Google 发布其开源模型系列最新模型 Gemma 3。Gemma 3是一个高性能、可移植的轻量级 AI 模型,适用于单 GPU 或 TPU 部署,支持多语言和复杂任务。
可用于聊天 AI、代码生成、文本理解、多模态分析等任务。
💡 核心特性
- 支持 140+ 语言,涵盖全球大部分主要语言。
- 增强文本和视觉推理能力,可理解文本、图片、短视频,适用于内容审核、视觉分析。
- 128K-token 上下文窗口,适合处理长文本和复杂上下文任务。
- 支持函数调用(Function Calling),支持AI 代理(Agents)开发,自动执行任务。
- 提供量化(Quantized)版本,提升推理速度,更小、更快,适用于边缘计算 & 移动设备。
Gemma 3 相比其他模型的优势
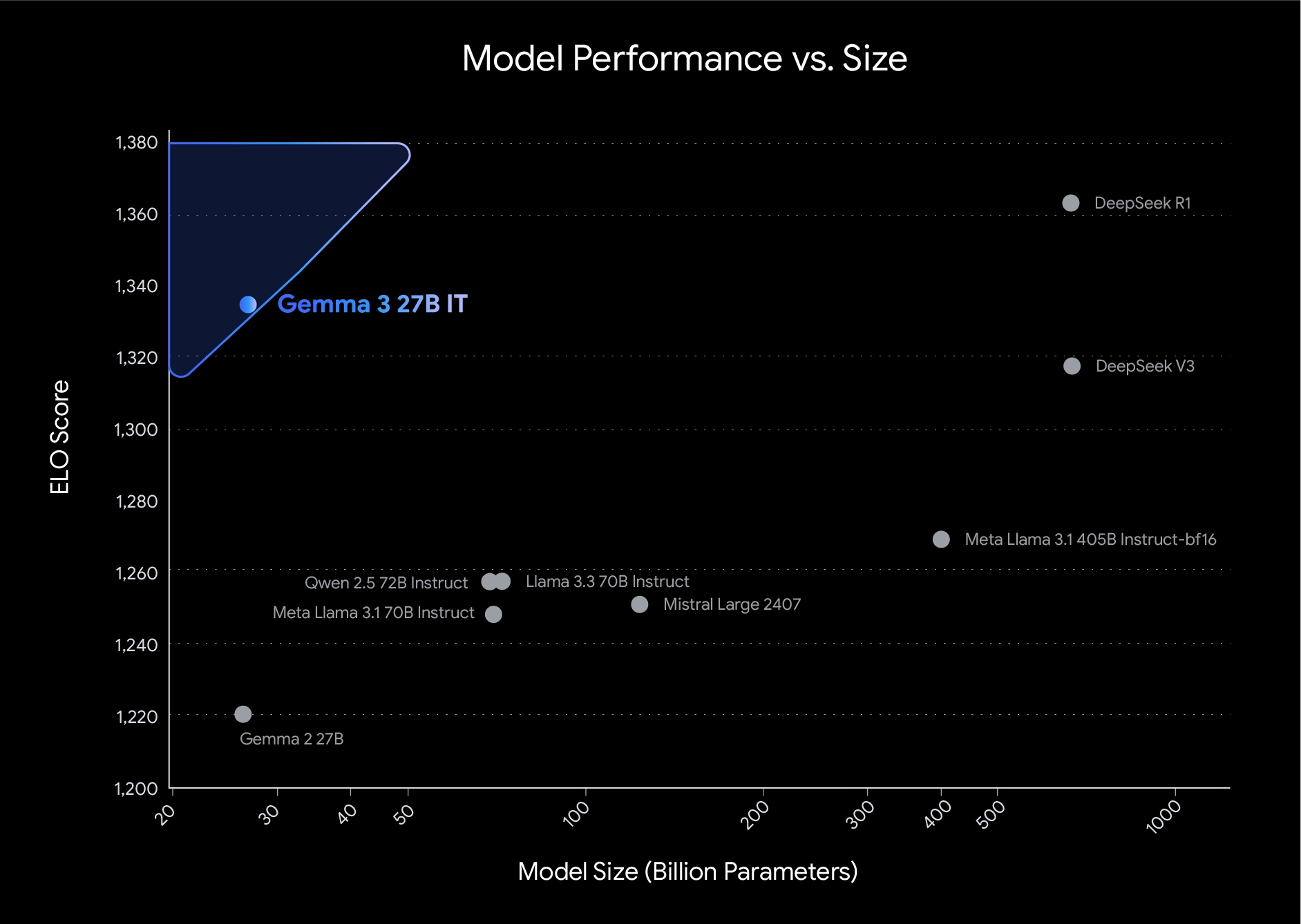
Gemma 3 在多个 AI 评测榜单上超越了 Llama 3-8B、DeepSeek-V3、Mistral 7B,并且能够在单 GPU 上运行。
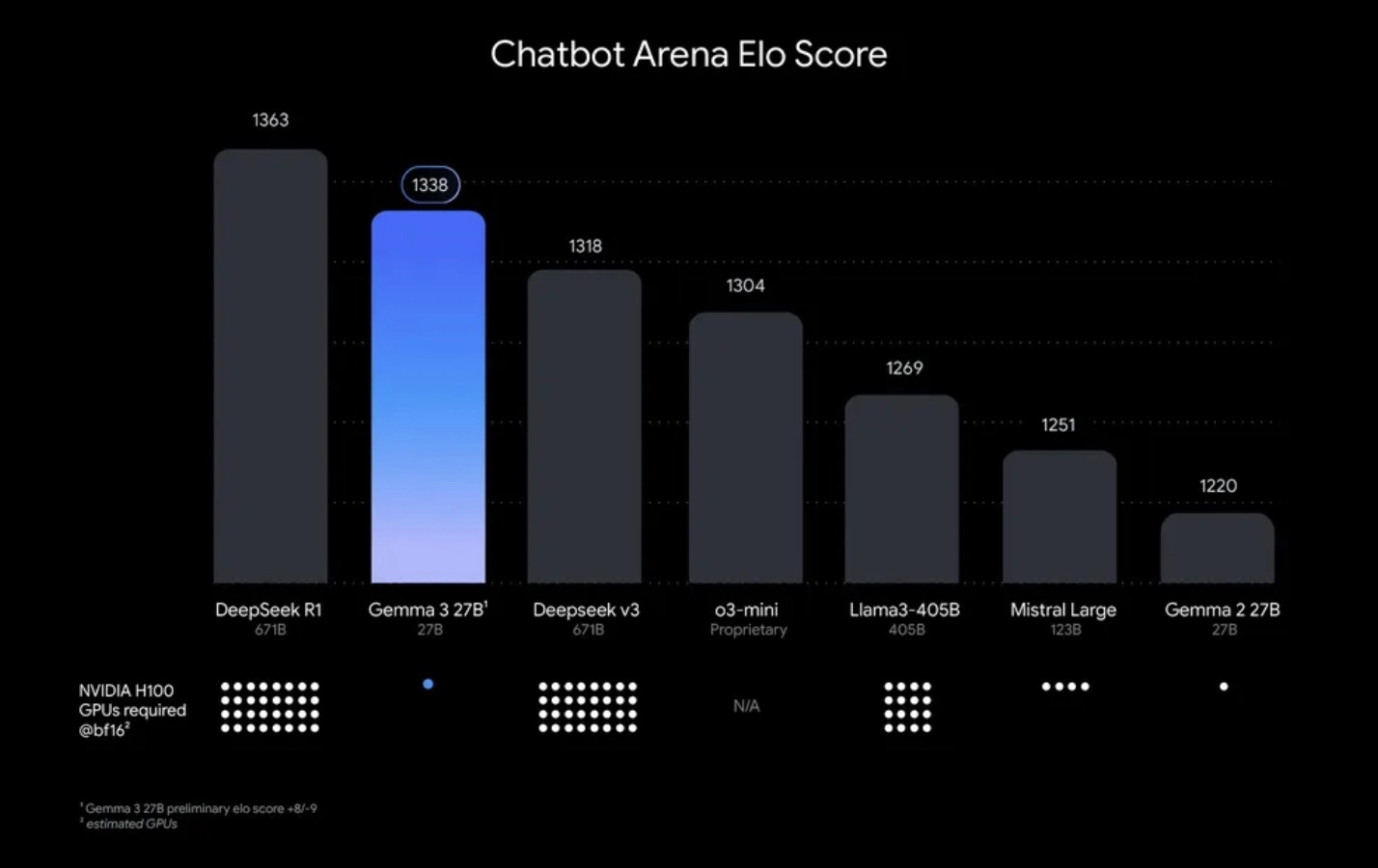
✅ 比 Llama 3 更快,比 Mistral 7B 更强大,适合 高效 AI 计算。
✅ 单 GPU 运行,超低成本,适用于 本地推理、边缘计算、智能设备。
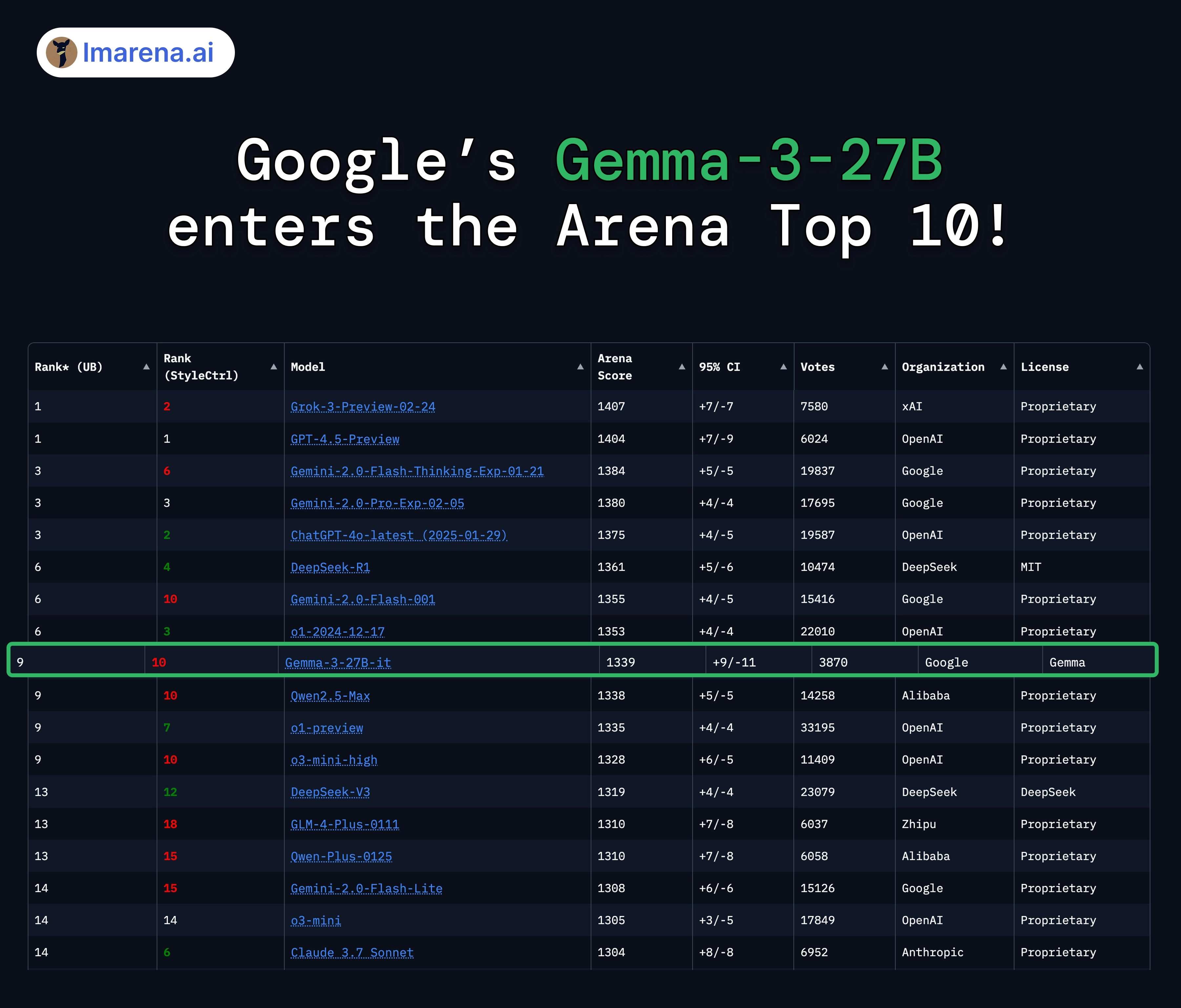
竞技场排名
Gemma-3-27B 综合排名前 10 -
超越许多仅有 27B 参数的专有模型
是第二佳开源模型,仅次于 DeepSeek-R1
主要特点
Gemma 3 在性能、功能和适用性上带来显著提升,以下是核心亮点:
模型规模与灵活性
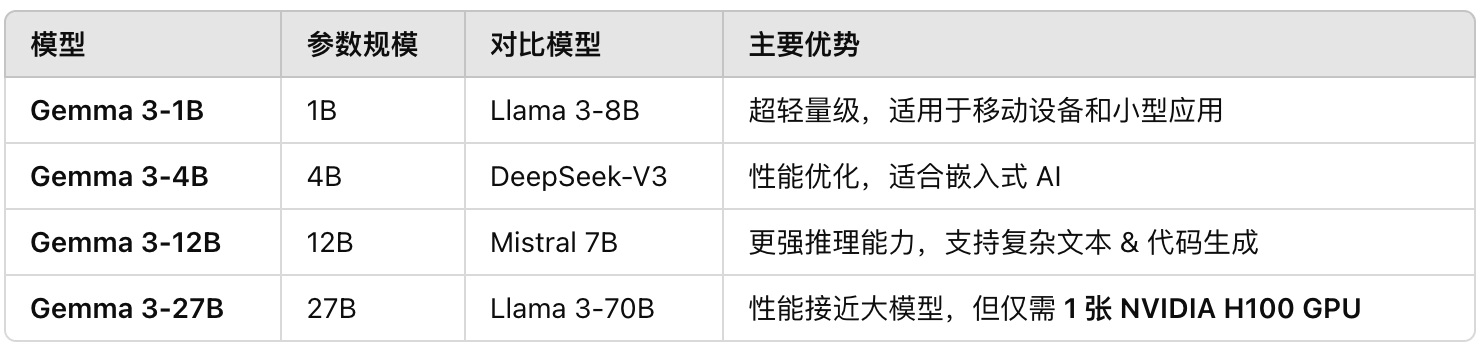
- 参数规模:提供 1B(10 亿)、4B(40 亿)、12B(120 亿)和 27B(270 亿)四种参数版本,开发者可根据硬件和性能需求选择合适的模型。
- 便携性:专为直接在设备上运行而设计,支持手机、笔记本电脑和工作站等,减少对云端计算的依赖。
- Gemma 3 27B 仅需 1 张 NVIDIA H100 GPU即可运行,相比其他模型(如 Llama 3 70B)所需的 32 张 H100,计算成本大幅降低。
多模态与多语言支持
- 多模态能力:支持文本和图像输入(1B 版本仅支持文本),可处理图像分析、短视频理解等任务,适用于问答、文档总结等场景。可分析图片、短视频、文本,用于内容审核、SEO、视频智能处理。
- 语言覆盖:开箱支持 35 种语言,预训练覆盖超过 140 种语言,助力开发者构建全球化应用。
扩展上下文窗口
- 上下文长度:提供高达 128k token 的上下文窗口(1B 版本为 32k),能处理大量信息,适合复杂任务如长文档分析。
功能调用与结构化输出
- 新功能:支持函数调用和结构化输出,便于自动化任务和构建智能代理(如工作流程助手)。
性能优化
- 量化模型:提供官方量化版本,减小模型体积和计算需求,同时保持高精度,适合资源受限环境。
- 高性能:27B 模型在 Chatbot Arena Elo 分数上名列前茅,仅需单张 NVIDIA H100 GPU 即可运行,相比其他需要多达 32 张 GPU 的模型更高效。
模型架构改进
- 多模态设计:4B、12B 和 27B 版本整合了 SigLIP 图像编码器,将图像转化为 token,与语言模型无缝结合。文本采用单向注意力(因果注意力),图像采用双向全注意力,提升视觉理解能力。
- 上下文扩展:通过预训练 32k token 序列,并在后期将 4B 以上版本扩展至 128k token,优化了 RoPE(旋转位置嵌入)基频(从 10k 提升至 1M)并调整超参数(如局部与全局注意力层比例从 1:1 改为 5:1,窗口大小从 4096 减至 1024),在不牺牲性能的情况下降低内存需求。
多语言优化
- 数据集升级:预训练数据中的多语言内容翻倍,提升了语言覆盖广度和质量。使用的 tokenizer 与 Gemini 2.0 一致,确保兼容性和一致性。
官方介绍:https://blog.google/technology/developers/gemma-3
模型下载:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
在线体验:https://huggingface.co/spaces/huggingface-projects/gemma-3-12b-it
技术报告:https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf