Anthropic 发布其最新推 AI 模型 Claude 3.7 Sonnet 混合推理模型以及相关的 Claude Code 工具。
这一新型的混合推理模型旨在通过提供两种思维模式(即时响应与扩展推理),提高 AI 在复杂任务中的表现。
核心亮点:
- Claude 3.7 Sonnet:最智能的 Claude 版本,首个混合推理模型(Hybrid Reasoning Model),可灵活切换即时响应与深度推理模式。
- Claude Code:专为开发者打造的智能代码助手,具备代码搜索、自动修改、测试、GitHub 集成等功能。
- 优化计算成本与性能:通过 API 控制 AI 最多思考多少个 token,用户可以自由权衡速度与质量。
- 全面优化编程能力:在代码生成、前端开发、复杂代码库管理、全栈开发等领域大幅提升性能,击败同类 AI 模型。
- 安全性提升:误拒无害请求的概率降低 45%,并增强防御提示注入攻击(Prompt Injection Attacks)。
混合推理模型的定义:
- Claude 3.7 Sonnet 被定位为“业界首款混合推理模型”(industry-first hybrid reasoning model)。所谓“混合”,指的是它能够在快速回答和深入推理之间无缝切换,用户可以根据任务需求动态调整其行为。
- 标准模式(Standard Mode):针对简单查询或需要即时响应的场景,提供接近实时的答案,类似于 ChatGPT 或早期 Claude 模型的表现。
- 扩展思考模式(Extended Thinking Mode):针对复杂的多步骤任务,模型会模拟人类的思考过程,逐步分析问题、探索多种可能性,最终给出更准确、深思熟虑的回答。
与前代模型相比,Claude 3.7 Sonnet 在处理数学、物理、指令跟随和编码任务等方面都显示出显著的提升。此外,用户现在可以更精确地控制 AI 的思考时长,进一步优化了其在多任务环境中的表现。
用户控制权:
- 用户可以通过调整“思考时间”来平衡速度、成本和答案质量。例如,短思考时间适合快速问答,长思考时间适合学术研究或复杂编码。
- 这种控制权是 Anthropic 的创新点,相较于其他模型(如 OpenAI 的 o1 或 Google 的 Gemini),用户无需切换不同模型,只需在一个模型内调整参数即可。
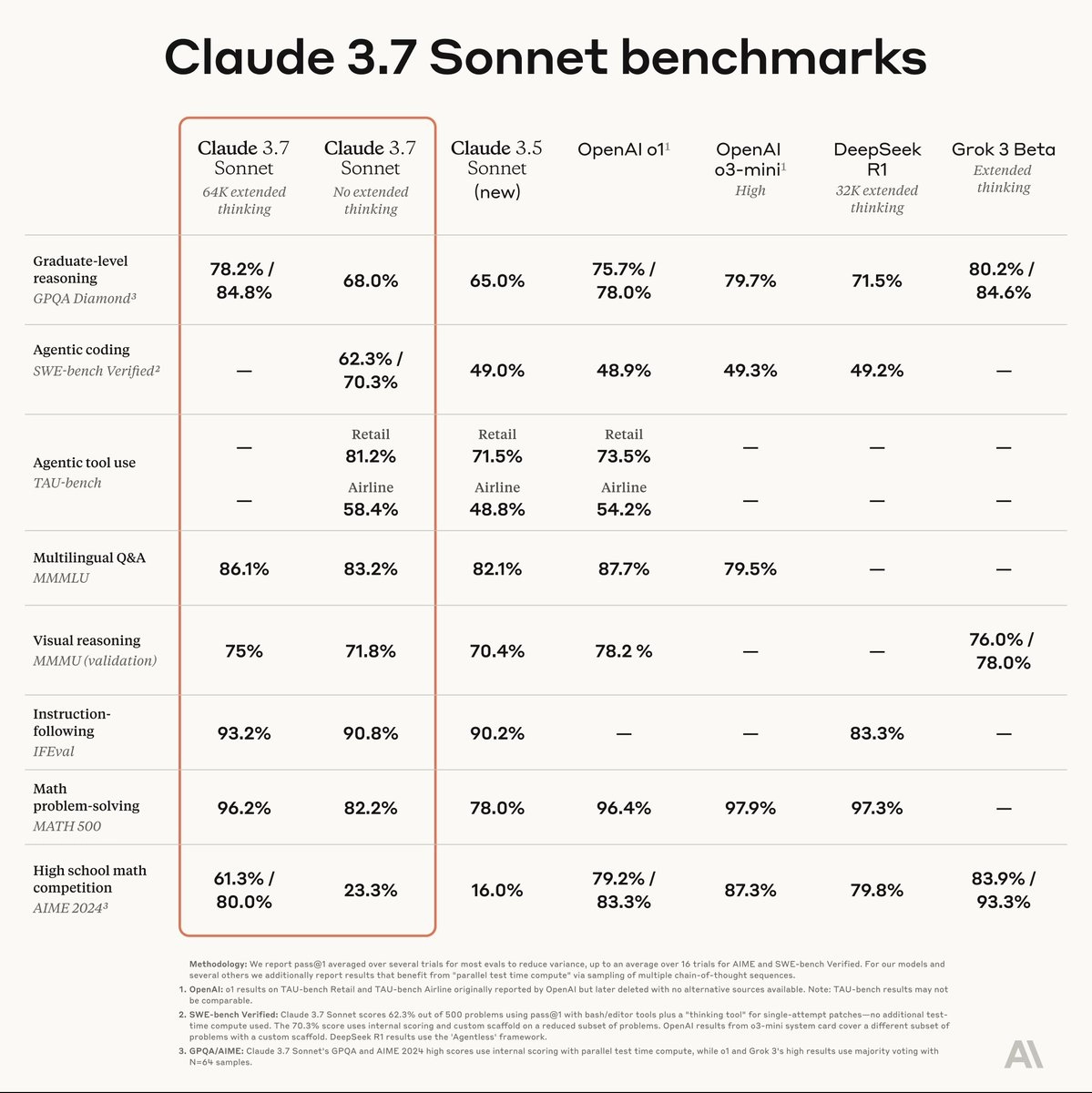
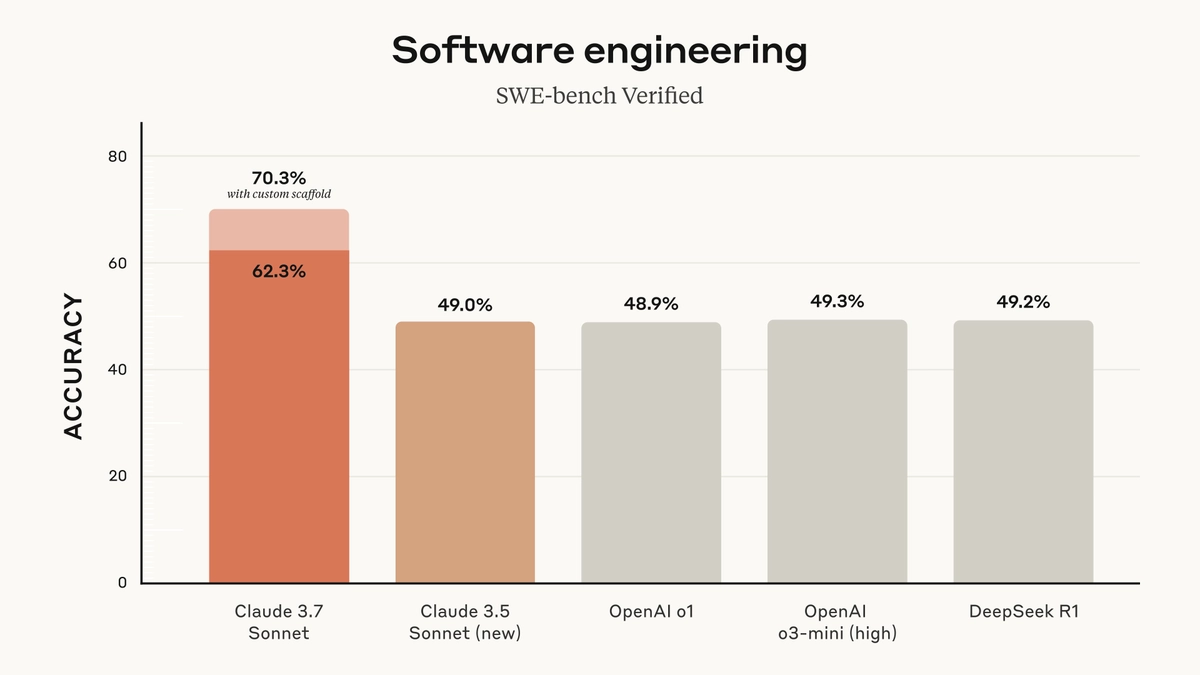
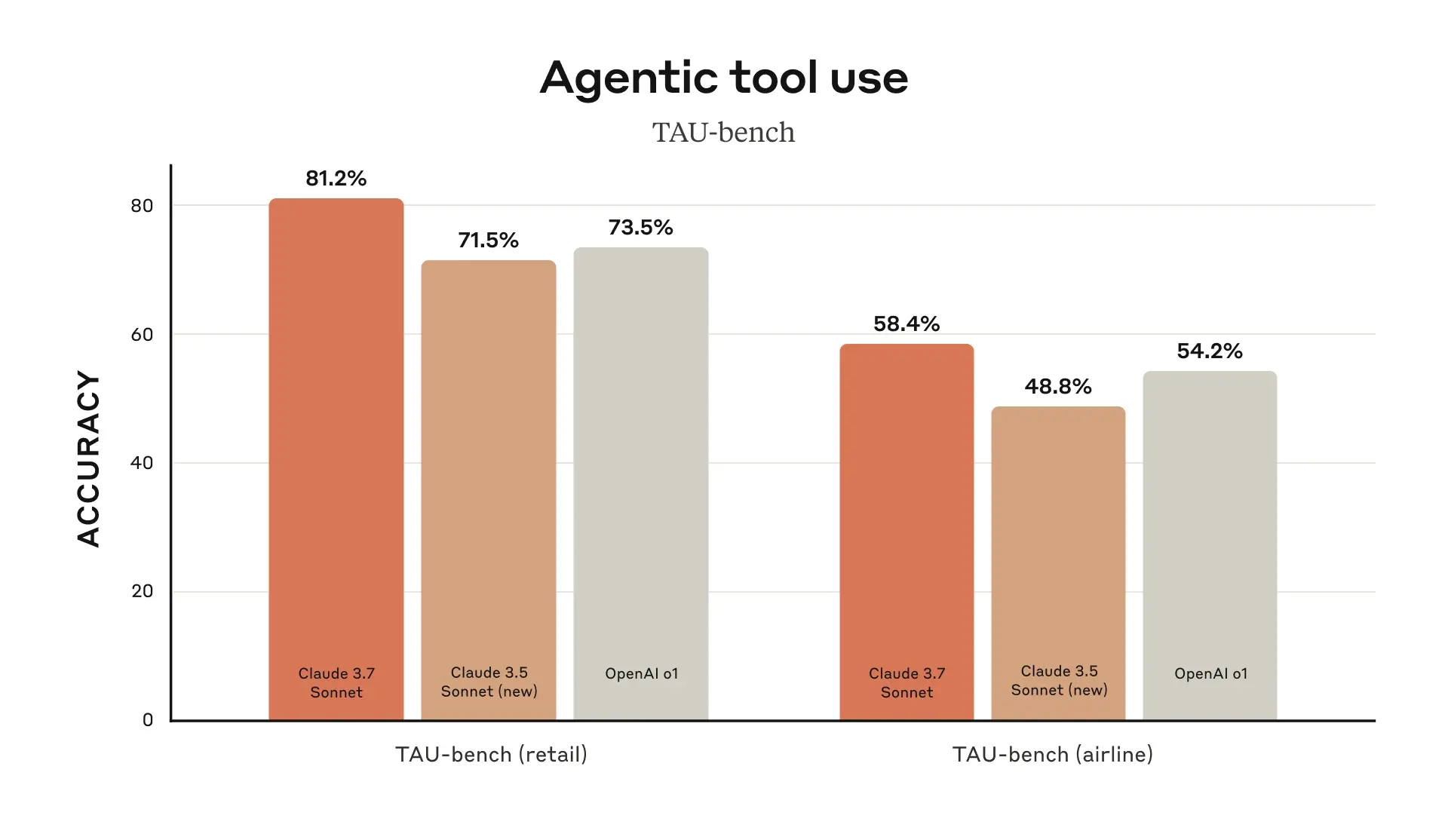
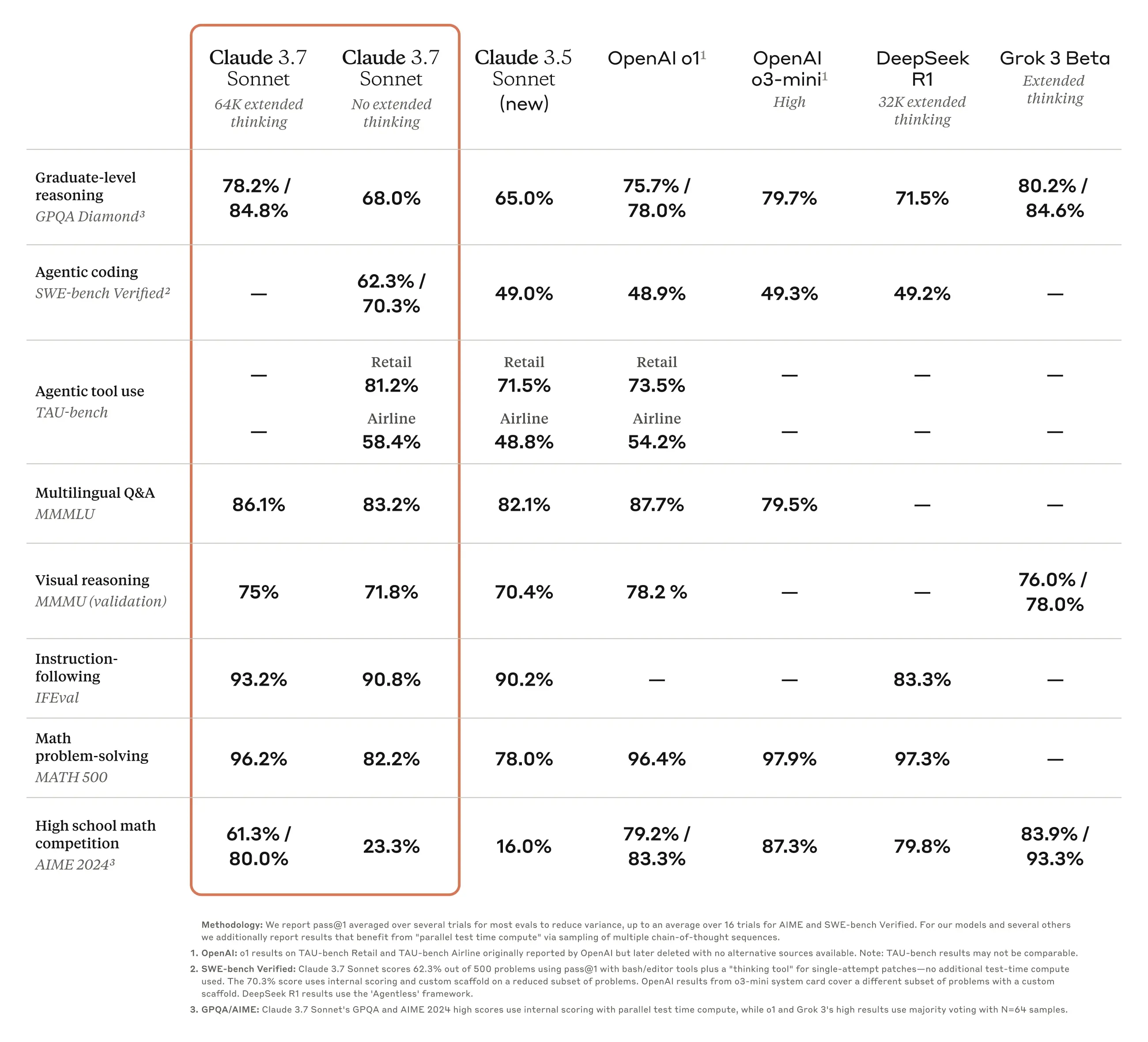
在性能测试方面,Claude 3.7 Sonnet 在 SWE-bench 基准测试中表现优异,Claude 3.7 Sonnet在“定制支架”下的准确率为70.3%(基础表现为62.3%),而Claude 3.5 Sonnet、OpenAI o1、OpenAI o3-mini(高)和DeepSeek R1等模型的准确率均为49%左右。
Claude 3.7 Sonnet 的核心升级
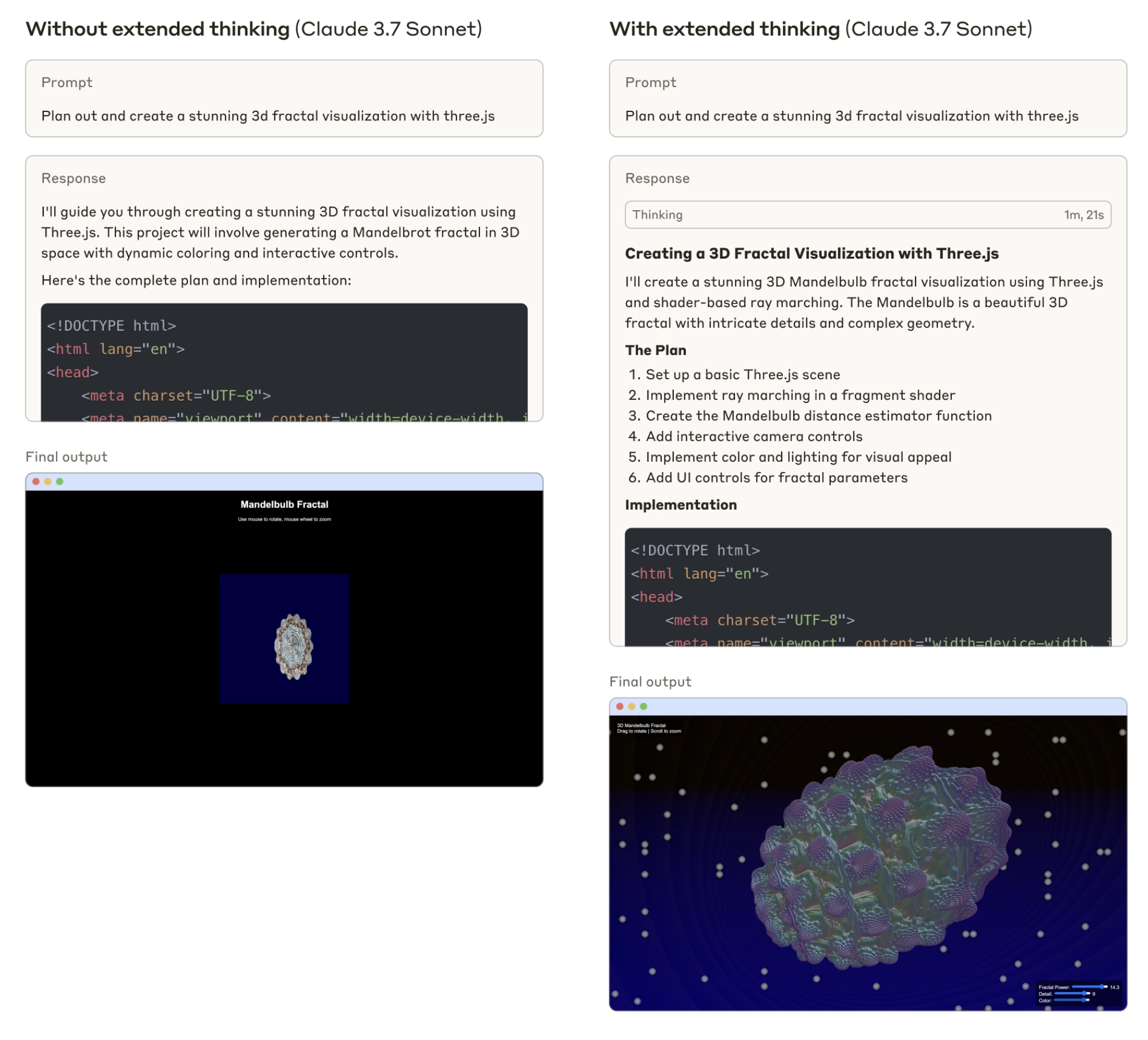
Anthropic 在 Claude 3.7 Sonnet 中引入了全新混合推理模式,使 AI 既能即时响应,也能在需要时进行更深层次的思考。
混合推理能力(Hybrid Reasoning Model)
Claude 3.7 Sonnet 在单一模型中结合了快速响应与深度推理,可以根据需求选择不同的处理方式:
标准模式(即时响应):作为 Claude 3.5 Sonnet 的升级版,能够提供更快、更精确的回答,适合对话式交互和快速任务处理。
扩展思考模式(Extended Thinking Mode)
- AI 在回答之前会先进行自我反思,从而提高在数学、物理、代码编写、复杂指令执行等方面的能力。
适用于需要严谨推理、细致分析或复杂计算的任务。

工作原理: 在此模式下,Claude 3.7 Sonnet 会分配额外的时间和计算资源,用于分解问题、制定计划、检查假设并验证结果。这种“思考深度”通过额外的“思考令牌”(thinking tokens)实现。
模型会生成一个内部“草稿纸”(scratchpad),记录其推理步骤,用户可以看到这一过程,类似于人类在纸上演算。
适用场景:
- 数学与逻辑:解决多步骤数学证明或逻辑推理问题,例如研究生级别的 GPQA 测试题目。
- 科学研究:分析实验数据、生成假设或解释复杂现象。
- 战略规划:为商业案例提供多角度分析和建议。
- 计费机制: 扩展思考模式会增加上下文窗口的使用量,额外的思考令牌按输出令牌计费(每百万令牌 15 美元)。这意味着复杂任务的成本会高于标准模式,但用户可以根据预算自行调节。
- 透明性: “草稿纸”功能不仅提升了答案质量,还增加了模型的可解释性。用户可以追踪模型的推理路径,发现潜在错误或提出改进建议。
内容生成与创意任务
- 能力提升: 在写作、编辑和内容生成方面,Claude 3.7 Sonnet 比前代模型更流畅、更具创造性,同时保持了 Anthropic 一贯的“安全”与“中立”风格。
示例:
- 生成长篇文章、润色草稿、编写营销文案或创作故事大纲。
- 在扩展思考模式下,可以生成更具逻辑性和深度的内容,例如学术论文初稿。
API 控制思考预算
- 开发者可以自定义 Claude 的思考时间,控制 AI 的最大思考 token 数(最高可达 128K)。
允许用户根据具体应用场景平衡计算成本与回答质量:
- 需要快速响应时,可设置低 token 限制。
- 需要高质量、深度推理时,可允许更长时间思考。
真实世界优化
Claude 3.7 Sonnet 不再仅仅优化数学和计算机竞赛题,而是更关注企业级真实应用:
- 提高在商业、工程、科研等实际场景的可用性。
- 例如:可以优化供应链分析、金融建模、企业决策辅助等应用。
Claude 3.7 Sonnet 在编程方面的突破
Claude 3.7 Sonnet 在代码生成、前端开发、软件维护、全栈开发等方面实现了重大突破。
强化的编程能力
Claude 3.7 Sonnet 在 SWE-bench Verified 评测中达到了业界最佳水平:
- SWE-bench Verified 是评估 AI 解决实际软件开发问题能力的权威测试。
Claude 3.7 Sonnet 在多个代码相关任务中优于所有现有 AI:
- 复杂代码库管理
- 自动化工具调用
- 代码变更规划
- 全栈开发
- 错误检测与修复
Claude 3.7 在多个行业领先平台的测试中表现优异:
- Cursor:在真实世界编程任务中,Claude 3.7 Sonnet 击败所有竞品。
- Cognition:比其他模型更擅长代码变更规划、管理全栈开发。
- Vercel:Claude 3.7 Sonnet 在复杂智能代理(Agent)开发方面表现出色。
Replit:Claude 3.7 Sonnet 能够独立构建完整的 Web 应用与数据面板,而其他模型在此任务上失败。
Claude Code——智能代码助手
Anthropic 推出了全新的Claude Code,这是一个命令行工具,可以显著提高开发效率:
主要能力:
- 代码搜索与阅读
- 自动化代码编辑
- 编写和运行测试
- GitHub 代码提交
- 使用命令行工具
Claude Code 可以一次性完成复杂编程任务,大幅降低开发者的工作量:
- 在内部测试中,Claude Code 仅需一次运行就能完成通常需要 45 分钟人工编写的代码。
代理能力与计算机使用
- 改进点: Claude 3.7 Sonnet 在“计算机使用”(computer use)任务中表现出色,这类任务要求模型模拟人类与计算机的交互。
- 具体包括:移动光标、点击按钮、输入文本、导航界面等。
应用场景:
- 自动化工作流:例如,自动填写表单、从网页提取数据或操作桌面应用程序。
- AI 代理开发:支持构建能够自主完成多步骤任务的智能代理。
- 技术实现: Anthropic 可能通过增强模型的视觉和动作理解能力实现了这一功能,但具体技术细节未在公告中透露。
GitHub 集成
Claude 3.7 Sonnet 支持 GitHub 集成,允许开发者将自己的代码库直接连接到 Claude:
适用于:
- 修复 bug
- 开发新功能
- 编写文档
- 代码审查
全平台可用:
- Claude 代码功能支持所有付费计划(Pro、Team、Enterprise),但免费版受限。
性能数据与基准测试
关键基准:
- GPQA(研究生级推理): 扩展思考模式下准确率为 78.2%,超越 DeepSeek R1(约 75%)并接近 OpenAI o1(具体数据未公布,但业内估计在 80% 左右)。
- SWE-bench Verified(编码): 标准模式下 70.3%,扩展模式下更高,领先于大多数竞争对手。
- HumanEval(代码生成): 未提供具体数据,但 Anthropic 声称其表现“显著优于” Claude 3.5 Sonnet。
与其他模型对比:
- OpenAI o1:o1 在推理任务中表现出色,但需要单独调用,且成本较高。
- Google Gemini Flash Thinking:速度快但推理深度有限。
- DeepSeek R1:价格低廉,但在复杂任务中表现不如 Claude 3.7 Sonnet。
进步幅度: 与 Claude 3.5 Sonnet 相比,3.7 版本在推理和编码任务中的提升约为 10-15%,具体视任务复杂度而定。
定价与可用性
定价详情:
- 标准模式与扩展思考模式:均为每百万输入令牌 3 美元,每百万输出令牌 15 美元。
与其他模型对比:
- OpenAI o3-mini:输入 1.10 美元/百万,输出 4.40 美元/百万。
- DeepSeek R1:输入 0.55 美元/百万,输出 2.19 美元/百万。
Claude 3.7 Sonnet 的定价偏高,但其混合能力可能减少用户对多种模型的需求。
- 上下文窗口: 未明确提及,但 Anthropic 通常提供 200k 令牌的上下文窗口,预计 3.7 版本保持或略有提升。
可用性:
- 订阅用户:免费版、Pro、Team 和 Enterprise 用户均可访问,但扩展思考模式仅限付费用户。
- API 访问:通过 Anthropic API、Amazon Bedrock 和 Google Vertex AI 提供。
- 区域限制:公告未提及,但 Anthropic 服务通常覆盖全球主要市场。
Claude 3.7 Sonnet 的安全性改进

Anthropic 加强了 Claude 3.7 Sonnet 的安全性和可靠性,重点包括:
更精准的请求处理
- 减少 45% 误拒无害请求的情况,提高 AI 的实用性。
通过更细腻的分类,Claude 3.7 Sonnet 可以更准确地区分恶意请求和正常请求,避免不必要的限制。

提升抗攻击能力
防御提示注入攻击(Prompt Injection Attacks):
- Claude 3.7 Sonnet 经过专门训练,可识别并抵御此类攻击。
- 能够更安全地处理敏感信息,减少 AI 被操纵的风险。
AI 透明度提升
- 增强推理透明度,让用户更容易理解 AI 的决策过程。
- 可解释性提高,使 AI 的输出更加值得信赖。
官方介绍:https://www.anthropic.com/news/claude-3-7-sonnet
推理思考测试:https://www.anthropic.com/news/visible-extended-thinking
技术报告:https://assets.anthropic.com/m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf