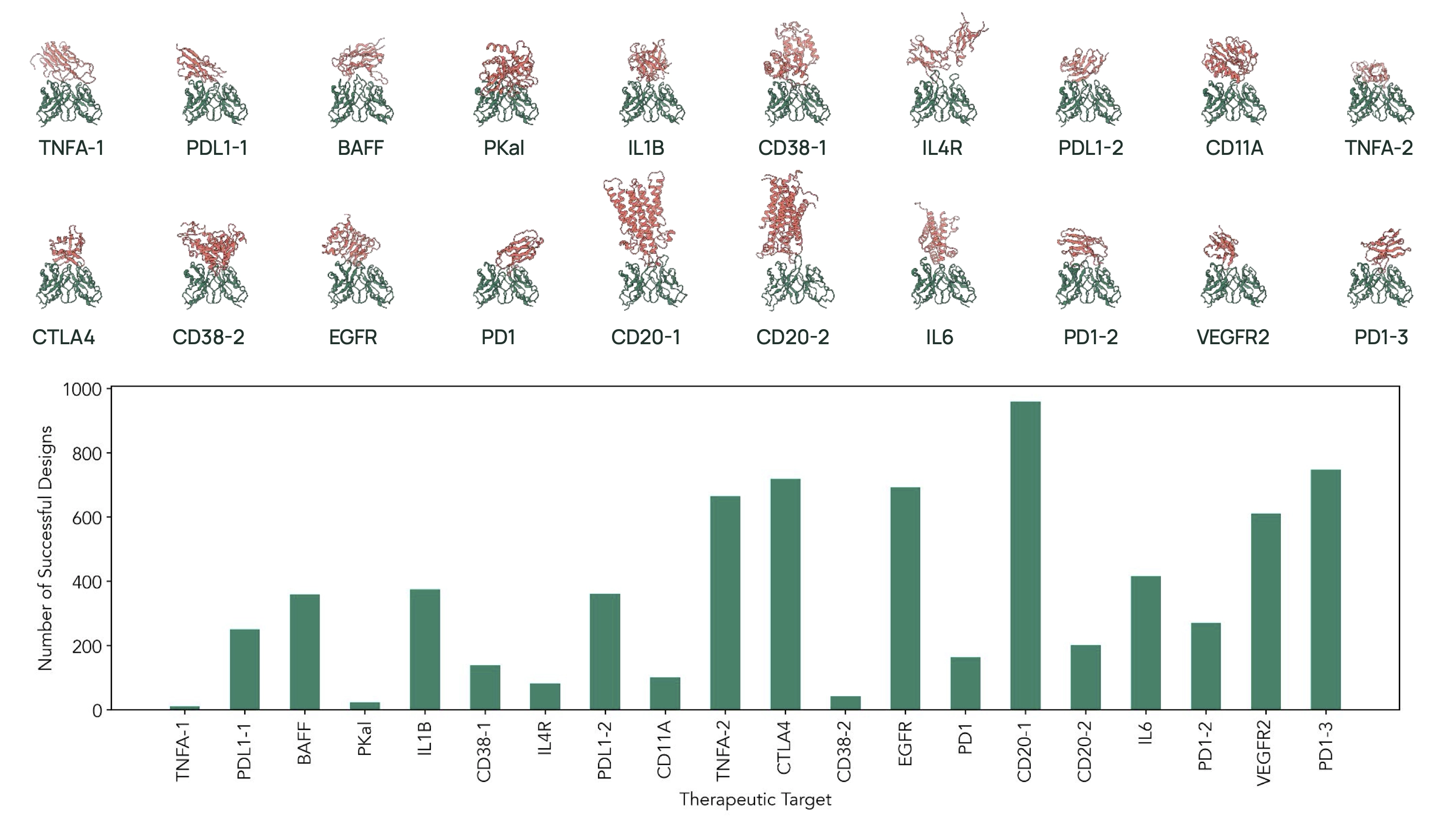
应用一:OpenAntibodies(单次生成治疗性抗体)
目标:
- 生成具有潜在治疗能力的抗体,用于20个靶点,这些靶点对应的已有药物累计服务700万人、销售额达6600亿美元。
亮点:
- 设计出的抗体 在结构上显著不同于现有药物,但预测具有相似甚至更强的功能。
- 平均序列同源性低于80%,所有CDR(互补决定区)均有变异。
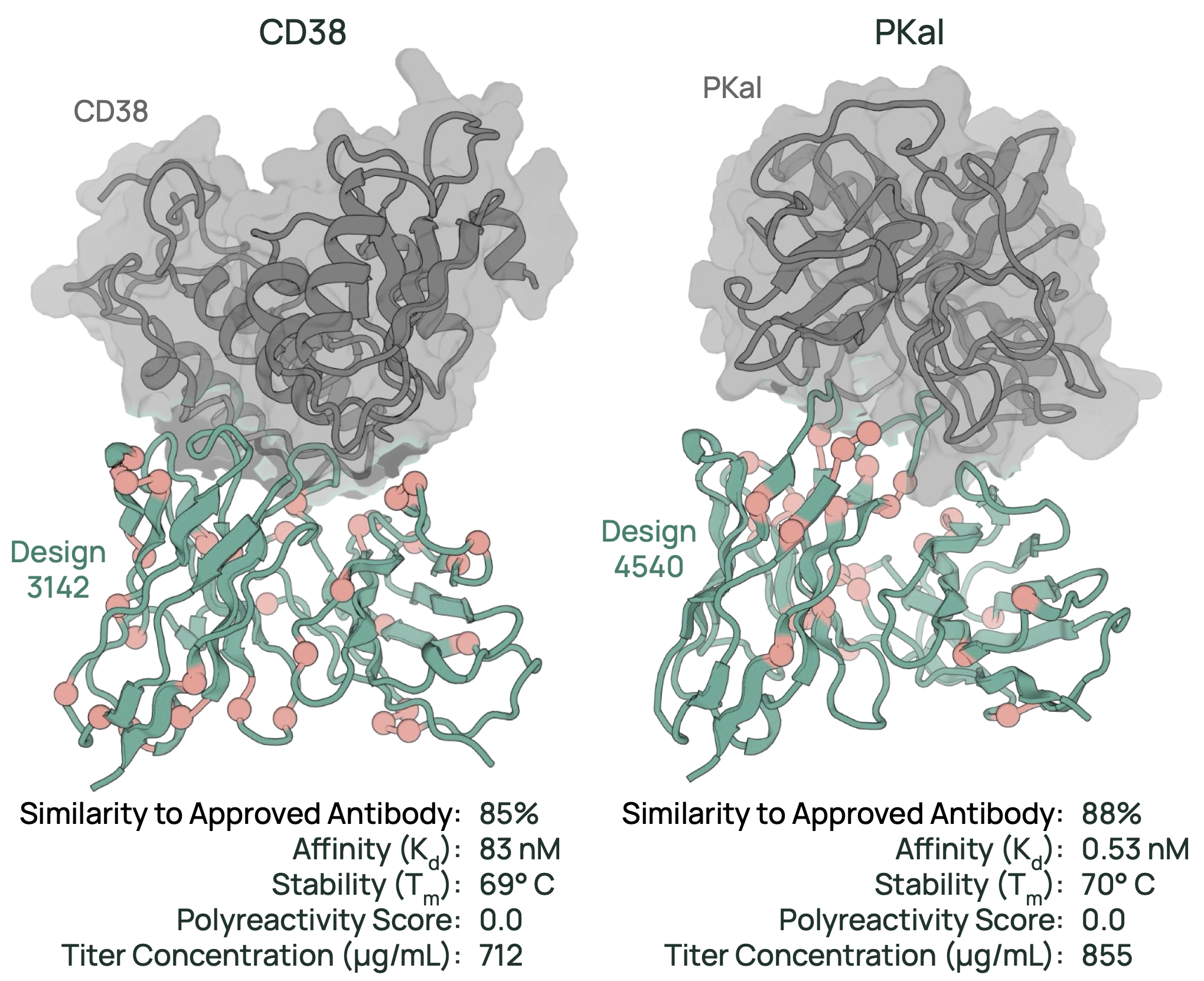
实验验证对 CD38、PKal 等靶点的抗体显示出更好的 亲和力和可开发性(developability)。
意义:
这打破了抗体药物研发中“从已知抗体做微调”的传统做法,首次实现在体外一次性设计出接近药物级别的新抗体,效率极高。
应用二:超小型基因编辑工具
问题背景:
- 主流基因编辑工具(如 Cas9)蛋白体积大,不利于通过病毒载体(如 AAV)送入体内。
ProGen3 解决方案:
- 设计出 最小仅592个残基的可编程蛋白,比 Cas9 减少约一半长度。
可嵌入 AAV 系统中,与组织特异性启动子等元件联合使用,实现更精准治疗。
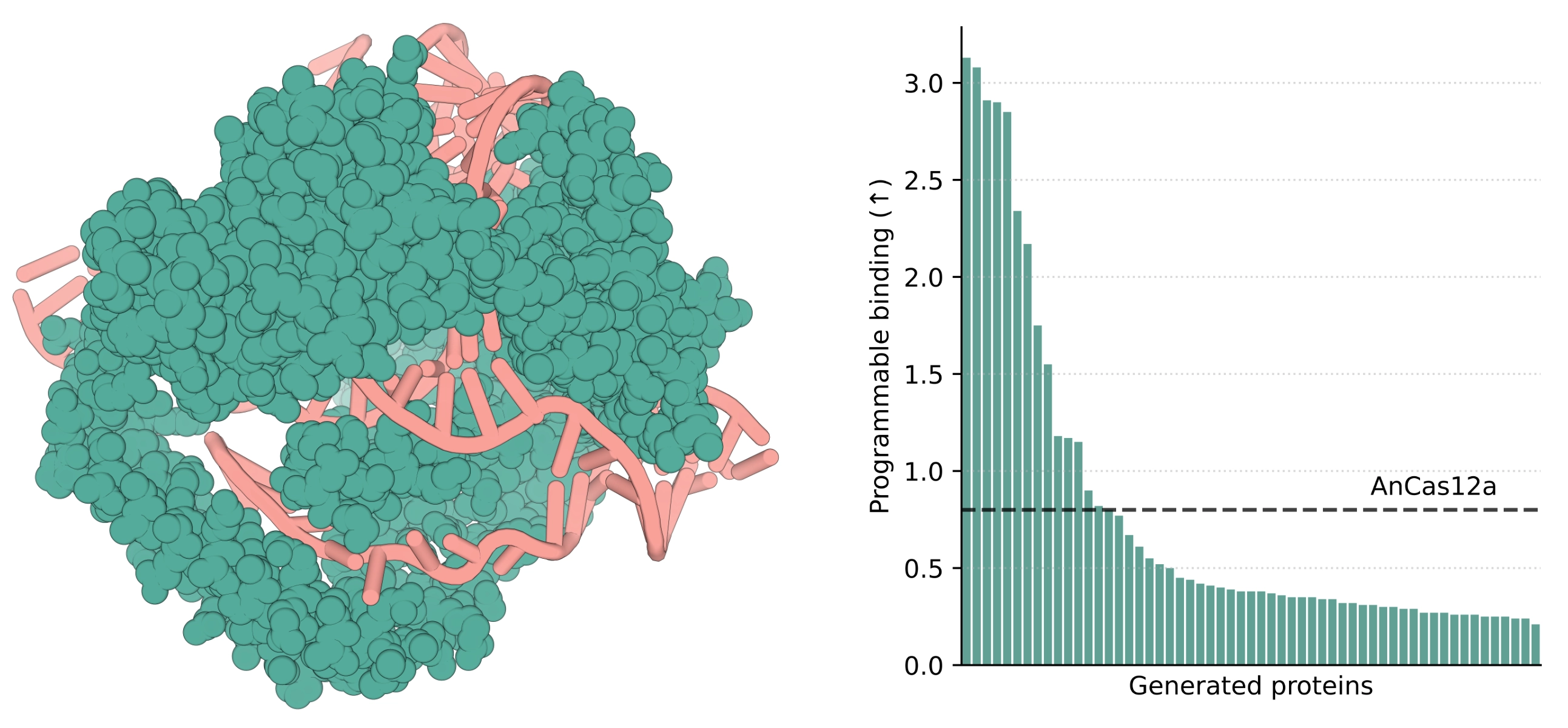
实验验证:
- 多种设计已在体外验证具有基因编辑功能。
意义:
ProGen3 为下一代基因编辑工具开发提供了新的思路:不再依赖天然演化体系,而是由AI主导重新设计结构紧凑的新蛋白。
合作模式与商业路径
Profluent 为生物医药、农业、工业生物等领域提供三种合作方式:
分子授权(Molecule Licensing):
- 快速获取已设计好的蛋白分子,用于内部研发。
模型API访问(Model API Access):
- 加入早期用户计划,使用 ProGen3 模型生成自定义蛋白。
定制研发合作(Collaborative R&D):
- 联合研发新蛋白结构,推进实际产品应用。
官方介绍:https://www.profluent.bio/showcase/progen3
论文:https://www.biorxiv.org/content/10.1101/2025.04.15.649055v1