近日,字节跳动豆包大模型团队联合M-A-P开源社区发布SuperGPQA,一个覆盖285个研究生级学科、包含26,529道专业问题的知识推理基准测试。


该数据集不仅涵盖数学、物理等主流学科,还首次将轻工业、农业、服务科学等长尾学科纳入评估体系,填补了现有基准测试在长尾知识领域的空白。SuperGPQA已被用于揭示开源与闭源模型的性能差距,成为AI发展的重要工具。
传统基准如MMLU和GPQA学科覆盖不足50个,长尾学科占比不到5%,且因数据来源单一(如维基百科)和众包标注不可靠,难以衡量模型在复杂场景中的推理能力。SuperGPQA通过专家-LLM协同机制,从权威来源筛选问题,历时半年构建而成。其题目平均提供9.67个选项,42.33%需数学计算或形式推理,兼具广度与深度。实验显示,最优模型DeepSeek-R1准确率仅61.82%,表明当前大语言模型在多样知识领域仍有提升空间。
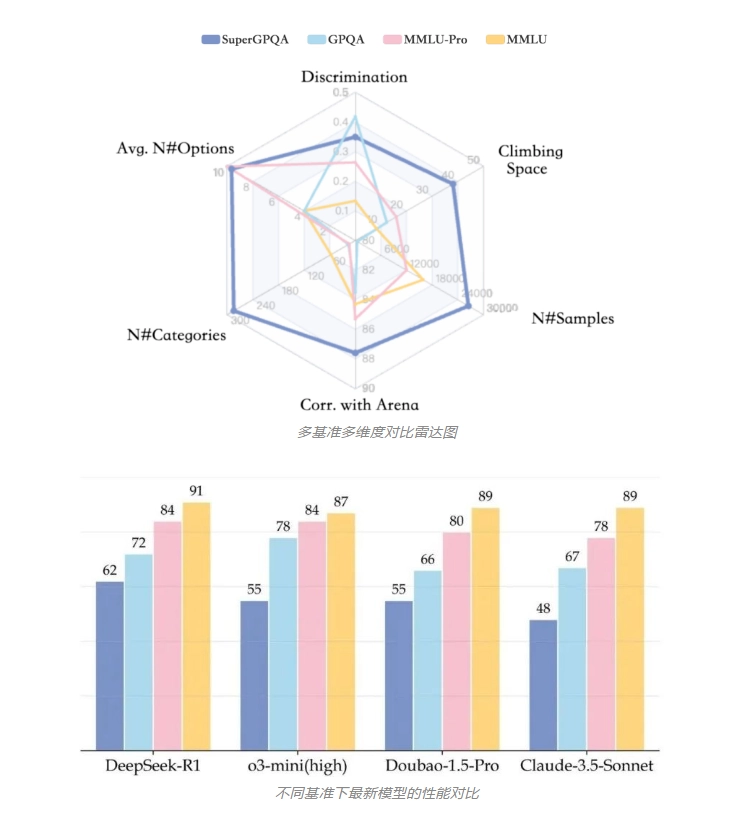
SuperGPQA采用三阶段流程提升质量:专家筛选原始问题、规范化转录、多层质量检验(规则过滤、LLM检测、专家复审)。评测结果表明,指令微调显著提升性能,如DeepSeek-V3得分超基础版,但开源模型在困难题目上仍落后闭源方案。
论文链接:https://arxiv.org/pdf/2502.14739
数据链接:https://huggingface.co/datasets/m-a-p/SuperGPQA
代码链接:https://github.com/SuperGPQA/SuperGPQA