NVIDIA 在 GTC 2025 宣布,其Blackwell架构实现了DeepSeek-R1 (6710 亿参数模型)的世界纪录推理性能。
单个 NVIDIA DGX 系统(8×Blackwell GPU):
- 单用户推理速度 超过 250 tokens/秒。
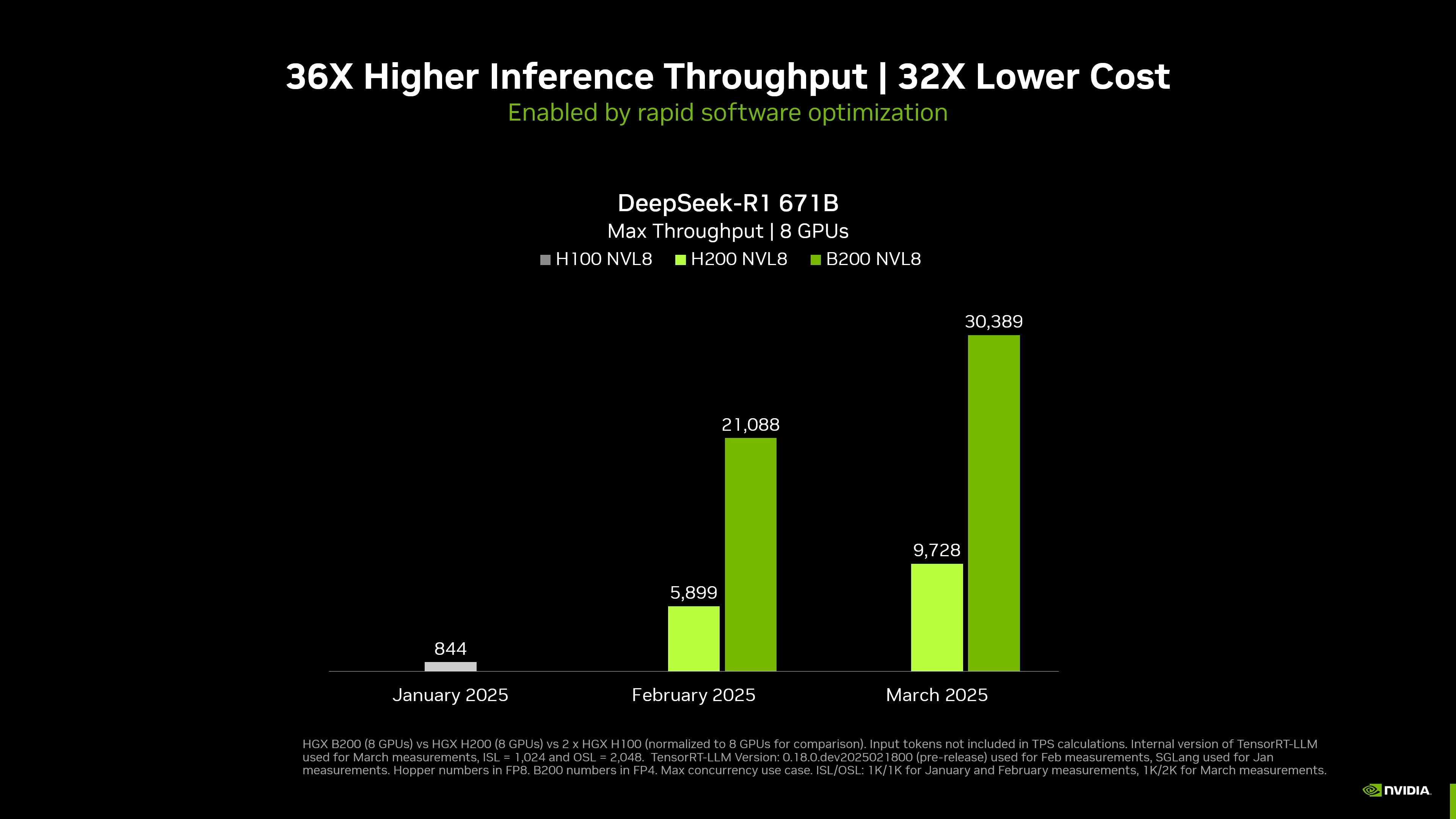
- 最大吞吐量 超过 30,000 tokens/秒。
- 推理吞吐量相比 2025 年 1 月提升 36 倍,推理成本下降 32 倍。
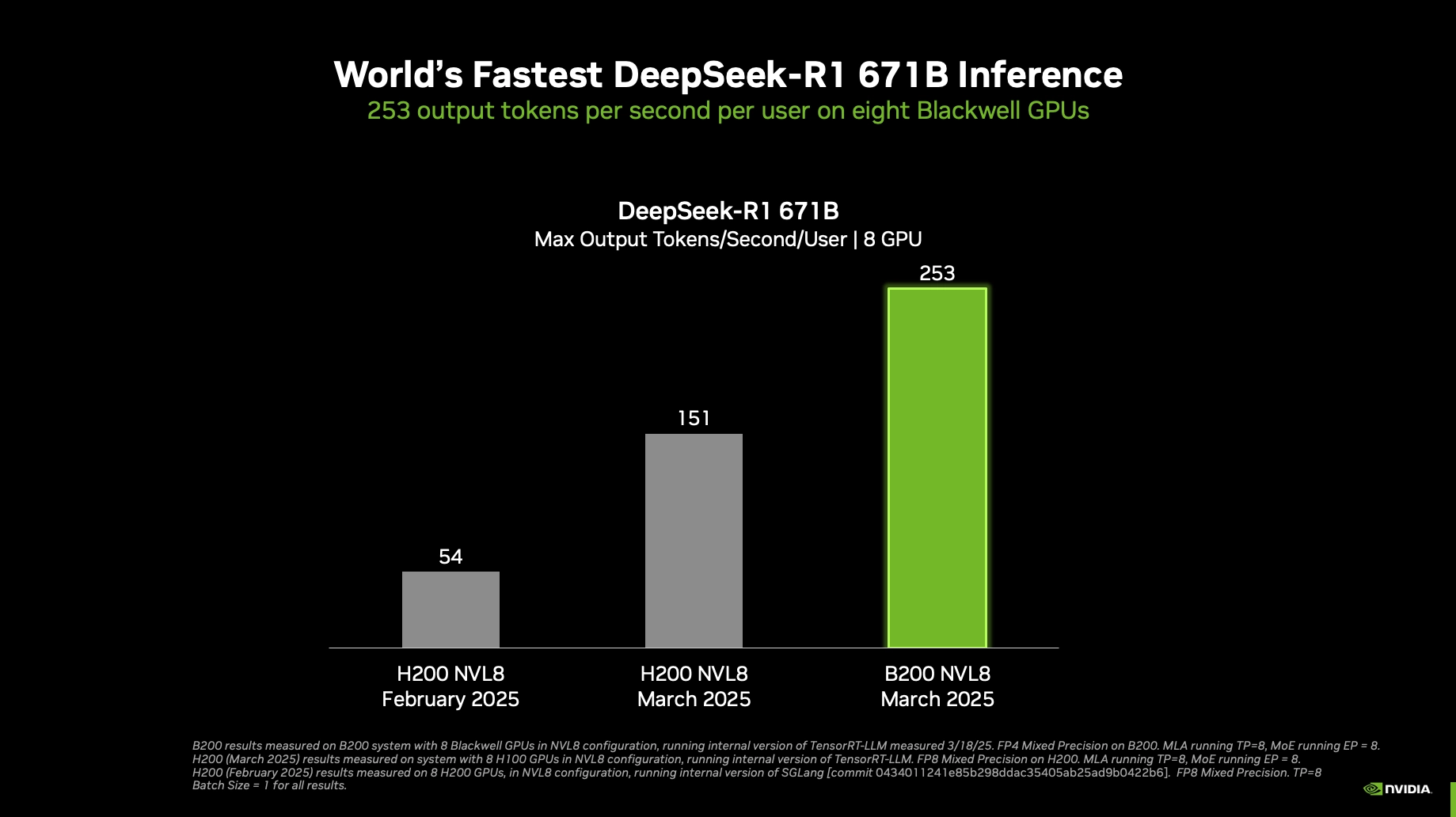
一台配备8个NVIDIA Blackwell GPU的单台DGX系统,在处理6710亿参数的DeepSeek-R1模型时,能够实现每用户超过250个令牌每秒的推理速度,或最高超过3万个令牌每秒的总吞吐量。这一性能在用户体验和效率方面均达到了新的高度。
Blackwell GPU 关键升级
这些性能提升得益于NVIDIA开放生态系统中推理开发工具的优化,特别是针对Blackwell架构的改进。Blackwell架构的硬件和软件协同优化,使得推理性能在短短时间内实现了显著飞跃。
(1) 硬件架构改进
- 第五代 Tensor Core:支持 FP4 精度计算,计算能力提升 5 倍。
第五代 NVLink & NVLink Switch:
- 带宽翻倍(相比上一代 Hopper GPU)。
- 支持更大规模 NVLink 互联,增强多 GPU 协同计算能力。
计算性能 & 存储优化:
- Blackwell FP4 计算比 H100 的 FP8 模式 提高 3 倍推理吞吐量。
在 DeepSeek-R1、Llama 3.1 (405B)、Llama 3.3 (70B) 等模型上表现卓越。

(2) TensorRT-LLM 推理优化
TensorRT Model Optimizer 0.25:
- 支持 FP4 量化(Post-Training Quantization, PTQ),降低计算开销,提高吞吐量。
- 支持量化感知训练(QAT),可在低精度计算下保持高准确率。
TensorRT-LLM 0.17:
- 针对 Blackwell 指令集 进行了专门优化。
- KV Cache 管理、推测解码 等高级优化提高运行效率。
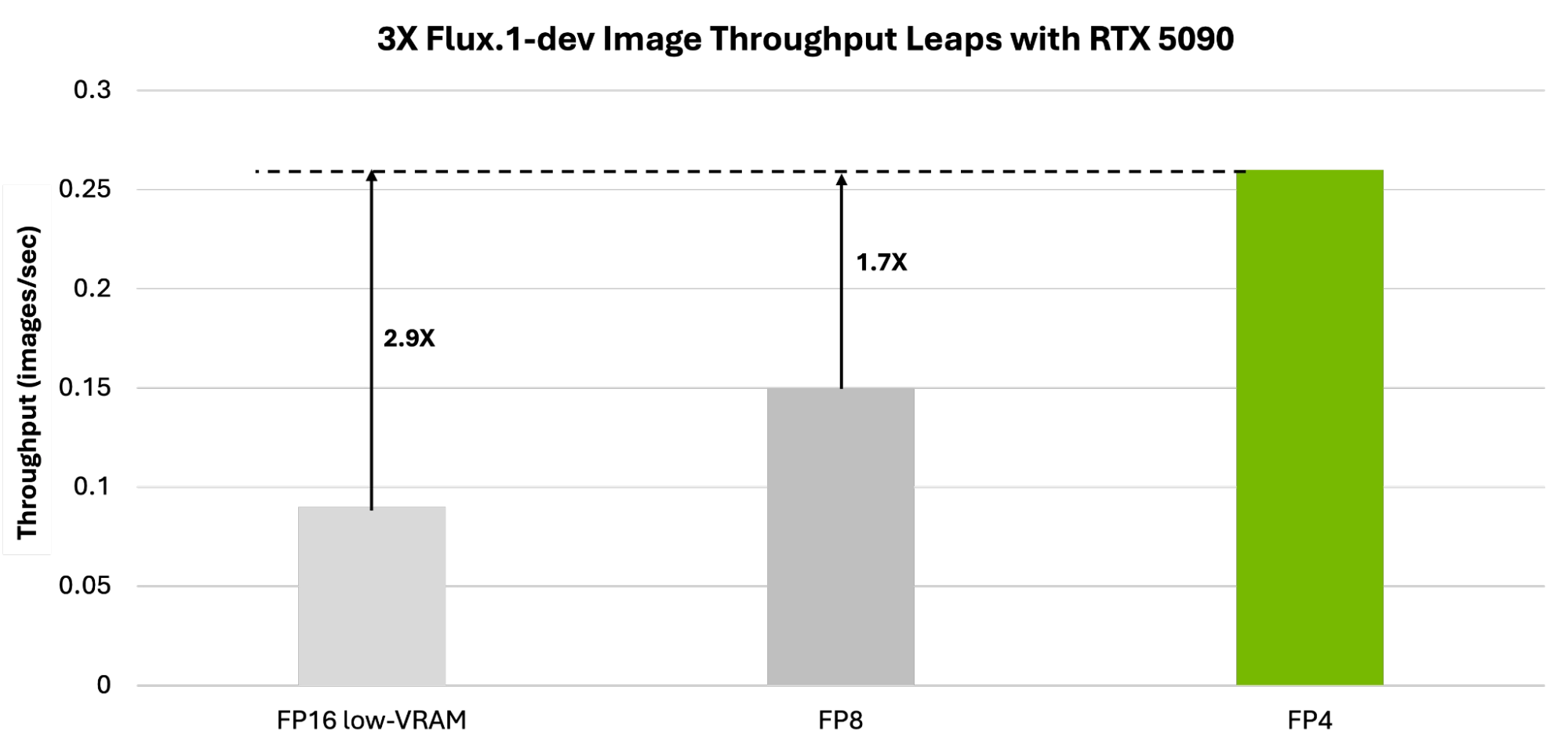
(3) AI 图像生成优化
Blackwell GPU 还针对 AI 图像生成进行了优化:
- 相比 FP16,推理吞吐量提升 3 倍。
- 显存占用优化,VRAM 需求降低 5.2 倍,适用于 RTX 5090 及 AI PC 设备。
支持的模型:
- Flux.1 系列(Black Forest Labs):领先的文本-图像生成模型,可在 TensorRT 生态系统 中直接部署。
(4) 生态系统与软件优化
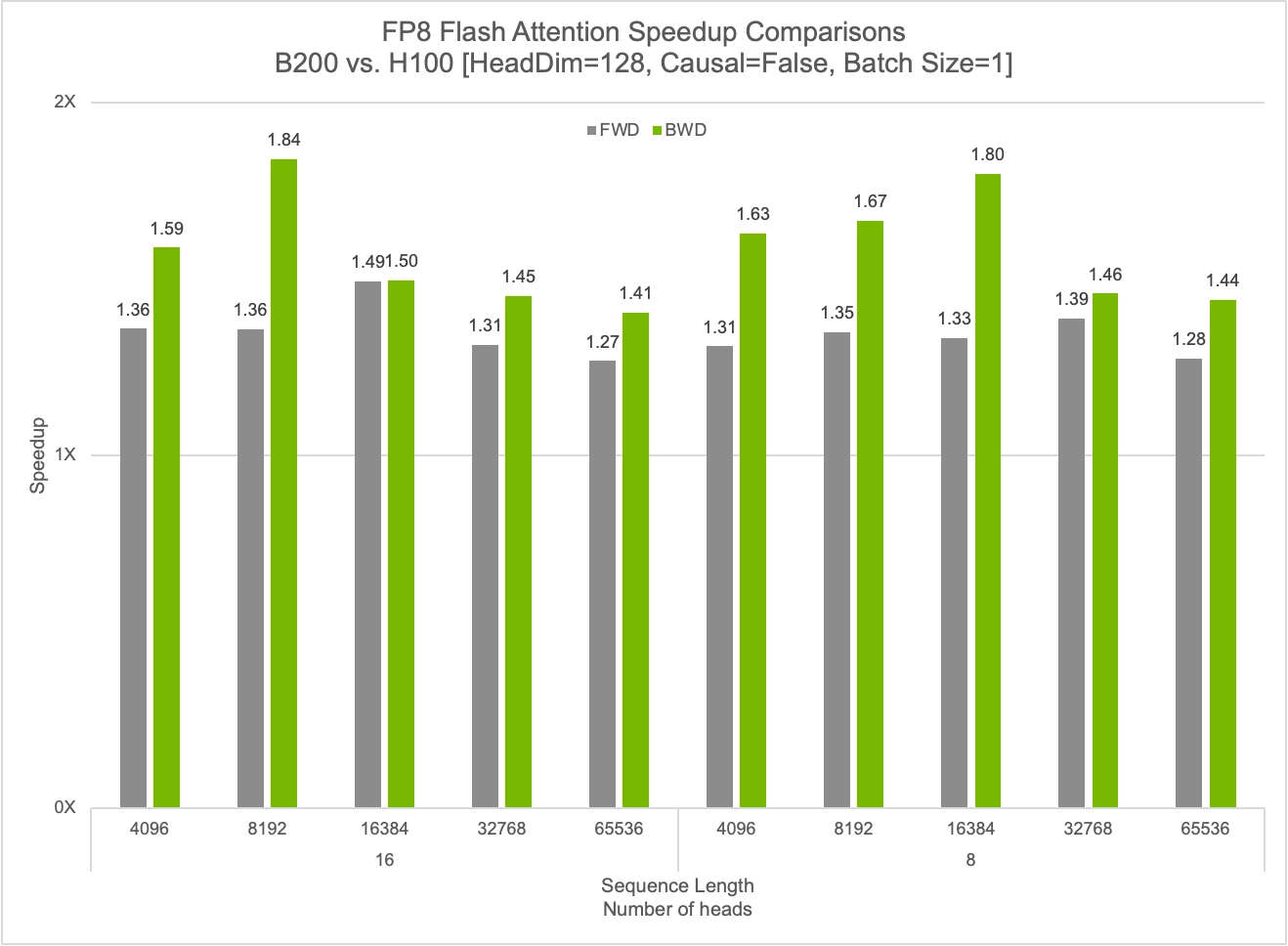
cuDNN 9.7 优化
提供 Flash Attention 算法:
- FP8 前向传播加速 50%。
- FP8 反向传播加速 84%。
GEMM 计算优化,减少 LLM 计算内存占用。
CUTLASS 3.8 优化
- 支持 FP4 计算,优化 MoE 模型计算,降低 LLM 权重存储需求。
支持 OpenAI Triton,Python 级编译器优化 AI 计算。
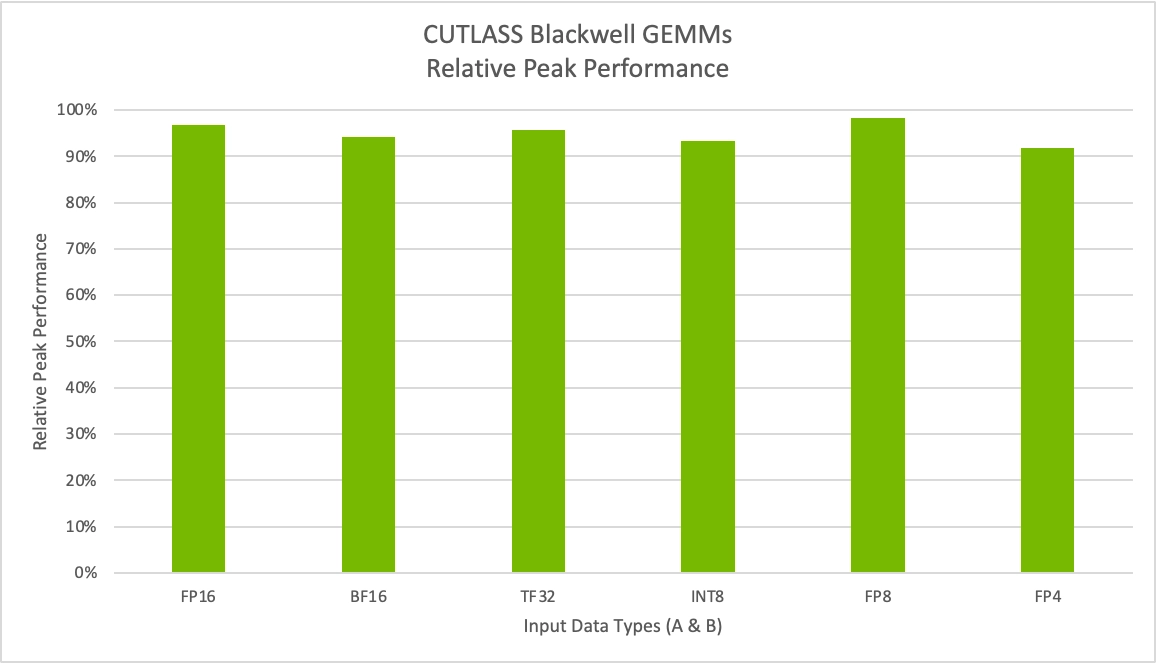
关键推理性能数据
(1) 在 LLM 模型上的吞吐量提升

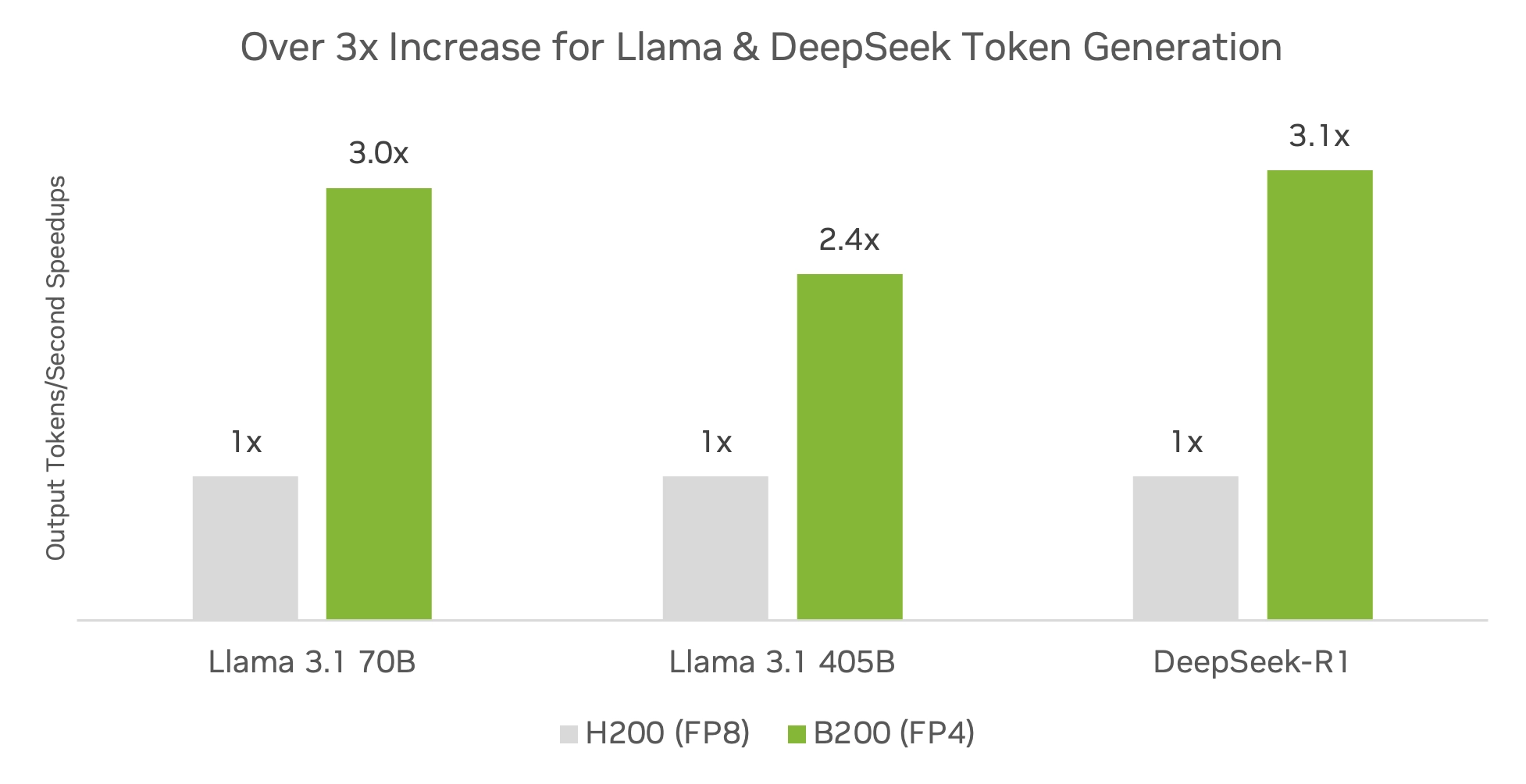
(2) FP4 量化推理的精度评估
DeepSeek-R1 在 FP4 量化后仅损失 0.1-0.5% 精度:
- MMLU、GSM8K、AIME 2024、GPQA、MATH-500 等多个数据集测试表现优异。
- Nemotron 4 (15B & 340B) 采用 FP4 QAT 量化后,几乎无损精度。