Google 宣布在 Google AI Studio 和 Gemini API 上开放 Gemini 2.0 Flash 的原生图像生成功能,以供开发者测试和实验。该模型结合了 多模态输入、增强推理能力和自然语言理解,可以生成高质量的图像,并与文本无缝融合。
它不仅能理解文字,还能直接根据描述生成高质量的图片。支持 文本+图像生成、对话式图像编辑、真实感图片创作、高质量文本渲染。
✅ 多模态能力:可以同时理解文字、图像,并在二者之间建立联系。
✅ 智能推理:能够结合现实世界的知识,生成准确的视觉内容。
✅ 自然语言交互:支持用户通过对话方式调整修改图片,类似 AI 画师助手。
该功能在Gemini 2.0 Flash发布时候预告过↓
Gemini 2.0 Flash 的核心特性
文本与图像结合
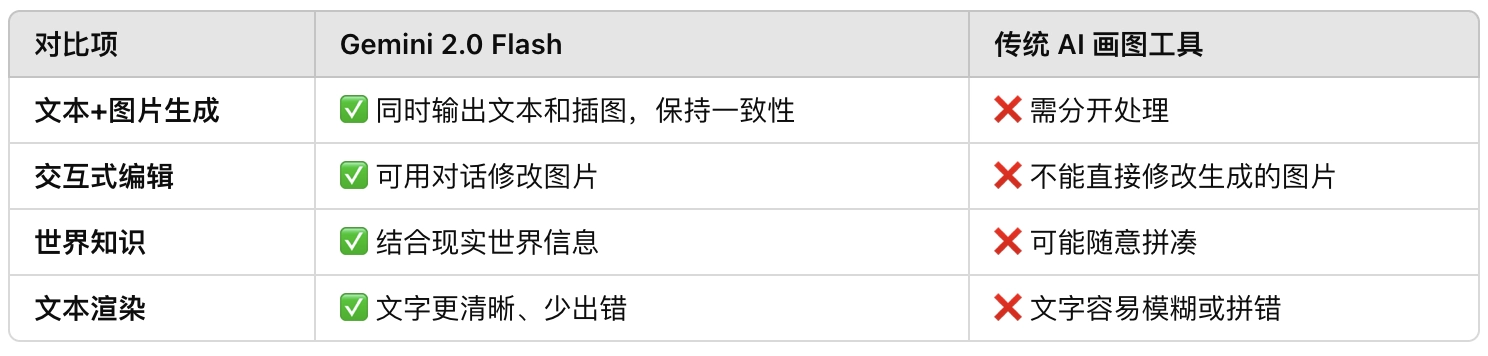
- 用户可输入文本,Gemini 2.0 Flash 不仅能生成相应的故事,还能提供连贯的插图。
- 角色和场景的一致性较强,允许用户通过反馈调整风格或内容。
💡 举例:
- 你输入一段故事:“一只可爱的海龟在海底探险。”
- Gemini 2.0 Flash 会根据文本生成插图,让角色和场景保持一致。
- 你可以要求它 修改绘画风格(如卡通风、写实风等)。
📍 适用场景:
- 童话故事书、互动小说、漫画制作等内容创作。
对话式图像编辑
- 用自然语言修改图像,支持多轮对话交互
💡 举例: 1️⃣ 你让 AI 生成一个蓝色房子 🏠
2️⃣ 你说:“把它的屋顶改成红色。” AI 会自动调整图片。
3️⃣ 你再说:“加一个阳台。” AI 继续修改,并保持风格一致。📍 适用场景:
- 设计师优化草图 🖌️
- 营销人员快速制作广告素材 📢
- 社交媒体创意内容 🎭
世界知识与理解
- 该模型利用增强的推理能力,结合现实世界知识生成符合上下文的图像。
- 相比一般 AI 画图工具,Gemini 2.0 Flash 能理解更多现实细节
💡 举例:
- 你要它画 “意大利披萨”,它不会随便画一个普通披萨,而是 参考真实的意大利风格(如薄脆底、番茄酱、马苏里拉芝士等)。
- 你想生成 某个国家的传统服饰,AI 会尽可能遵循文化特征,而不是随意拼凑。
📍 适用场景:
- 食谱配图(比如生成烹饪步骤插图 🍕)
- 教育类内容(如地理、历史课件 🗺️)
- 电商展示(如服装搭配 🛍️)
📢 ⚠️ 但需注意:尽管 AI 具备大量世界知识,但仍然无法保证 100% 事实正确性,使用时需要人工检查。
高质量文本渲染
- 现有的大多数图像生成模型在生成长文本时存在排版混乱、字符错误等问题。
- Gemini 2.0 Flash 通过内部基准测试显示出比主流竞品更强的文本渲染能力,比传统 AI 画图工具更擅长绘制带文字的图片,不会出现字符模糊、错别字等问题。
💡 举例:
- 你需要 生成一张广告海报,要求写上“50% OFF”+ 商品图
- 传统 AI 可能会把 “50%” 画得模糊不清,甚至拼错
- Gemini 2.0 Flash 能更精准地渲染出清晰、规范的文本
📍 适用场景:
- 广告、海报(如促销宣传)
- 社交媒体内容(如 Instagram、微博配图)
- 电子请柬、邀请函(如婚礼请柬、活动宣传)
Gemini 2.0 Flash 的优势
适用人群
🎨 设计师 → 快速生成和调整插图
📝 内容创作者 → 用 AI 生成故事+图片
📊 市场营销人员 → AI 生成海报、广告
👩🏫 教育工作者 → 生成教学图解、科普内容
🎮 游戏开发者 → 设计角色、场景概念图
如何开始使用 Gemini 2.0 Flash 进行图像生成
开发者可以通过 Gemini API 访问该功能,并在 Google AI Studio 中进行实验。示例代码:
``` from google import genai from google.genai import types
client = genai.Client(apikey="GEMINIAPIKEY") response = client.models.generatecontent( model="gemini-2.0-flash-exp", contents=( "Generate a story about a cute baby turtle in a 3D digital art style. " "For each scene, generate an image." ), config=types.GenerateContentConfig( response_modalities=["Text", "Image"] ), ) ```
该 API 支持在同一模型内同时生成文本和图像,使开发者可以轻松构建包含 AI 视觉内容的应用。
📍 适合开发者:
- 创建 AI 互动故事 🏰📖
- 制作 AI 插图应用 🎨
- 开发 AI 视觉助手 🤖