DeepSeek今天公布了其”DeepSeek-V3/R1 推理系统“的一些关键信息,介绍了其 V3 和 R1 模型推理系统的高效设计、优化目标以及实际运行数据。
该文档揭示了 DeepSeek 如何通过跨节点专家并行、通信-计算重叠和负载均衡技术,构建了一个高吞吐量、低延迟的推理系统。
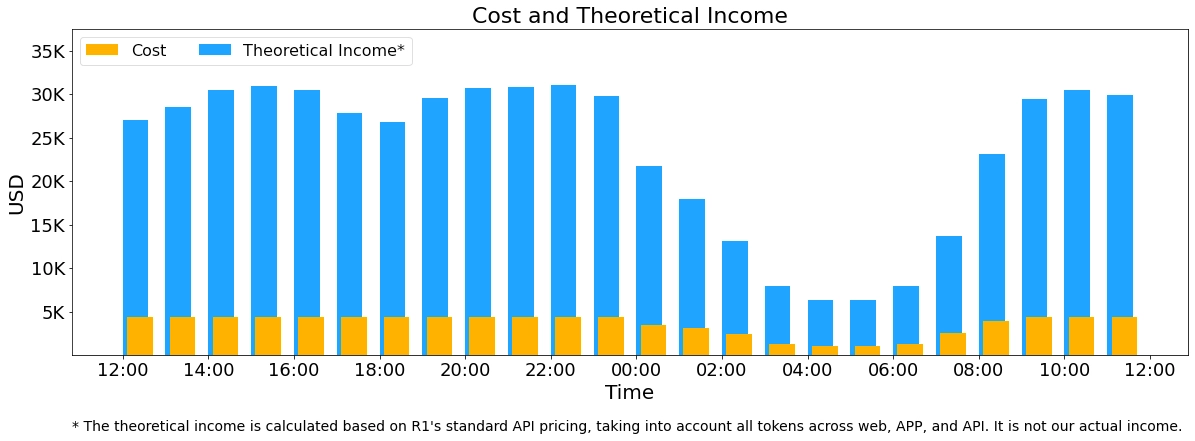
实际运行数据表明,其每日成本约 8.7 万美元,理论每日最高总收入达56万美金,实现了 545% 的成本利润率,年化收入可能超过 2 亿美元。
DeepSeek-V3 和 R1 推理系统的设计围绕两个主要优化目标展开:
- 更高的吞吐量(Throughput):即单位时间内处理的令牌(token)数量。
- 更低的延迟(Latency):即单个请求的响应时间。
为了实现这两个目标,DeepSeek 采用了跨节点的专家并行(Expert Parallelism, EP)技术,并通过以下方式优化:
• 提升吞吐量:EP 允许显著扩展批量大小(batch size),提高 GPU 矩阵计算效率。
• 降低延迟:EP 将专家(experts)分布到多个 GPU 上,每个 GPU 只处理少量专家,减少内存访问需求。
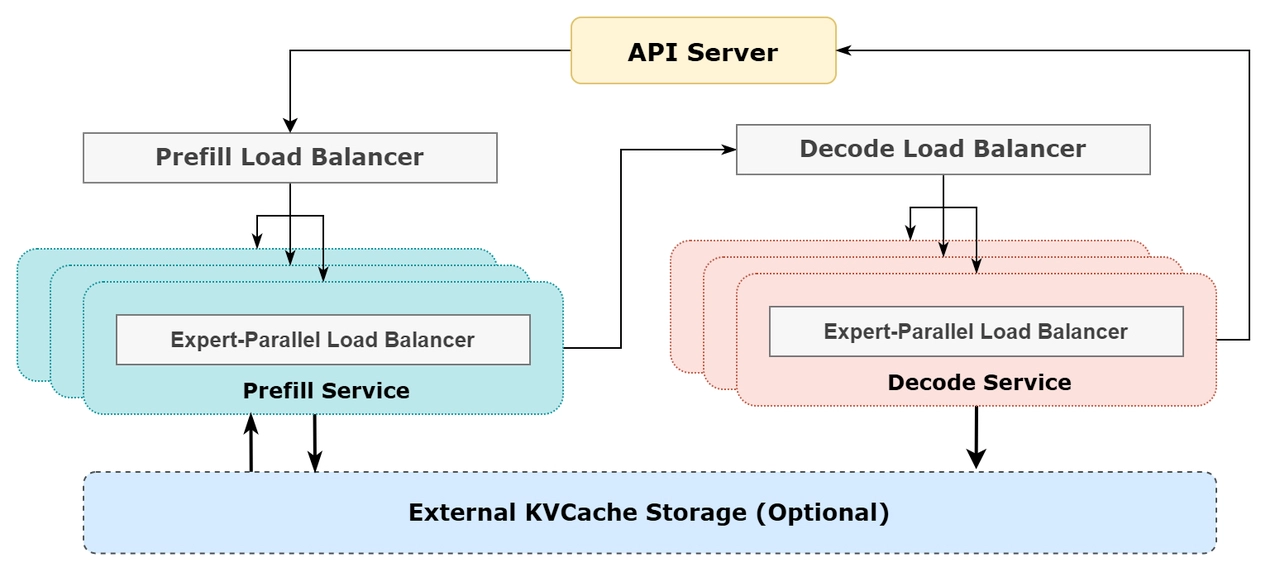
怎么做到的?
大规模“专家并行”(EP)技术
- 这个 AI 系统有 256 个“专家”模块,但每次只用 8 个,所以计算是稀疏的,需要超大批量的数据来运行。
- 把计算任务拆成多个部分,分布在多个 GPU 上,这样每个 GPU 只计算自己负责的部分,不会拖慢整体速度。
- 预填充阶段(输入阶段)和解码阶段(输出阶段)采用不同的并行策略,使计算更快。
计算和通信同步进行
- 由于 AI 计算需要不断地在不同的 GPU 之间传递数据,这会带来通信延迟。
- 他们使用了 “双批次”策略,让 AI 在计算的时候,同时进行数据传输,这样就不会浪费时间。
智能负载均衡
- 如果某个 GPU 计算任务太多,而其他 GPU 很空闲,就会拖慢整个系统。
- 他们通过 智能调度,让任务在 GPU 之间分配得更均匀,提高整体效率。
运行成本和收入
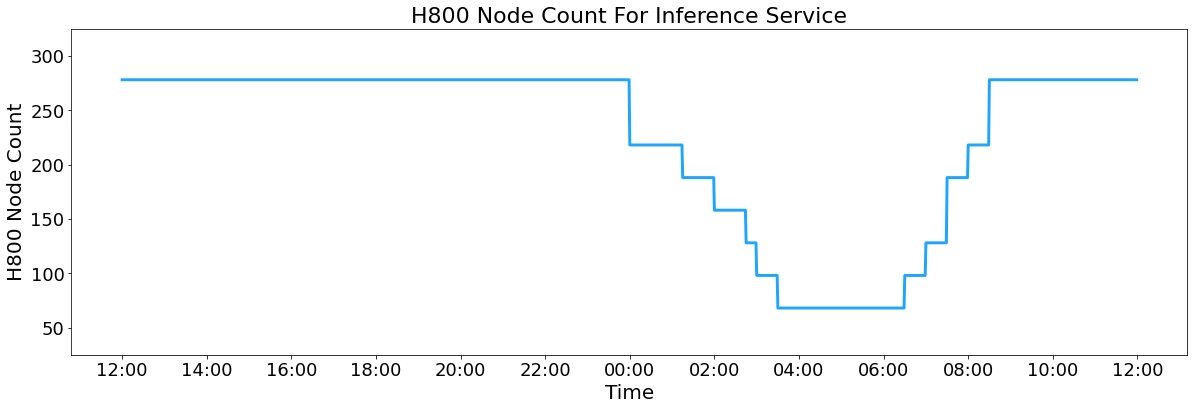
- 每天使用 278 台 H800 GPU,平均 226.75 台 GPU 在运行,每台 GPU 每小时 成本 $2,所以一天运行成本大概是 $87,072。
每天 AI 处理的文本数据量:
- 输入 Token 总量:6080 亿,其中 3420 亿命中缓存(减少计算压力)。
- 输出 Token 总量:1680 亿,平均 每秒 20-22 个 Token。
理论收入:
- 如果按照 DeepSeek-R1 价格收费,每天可以赚 $562,027,利润率 545%。
但实际收入远低于理论值,因为:
- DeepSeek-V3 价格比 R1 便宜。
- 部分服务免费(比如 Web 和 APP)。
- 夜间计算有折扣,降低了总收入。