
Soraor(Soraor.com)3月19日 消息:18 日,LG公开了韩国首个推理型AI大模型 —— 一种像人类一样经过逻辑性和阶段性的思考过程后得出答案的AI模型—— 它与从已学习的数据中寻找答案的传统模型有所不同。
最近,来自中国的Deepseek以低成本、高性能震惊全世界,甚至撼动了“AI先锋” OpenAI 的地位。在这样的背景下,韩国也开发出了“能与它们竞争”的AI模型。LG 虽然向普通大众公开了他们的AI模型,但并未像 Deepseek、 ChatGPT 那样让普通人能够使用相关 AI 服务 —— 仅在公司内部将其用于产品开发等方面。
当天,LG 人工智能研究院公开了 “EXAONE Deep”—— 其主力模型是 “EXAONE Deep-32B”。人工智能在学习和推理时,用于连接数据的单位 —— 参数数量达到了 320 亿个。参数数量越多,人工智能的性能就越好,但驱动它所需的人工智能半导体也就越多。因此,最近在‘尽量减少参数数量的同时提高性能’的竞争十分激烈。
LG 人工智能研究院强调,Deepseek-R1 的参数数量为 6710 亿,而“EXAONE Deep - 32B” 虽然仅约为其的 5%,但=性能却与之相当。
为了验证它的说法,LG还实际将其与 Deepseek等中国AI模型进行了性能比较,结果发现:“EXAONE Deep-32B” 在数学方面尤其取得了出色的结果 —— 在 2024 年美国数学奥林匹克竞赛的题目中,它获得了 90 分,超过了 “Deepseek”—— 86.7 分,参数数量相同的阿里巴巴的 QwQ-32B(86.7 分)也被它超越。在韩国 2025 年高考数学部分,它也以 94.5 分的成绩,在与其他模型的比较中取得了最高分。在博士水平的科学问题中,它获得了 66.1 分,高于阿里 QwQ-32B 的 63.3 分。
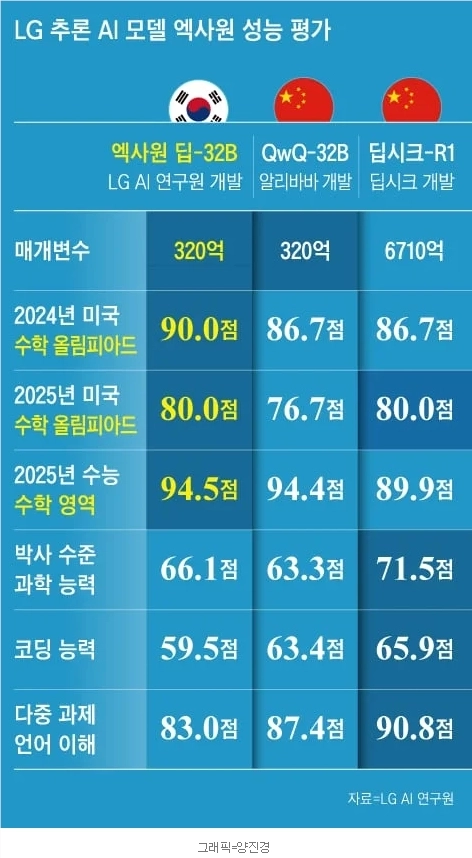
不过,在编码能力和语言能力方面,它落后于 Deepseek 等模型。在评估语言能力的 “多任务语言理解” 项目中,它得到了 83 分,不及阿里(87.4 分)和 Deepseek(90.8 分)。业内相关人士表示:“推理型模型在解决数学或科学问题方面具有专长”、“与参数数量多的模型相比,其语言能力必然会有所欠缺。”
此外,LG 人工智能研究院还公开了参数数量进一步减少的轻量模型 —— EXAONE Deep-7.8B、以及可在设备上运行的模型 EXAONE Deep-2.4B。他们表示:“轻量模型虽然只有 32B 模型大小的 24%,但却能保持 95% 的性能,而搭载在设备上的设备端模型虽然规模只有 7.5%,但性能却达到了 86%。” LG 以“开源” 的方式公开了可以说是人工智能模型设计蓝图的 “源代码”,以便其他开发者能够使用。值得一提的是,Deepseek 也是采用这种开源方式。
LG 虽然开源了,但目前该AI模型仅在企业内部使用 —— 因为要像 Deepseek、OpenAI 那样让普通人也用上,至少需要投入数百亿韩元。LG 计划逐步以 B2B 的形式扩大服务。