跨越语音“恐怖谷”
在语音合成技术的发展中,有一个长期存在的挑战——“恐怖谷效应”(Uncanny Valley)。
当人工合成的语音接近真实人声但仍然存在微小差异时,人类会感到奇怪或不适,这就是所谓的“恐怖谷效应”。
Sesame 公司的目标是研发一种语音模型,跨越这一“恐怖谷”,让用户感到与AI的语音交互如同与真人对话般自然。他们提出了“语音存在感”的概念,指语音交互中让人感到真实、被理解和被重视的特质。他们希望通过技术创新,让AI语音不仅听起来像人,还能在情感和语境上与用户产生共鸣。
实现“语音存在感”的三大核心要素:
- 情商(Emotional Intelligence):模型需能感知并回应用户的语气、情绪和对话背景。例如,当用户表现出开心或沮丧时,AI能相应调整语调和内容。
- 低延迟(Low Latency):为了让对话流畅自然,AI的响应时间必须极短,接近人类对话中的即时反应。
- 语音质量(Voice Quality):声音需逼真且富有表现力,避免机械感,同时保留细腻的语调变化。
为了实现这些目标,Sesame开发了对话语音模型(Conversational Speech Model,简称CSM)。该模型采用端到端的多模态学习方法,利用Transformer架构,结合对话历史生成更自然、连贯的语音输出。与传统的文本转语音(TTS)模型不同,CSM不仅关注高质量的音频生成,更强调对上下文的实时理解和适应,从而解决了传统模型在多样性和情境适应性方面的不足。
Sesame 公司展示了他们最新的研究成果,他们使用了约100万小时的公开音频数据进行训练了一个语音模型,它在个性、记忆、表达能力和恰当性上表现出了非常惊人的能力。
Sesame 演示(Demo)的语音合成质量已经超越OpenAI的高级语音模式(Advanced Voice Mode)。
Sesame 研究想解决什么问题?
目前的**语音合成(Text-to-Speech, TTS)**技术已经很先进,但仍然存在以下问题:
- 声音僵硬、生硬:尽管许多语音合成系统能够模仿人类语音,但它们仍然缺乏自然的流畅度、音调变化和情感表达。
- 缺乏情感和个性:许多TTS系统听起来像是机器人在说话,而不是一个有真实情感的人。
- 令人不适的“恐怖谷”效应:当合成语音接近真人但仍有微小瑕疵时,反而让人觉得怪异,不如明显“合成”的声音那样让人接受。
Sesame 的研究目标就是让合成语音更真实、更具表现力,让人听起来更像真人说话,而不会让人感到奇怪或不适。
使其能够:
- 情感智能(Emotional Intelligence):识别和回应对话中的情感,避免机械化、平淡的语调。
- 对话动态(Conversational Dynamics):掌握自然的语速、停顿、打断和重音处理,让对话更流畅。
- 情境感知(Contextual Awareness):根据上下文调整语音的语气、风格和表达方式。
- 个性一致性(Consistent Personality):保持一致的语音特征,不因不同情境而变得不协调。
主要特点
🔹 更加自然的语音
- 他们的技术可以模仿真实人声的语调、节奏和音色,使得合成语音听起来像真人说话,而不是机器朗读。
- 目前已有的语音合成模型可能会语调单一,缺乏变化,而 Sesame 似乎已经解决了这个问题。
🔹 细腻的情感表达
- 他们的模型不仅能读出文字,还能加入情感、停顿、重音等自然元素。
- 例如,合成的声音可以传达愤怒、悲伤、兴奋等不同的情绪,让对话更有感染力。
🔹 可能超越现有最强语音合成技术
- Sesame 的演示(Demo)表明,他们的语音合成质量可能已经超越OpenAI的高级语音模式(Advanced Voice Mode)。
- 这意味着 Sesame 可能开发了一种更先进的AI语音模型,使得合成声音更加接近真人。
该研究是如何实现的?
目前使用 Transformer 模型处理音频的一种方法是将连续的波形转换为离散的音频标记(tokens)。多数当代方法(1,2)依赖两种音频标记:
- 语义标记(Semantic tokens):紧凑的、与说话者无关的表征,捕捉语义和语音特征。其高压缩特性可以保留语音的核心信息,但可能牺牲高保真度。
- 声学标记(Acoustic tokens):编码细粒度的声学细节,使得高保真音频重建成为可能。这些标记通常通过 Residual Vector Quantization(RVQ) 生成 2。
传统方法首先预测语义标记,然后使用 RVQ 或基于扩散的方法生成音频。然而,这种分离方法存在局限性:语义标记需要完整地捕捉韵律信息,而训练过程中很难确保这一点。
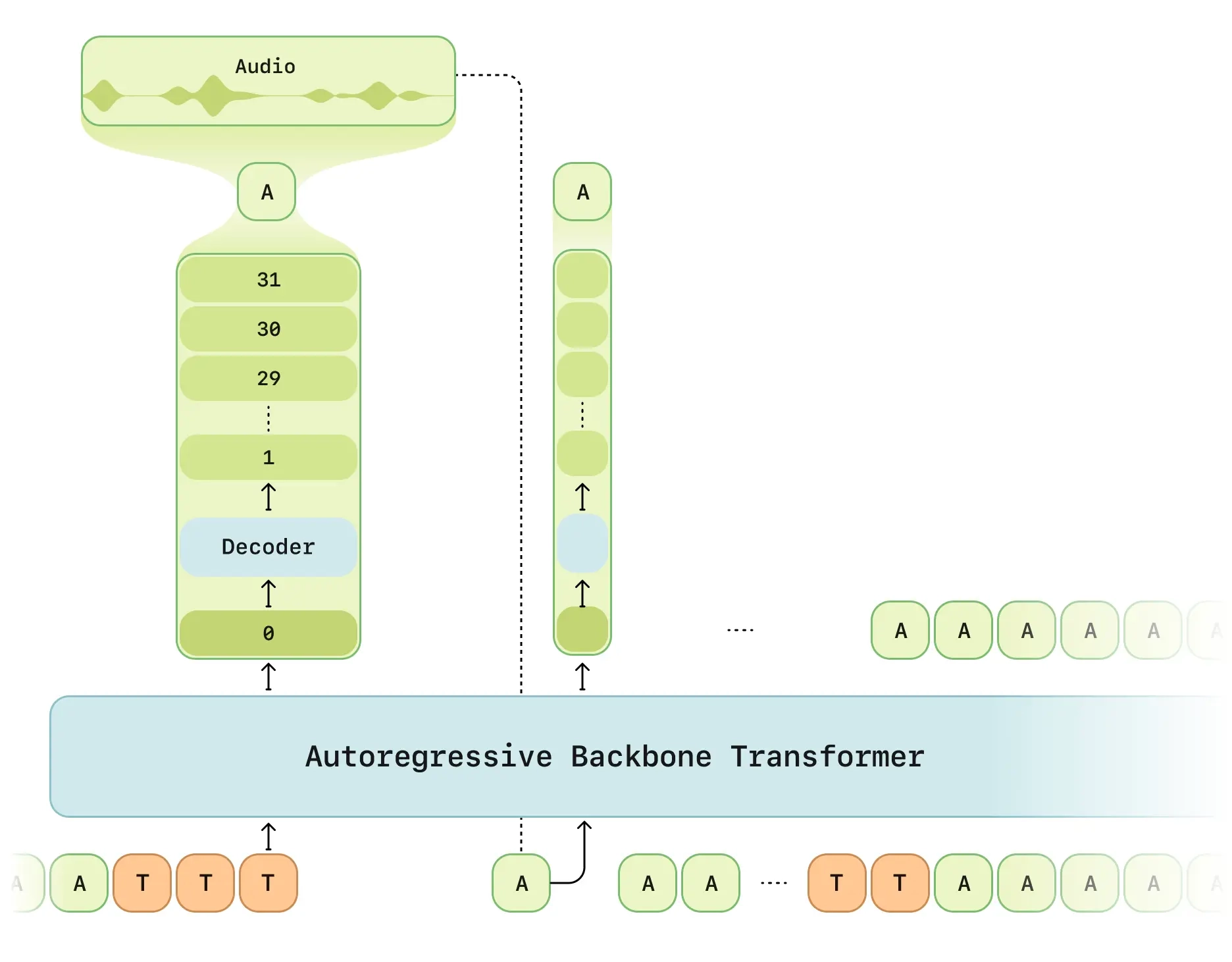
对话语音模型(CSM)
CSM 采用 多模态(文本 + 语音)方法,并直接在 RVQ 语音标记上运行。受到 RQ-Transformer 4 的启发,设计了 两阶段 Transformer 结构:
- 主干 Transformer(Backbone) 处理交错的文本和音频输入,并预测零级(zeroth level)声学标记。
- 音频解码器(Decoder) 预测剩余的声学标记(N-1 级),并利用主干的表征重建语音。
解码器比主干模型小得多,从而在保证端到端训练的同时实现低延迟生成。
模型规模
- Tiny:1B 主干,100M 解码器
- Small:3B 主干,250M 解码器
- Medium:8B 主干,300M 解码器
CSM 的核心突破点在于:
- 端到端的多模态 Transformer 架构
- 基于 Residual Vector Quantization (RVQ) 的音频编码
- 改进的语音-文本交互机制
- 计算优化和低延迟推理
主要技术方法:
端到端的多模态学习(End-to-End Multimodal Learning):
- 直接从文本输入生成高质量语音,而不需要额外的中间处理步骤(如传统 TTS 需要的“文本分析 -> 语音合成”分离过程)。
- 以 Transformer 模型 为核心,使 AI 语音具备上下文感知能力,即 AI 语音不仅能单独朗读文本,还能理解前后语境,调整语气。这种方法帮助模型更好地理解对话的背景和情感,从而让AI的语音显得更加自然和具有互动性。
技术细节
采用 LLaMA 变体 Transformer 结构:
- 文本部分使用 LLaMA Tokenizer 进行处理。
- 语音部分使用 Mimi Tokenizer 进行编码,采用 RVQ 量化技术(详见下文)。
多模态输入(文本 + 语音):
- 传统 TTS 仅基于文本生成语音,而 CSM 可以同时输入文本和语音历史记录,使其具备上下文感知能力。
训练方式:
- 采用 交错式文本-语音训练:训练数据包括文本 + 语音片段交替输入使模型能预测自然语言中语音的节奏、停顿、情感变化等。
基于 Residual Vector Quantization(RVQ)的音频编码
CSM 采用了一种先进的 Residual Vector Quantization(RVQ) 音频编码方法,使得生成的语音更加自然,并降低计算复杂度。
RVQ 的核心机制
在语音合成中,AI 需要将音频转换成可以处理的数值格式。Sesame 采用了两种类型的音频 Token(令牌):
语义 Token(Semantic Tokens):
- 代表语音的语义和发音特征,但不包含具体的音色信息。
- 这种 Token 经过压缩处理,使其可以高效地编码语音的大致结构。
声学 Token(Acoustic Tokens):
- 代表语音的细节,如音高、音色、韵律等。
- 这些 Token 通过 Residual Vector Quantization(RVQ) 进行编码,能够保留更多声音特征,使语音合成听起来更自然。
传统方法的问题
- 许多 TTS 系统采用 二阶段建模,先预测语义 Token,再预测声学 Token。
但这种方法存在**信息瓶颈(Bottleneck)**问题,即:
- 语义 Token 需要编码所有的韵律和音色,但它们本质上是压缩的,导致信息丢失。
- 声学 Token 仅能补充部分丢失的信息,最终合成的语音仍然缺乏真实感。
CSM 的创新点
CSM 采用了一种新方法:
- 端到端的 Transformer 直接预测 RVQ Token,避免语义 Token 的瓶颈问题。
RVQ 逐层优化策略:
- 采用 层级式 RVQ 训练,在不同层次分别预测语音的核心特征和细节特征。
- 例如:第一层负责语调,第二层负责韵律,第三层负责音色。
- 这样可以避免信息丢失,并提升语音的自然性。对话动态建模(Conversational Dynamics Modeling):
- 对话不仅仅是语音的输入输出,还是一个复杂的动态过程。Sesame的技术特别关注如何模拟人类在对话中的自然停顿、语速、重音等因素。这些对话动态增强了语音交互的真实感和互动感。
- 例如,AI可以根据用户的语气和语速调整响应的方式,使得对话听起来不僵硬,更加符合人类对话的自然节奏。
计算优化与低延迟推理
为了在实际应用中降低计算成本,CSM 进行了多项优化,使其具备实时语音合成能力。
计算优化方法
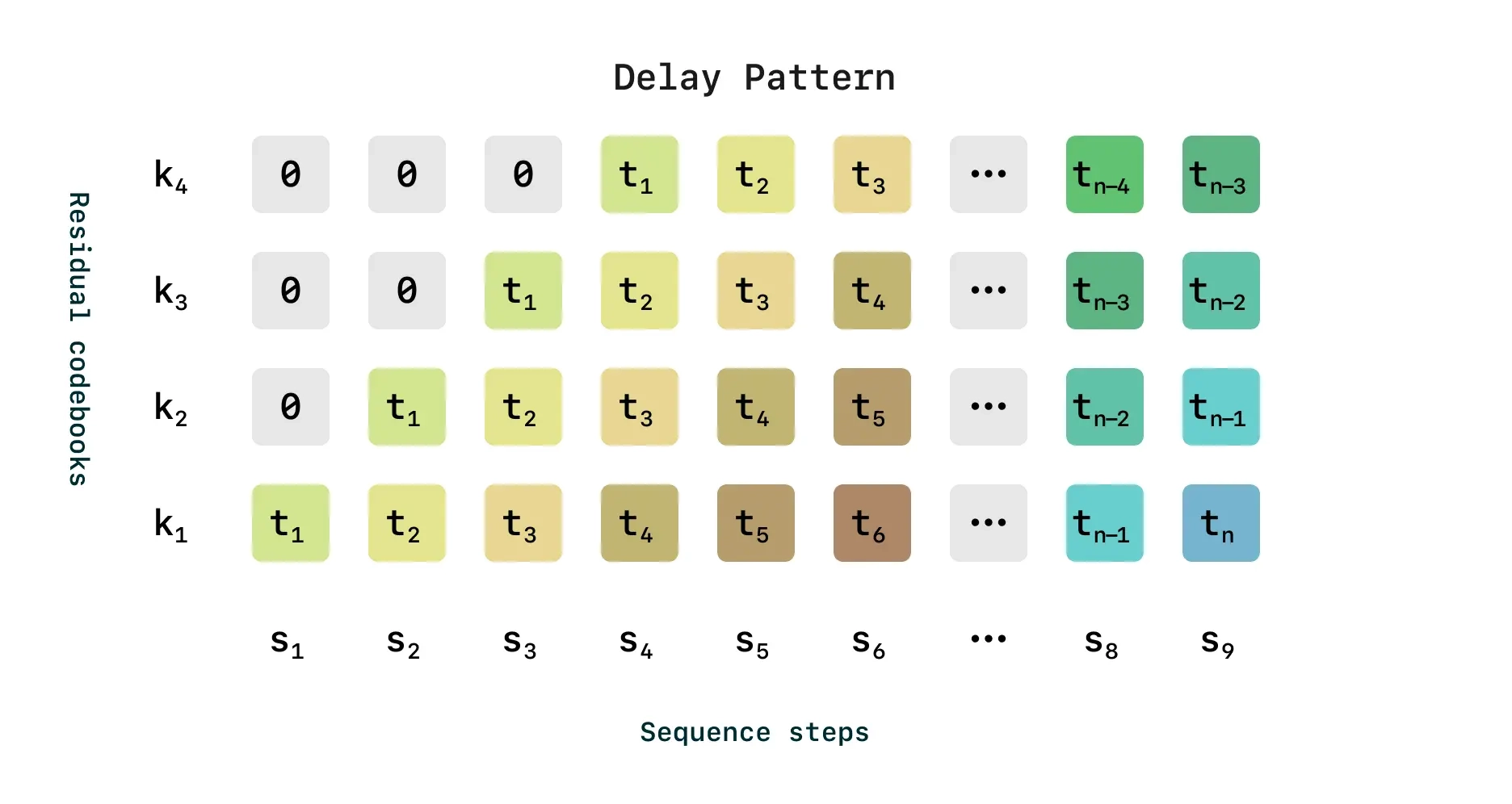
延迟模式优化(Delay Pattern Optimization):
- RVQ 需要多个编码步骤,传统方法计算量大,生成时间长。
- Sesame 采用了一种延迟模式(Delayed Pattern),让较低级别的 RVQ 层先计算,然后再依次计算更高层的细节特征,使得推理更快。
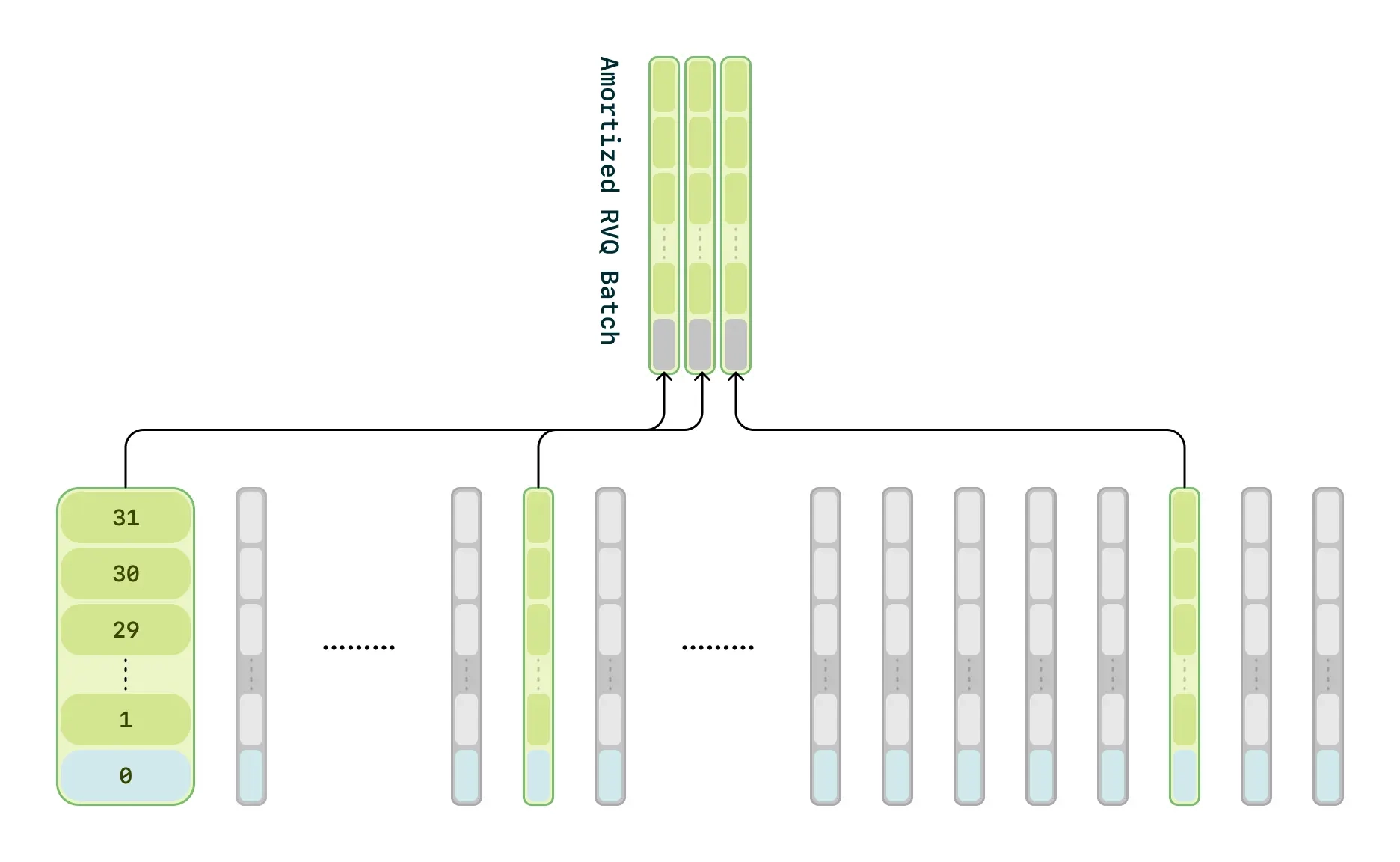
计算分摊(Compute Amortization):
- 在训练阶段,CSM 并不处理所有的音频帧,而是随机采样 1/16 的音频帧进行优化。
- 这大幅减少了计算需求,但不会影响音频质量。
两阶段 Transformer 结构:
采用主干 Transformer(Backbone) 和 轻量级解码器(Decoder) 组合方式:
- 主干 Transformer 处理文本与音频信息,预测音频基础结构。
- 解码器 只负责对音频进行细化,使得计算量更小,推理速度更快。
评估结果
客观指标
传统基准饱和
• 词错误率(WER)和说话者相似性(SIM)等传统指标已接近人类水平,现代模型(包括CSM)表现趋于饱和,难以通过这些指标区分优劣。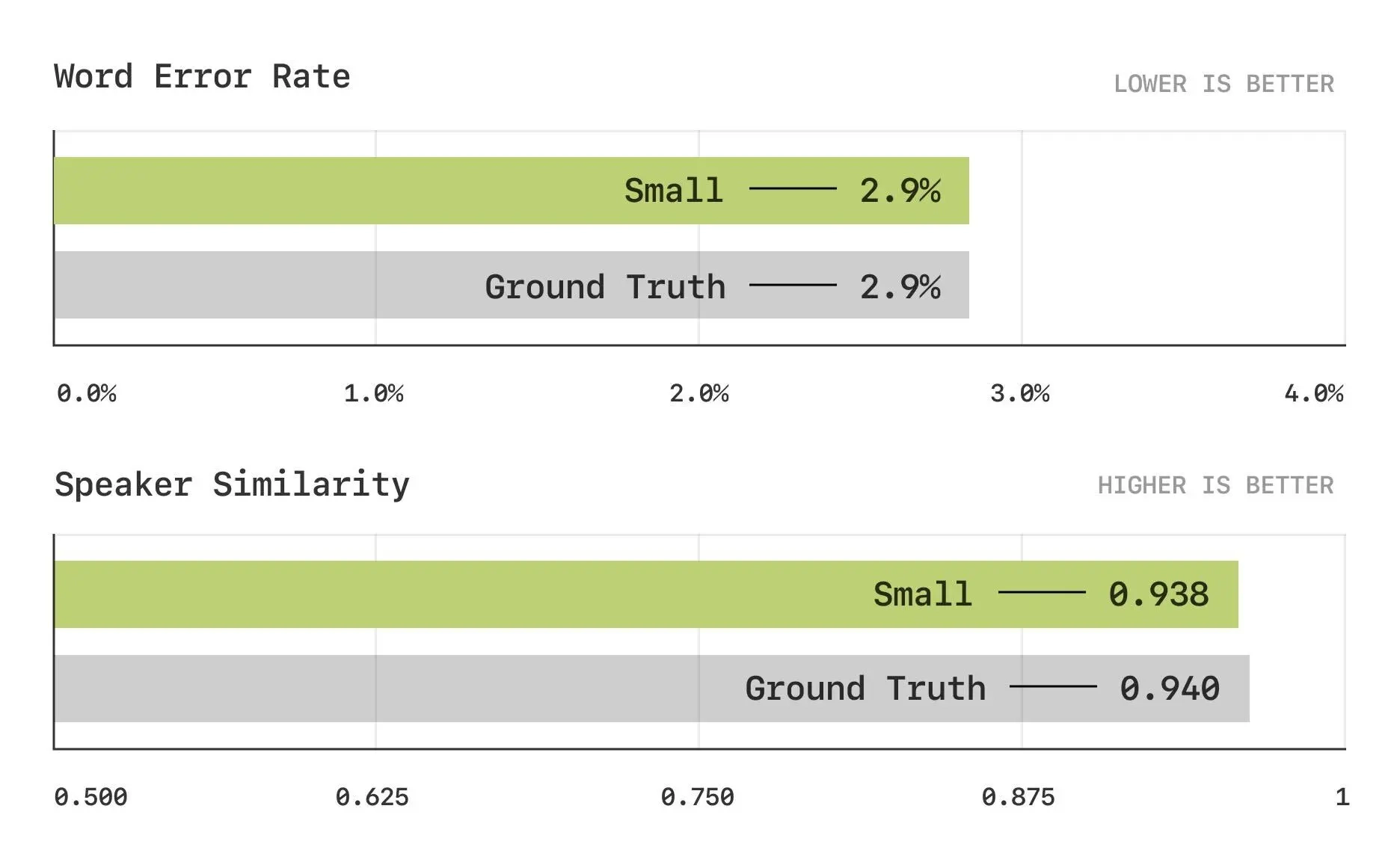
新基准表现
• 同形异义词消歧:测试模型对拼写相同但发音不同的词(如“lead” /lɛd/ 或 /liːd/)的正确发音能力。CSM在200个样本上的准确率随模型规模提升而提高(小型到大型模型表现递增)。
• 发音一致性:测试模型在多轮对话中对发音变体(如“route” /raʊt/ 或 /ruːt/)的连贯性。同样,200个样本显示大型模型表现优于小型模型。
• 对比Play.ht、Elevenlabs和OpenAI,CSM在这些新指标上显示出随规模增长的优势。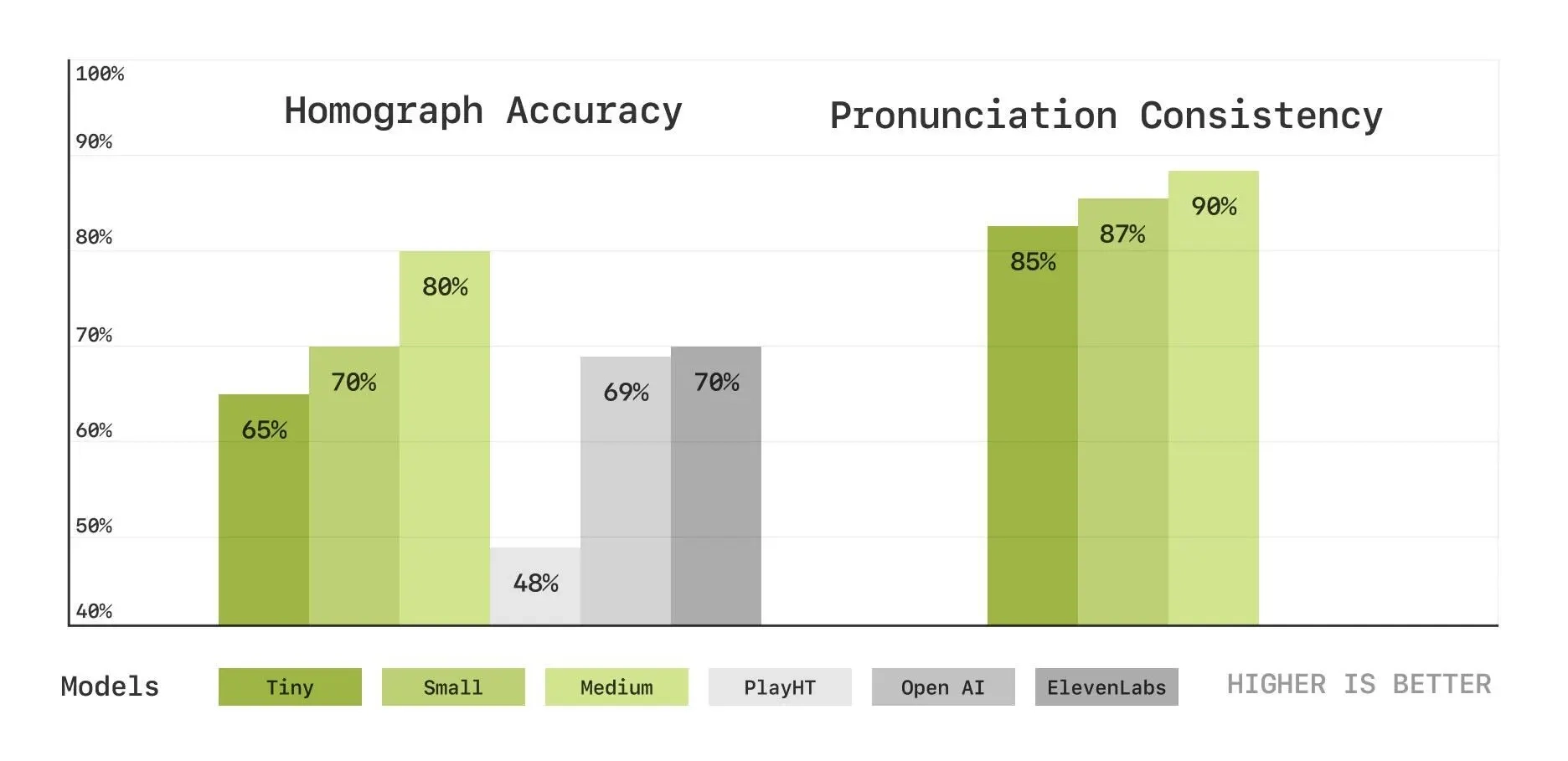
- 结论
• 模型规模越大,语音合成的准确性和真实性越高,支持“规模化提升表现”的假设。
主观指标
- CMOS研究设计
• 使用Expresso数据集进行两项比较平均意见得分(CMOS)研究,80名人类评估者参与,比较CSM-中型模型生成语音与真实人类录音。
• 无语境:评估“哪种更像人类语音”。
• 有语境:评估“哪种更适合对话延续”(提供前90秒音频和文本)。 - 结果
• 无语境:生成语音与人类录音胜负比为50:50,表明自然度已饱和,评估者无明显偏好。
• 有语境:人类录音明显胜出,表明CSM在对话韵律的语境适当性上仍有差距。 结论
• CSM生成的语音在自然度上接近人类,但在对话场景中捕捉韵律和语境的细微差别仍需改进。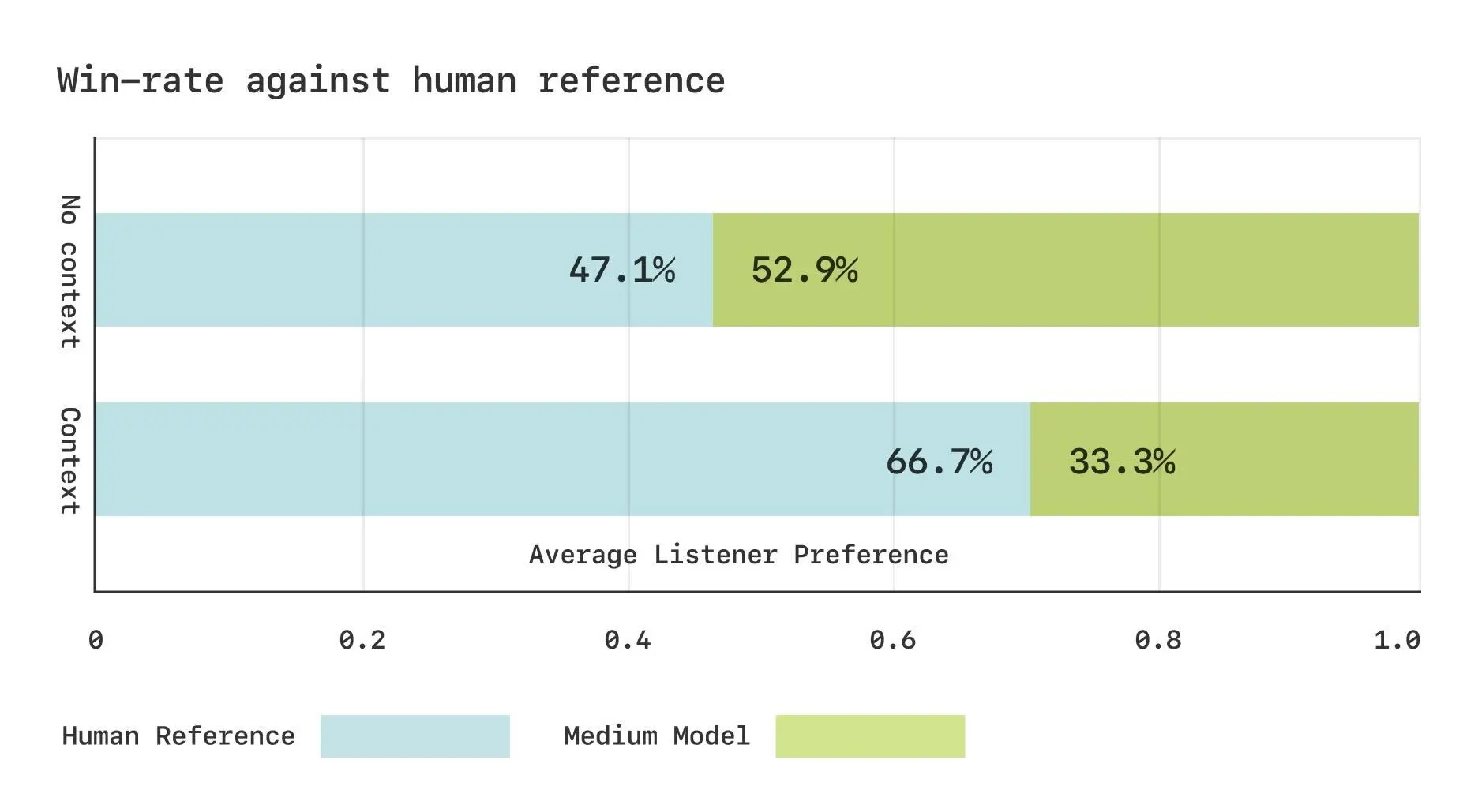
总体总结
• 优势:CSM在发音准确性和一致性上表现出色,尤其在大规模模型中,且自然度接近人类水平。
• 不足:在语境驱动的韵律表达上与人类仍有差距,特别是在实时对话的复杂动态中。
• 方向:未来需提升语境理解能力,可能通过全双工模型解决对话结构问题。
在接下来的几个月里,Sesame公司打算扩大模型规模、增加数据集量,并将语言支持扩展到 20 多种语言。
官方介绍及演示:https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
在线体验:sesame.com/voicedemo