NVIDIA, a global leader in chip and AI technology, recently launched Llama3.1Nemotron Ultra253B, a new open-source large language model (LLM), generating significant buzz in the AI community. Built upon Meta's Llama-3.1-405B, this model boasts innovative optimizations, surpassing competitors like Llama4Behemoth and Maverick in performance while maintaining high resource efficiency and excellent multi-tasking capabilities, paving the way for wider AI application deployment.
Llama3.1Nemotron Ultra253B features 253 billion parameters and supports ultra-long context lengths of up to 128K tokens, enabling it to effortlessly handle complex text inputs while maintaining logical coherence. Compared to its predecessors, this version shows significant improvements in reasoning, mathematical operations, code generation, instruction following, retrieval-augmented generation (RAG), and tool use. Whether tackling complex mathematical problems, generating high-quality code, or responding to intricate multi-step instructions, Nemotron Ultra delivers with impressive accuracy and stability, providing powerful AI support for developers and enterprise users.
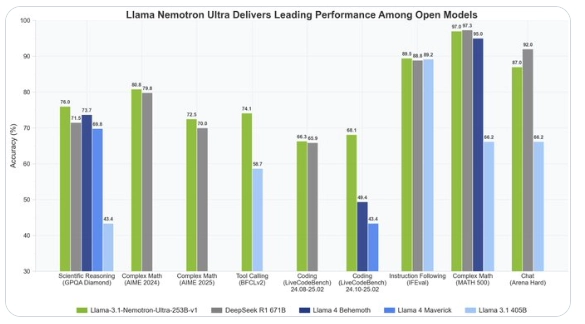
This breakthrough performance stems from NVIDIA's multiple technological innovations in model optimization. Neural Architecture Search (NAS) systematically explores network structures, significantly reducing memory footprint and ensuring efficient operation in resource-constrained environments. Furthermore, NVIDIA's pioneering vertical compression technology optimizes computational efficiency, boosting inference throughput and drastically reducing latency. Reportedly, the model can perform inference on a single 8x H100 GPU node, offering high deployment flexibility in data center or edge computing scenarios.
Compared to other LLMs on the market, Nemotron Ultra excels in balancing performance and efficiency. Despite having a smaller parameter count than some ultra-large models, its intelligent architecture design surpasses competitors, including Llama4Behemoth, in various benchmark tests. It particularly shines in tasks requiring deep reasoning and creative output, demonstrating potential that approaches or even surpasses top commercial models. Crucially, as an open-source model, Nemotron Ultra's complete weights are available via Hugging Face, allowing developers free access and customization, further democratizing AI technology.
However, this technological advancement presents challenges. While Nemotron Ultra's performance is impressive, its limits in ultra-large-scale tasks or specific domains require further testing. Additionally, the widespread use of open-source models may raise data security and ethical concerns, requiring NVIDIA to invest more in technical support and regulation.
As another milestone in AI, Llama3.1Nemotron Ultra253B showcases NVIDIA's leading position in hardware and algorithm co-optimization, setting a new benchmark for performance and efficiency. From intelligent assistants and automated programming to enterprise-level knowledge management, this model's versatility is reshaping the boundaries of AI applications. As the developer community explores its potential, Nemotron Ultra is poised to spark a new wave of technological innovation globally, injecting limitless possibilities into the future of artificial intelligence.