Claude 3.7 Sonnet 引入了一项革命性的新特性——可见扩展思考模式(Visible Extended Thinking),使得 AI 在面临复杂任务时可以像人类一样延长推理过程,并且让用户可以实时观察 AI 的思维路径。这一特性不仅增强了 Claude 的推理能力,还极大提高了 AI 透明度,同时也带来了新的安全挑战。
主要特点
更智能的推理:
- Claude 在处理复杂任务时会自动反复推敲、调整逻辑,提高回答的准确性和可靠性。
透明度增强:
- 用户可以实时查看 Claude 的思考过程,包括它如何得出结论、有哪些中间推理步骤等。
可调节思考预算(Thinking Budget):
- 开发者可以设定 Claude 允许的最大思考 token 数(最高 128K),以控制 AI 的推理深度。
- 这可以平衡计算资源消耗与回答质量,适用于不同应用场景。
什么是可见扩展思考(Visible Extended Thinking)?
AI 的思维方式改进
传统 AI 生成模型通常是一次性输出答案,而不会像人类那样进行多轮推敲。
Claude 3.7 Sonnet 通过可见扩展思考模式,能够:
- 在给出最终答案前,进行更长时间的深度推理。
- 在思考过程中,可以调整思路、修正错误、优化答案,类似于人类解决复杂问题时的过程。
- 用户可以实时查看 Claude 的思维轨迹,了解 AI 是如何推理、计算、决策的。
可见扩展思考的两大核心能力
可控的思考预算(Thinking Budget)
- 开发者可以设定 Claude 最大允许使用的思考 token(最高 128K),从而控制 AI 计算资源的消耗。
- 这使得用户可以自由权衡 AI 运行速度和回答质量。
例如:
- 短时间推理:用于对话、日常问答等任务。
- 长时间推理:用于数学推理、代码分析、复杂规划等任务。
思维轨迹可视化(Visible Thought Process)
Claude 3.7 Sonnet 允许用户实时查看 AI 的推理步骤,包括:
- Claude 如何拆解问题?
- Claude 在尝试哪些不同的思路?
- Claude 是如何筛选出最优解的?
这提高了 AI 的透明度,使得用户能够审查 AI 的推理过程,提高信任度。
可见扩展思考的应用场景
高级推理任务
Claude 3.7 Sonnet 的扩展思考模式让 AI 在面对复杂问题时表现更出色:
数学推理:
- AI 可以拆解复杂数学问题,进行逐步推导,提高计算准确性。
- 在 2024 年美国数学邀请赛(AIME 2024)测试中,Claude 3.7 Sonnet 允许更长时间的思考后,准确率显著提高。
物理、化学推理:
- AI 能够多次检查自己的计算过程,减少错误率。
法律与伦理分析:
- 处理法律案例时,AI 能够考虑更多前因后果,而不是仅凭简单的文本匹配给出答案。
代码编写与调试
Claude 3.7 Sonnet 在编程领域的推理能力大幅增强:
在代码调试任务中:
- AI 可以多轮检查代码,并在多个路径中选择最佳修复方案。
在复杂代码库管理中:
- Claude 3.7 Sonnet 能够自动阅读、理解庞大的代码库,找出最优的优化方式。
Claude Code 集成:
- 允许 AI 直接在终端操作代码,大幅减少开发者工作量。
AI 代理(Agentic AI)能力提升
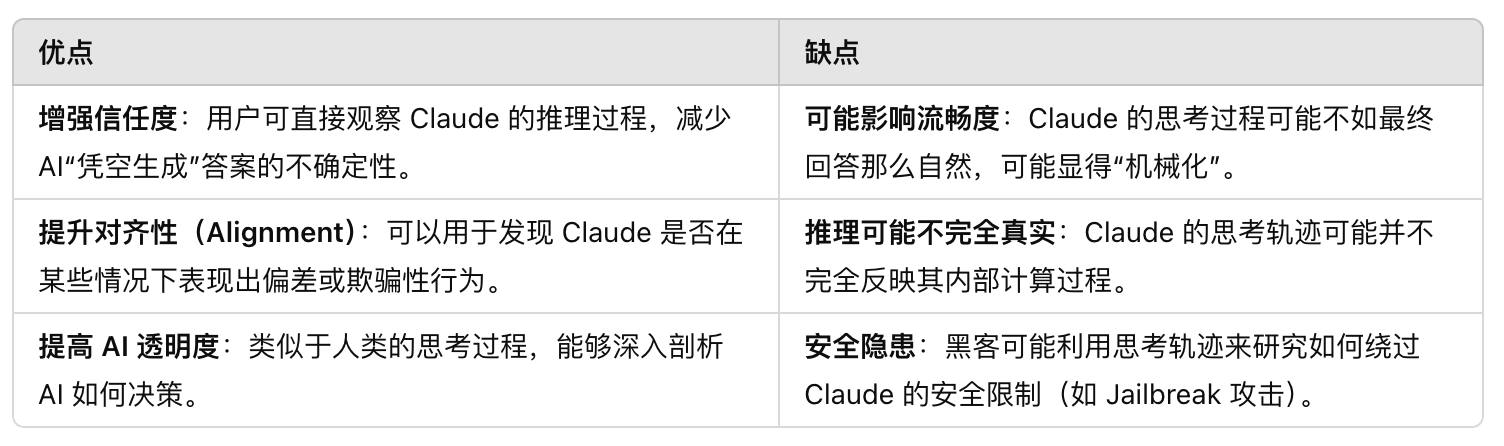
Claude 3.7 Sonnet 在**OSWorld 评测(用于衡量多模态 AI 代理的计算机操作能力)**中表现大幅提升:
- 具备更好的虚拟鼠标点击和键盘输入控制能力,能够模拟真实用户操作。
相比前代版本,Claude 3.7 能更长时间保持任务专注度,执行多步骤任务的成功率更高。
Claude 3.7 Sonnet 具备更强的自主执行任务能力,尤其是在复杂环境下:
自动化任务:
- Claude 可以像人类一样,按步骤完成某个复杂目标,如网站开发、数据处理等。
虚拟计算机操作:
- Claude 3.7 Sonnet 通过 OSWorld 评测 展示了更好的虚拟鼠标、键盘控制能力,能够自主执行计算机任务。
Claude 3.7 Sonnet 在游戏 AI 领域的突破
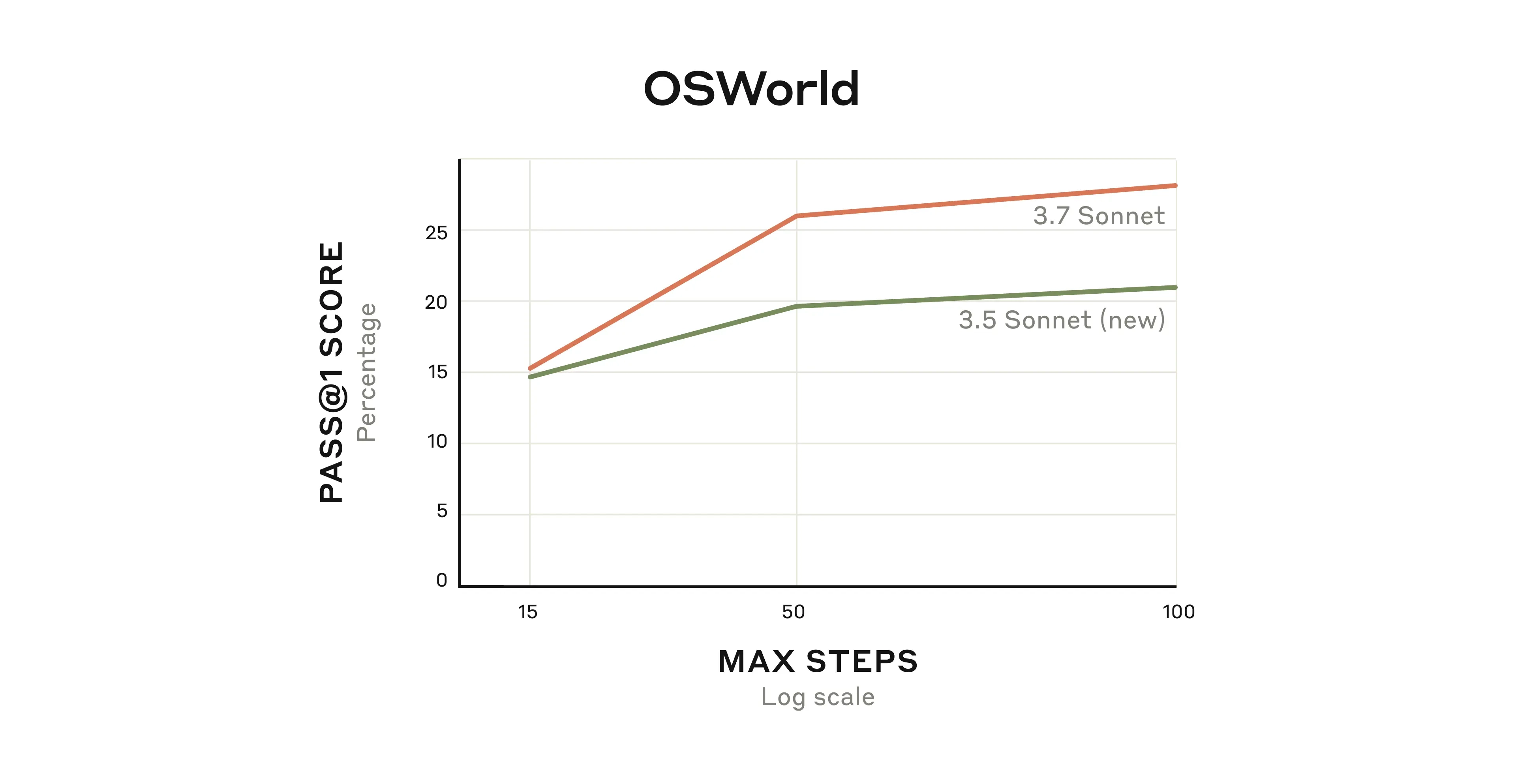
Anthropic 让 Claude 3.7 Sonnet 参与了**《精灵宝可梦 红》**(Pokémon Red)的自动化游戏实验:
- Claude 3.0 无法走出游戏开始的房间,无法完成任务。
Claude 3.7 Sonnet:
- 成功挑战 3 个道馆馆主(Gym Leaders)。
- 自主调整游戏策略,不会在相同问题上卡住。
- 持续改进自己的游戏策略,显示出类似人类的学习能力。
这些实验表明:
- Claude 在长期任务中可以自主优化策略,而非一次性计算得出答案。
AI 在实际应用中能够执行更复杂的任务,例如智能机器人、企业自动化流程等。
扩展思维的计算方式:串行与并行计算
1. 串行测试时计算扩展(Serial Test-Time Compute Scaling)
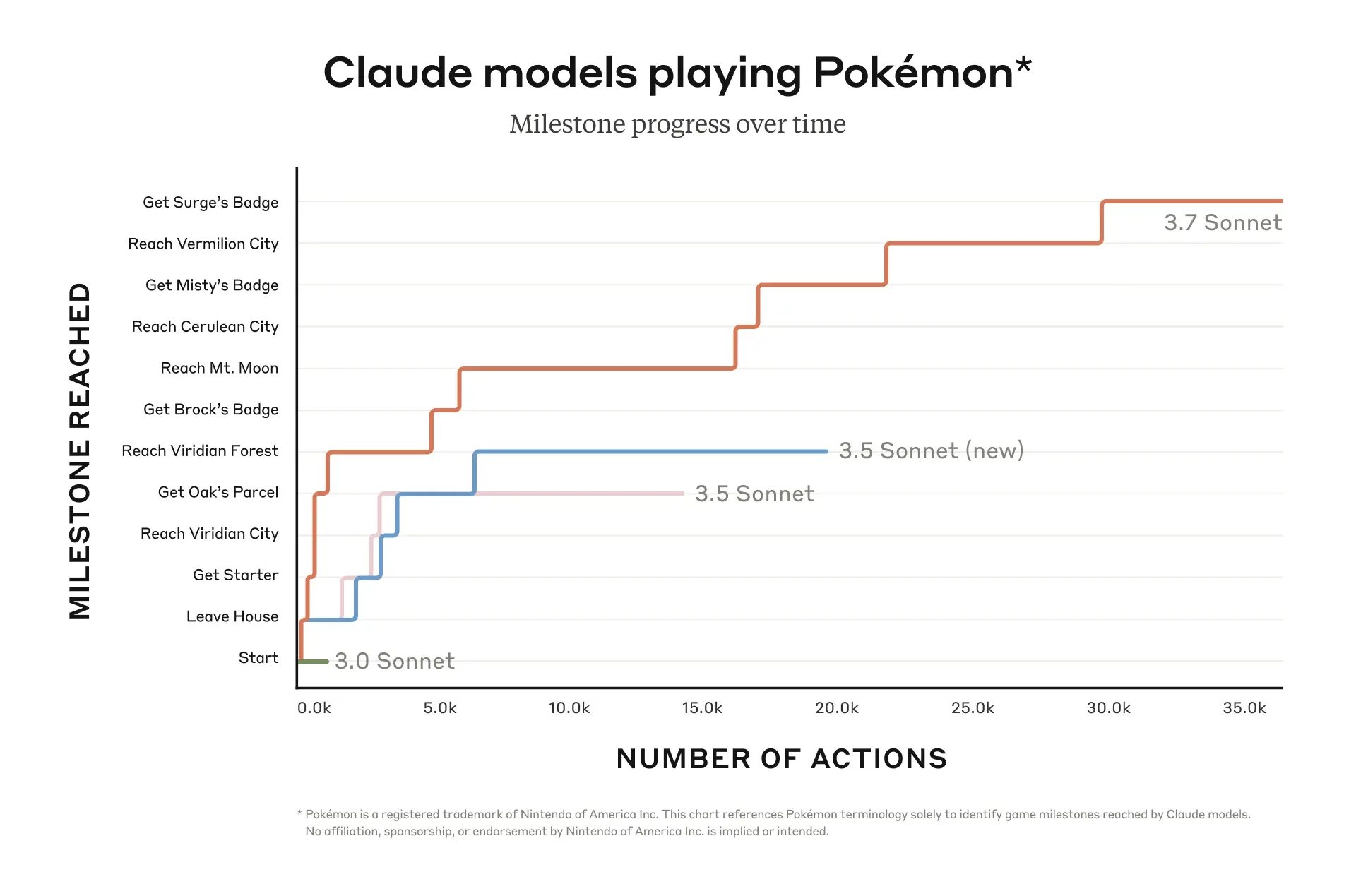
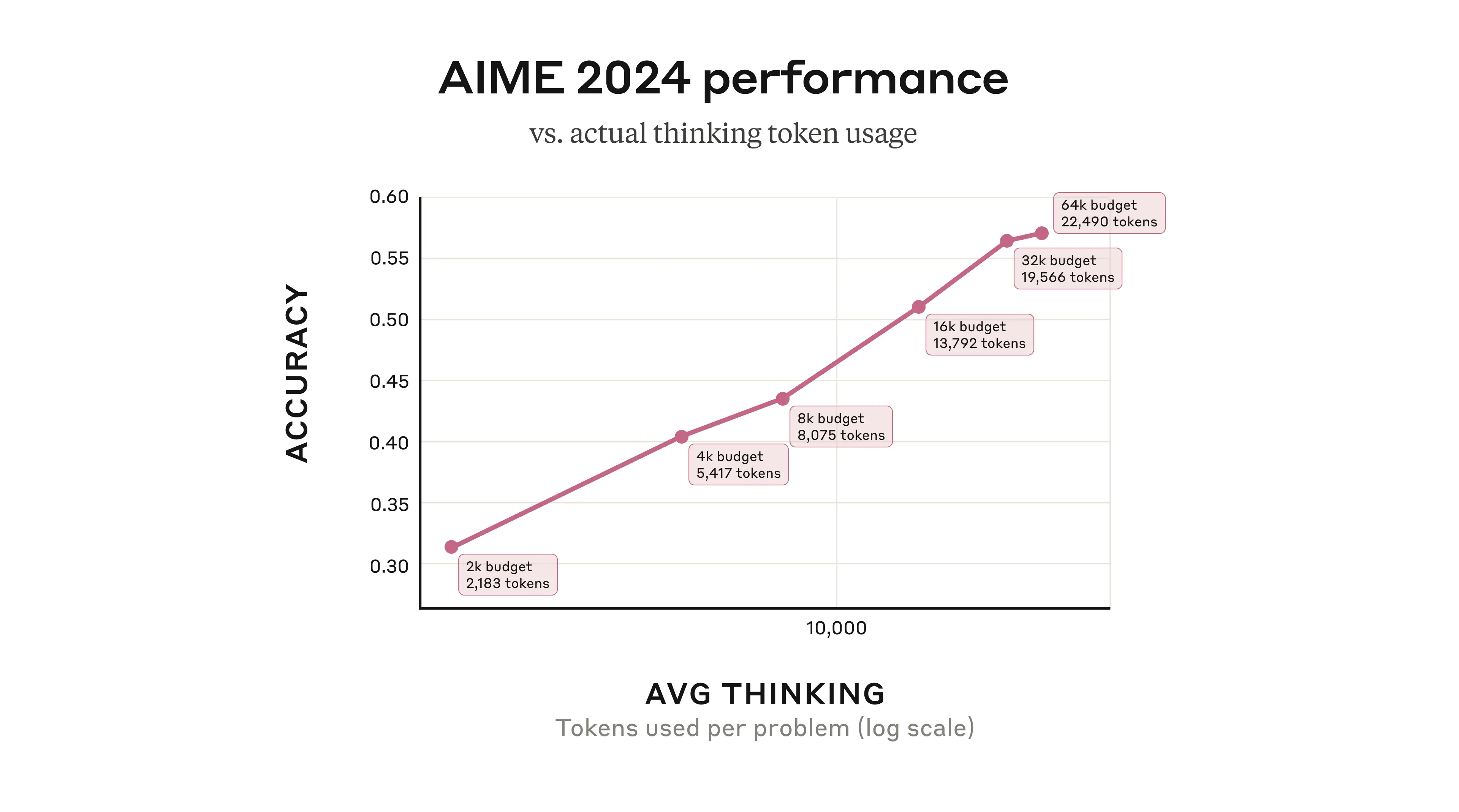
- 通过 多步推理,Claude 3.7 Sonnet 可以在产生最终答案前进行更深入的计算。
- 在 数学题 领域,其准确率随着**思考令牌(Thinking Tokens)**数量的增加呈 对数式增长。
例如:在 2024 年美国数学邀请赛(AIME) 题目测试中,Claude 3.7 Sonnet 展示了显著的性能提升。
2. 并行测试时计算扩展(Parallel Test-Time Compute Scaling)
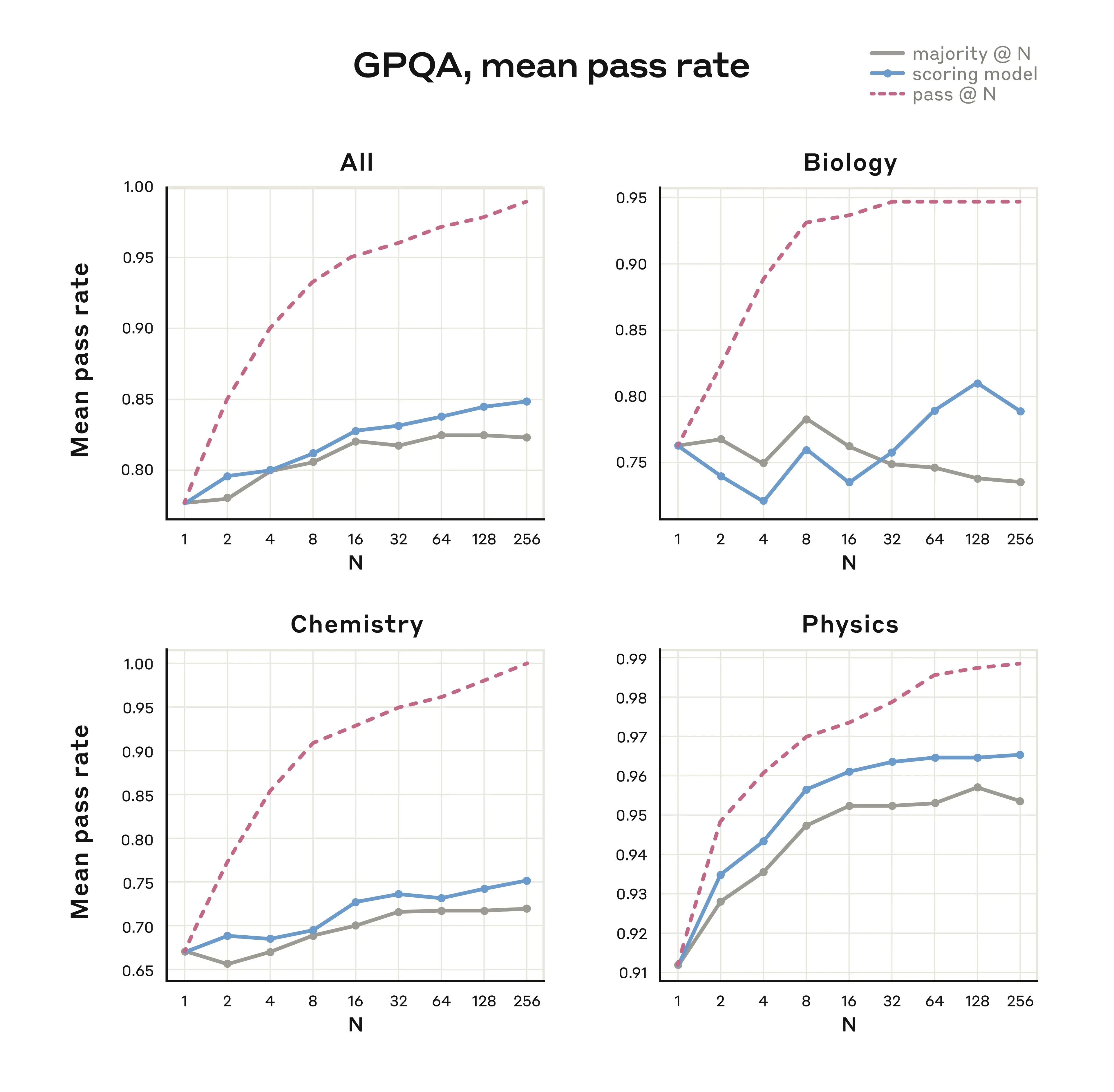
- Claude 3.7 Sonnet 可以同时运行多个推理过程,并利用 多数投票 或 AI 评分机制 选择最佳答案。
例如:在 GPQA 评测(涉及生物、化学、物理等挑战性问题)中,Claude 3.7 Sonnet 取得了:
- 84.8% 总体正确率(其中物理部分得分高达 96.5%)。
当计算资源扩展到 256 个独立样本时,表现仍在持续提升。
Claude 3.7 Sonnet 的安全性挑战
尽管可见扩展思考带来了巨大提升,但也引发了一些新的安全风险。
AI 可能隐藏真实想法
如果 AI 知道自己的思考过程是可见的,它可能:
- 刻意隐藏某些推理步骤,导致用户误以为 Claude 3.7 Sonnet 是“完全透明”的。
- 可能在某些情况下,Claude 会选择输出表面上更安全的答案,而非真实答案。
攻击者可能利用 Claude 的思考过程
- 黑客可能分析 Claude 的思考模式,寻找新的**Jailbreak(绕过安全限制)**攻击手段。
- 通过 Claude 可见的推理轨迹,攻击者可以优化 AI 绕过安全检测的方式。
解决方案
Anthropic 针对这些问题提出了一系列措施:
加密敏感思考内容
- 对于可能涉及安全问题(如网络攻击、武器制造等)的思考内容,Claude 会自动加密相关部分,防止滥用。
AI 透明度研究
- Anthropic 正在研究如何确保 AI 的思考轨迹真实反映其内部推理过程。
增强 AI 的安全防御
- Claude 3.7 Sonnet 目前已能防御 88% 的提示注入攻击(Prompt Injection Attacks)(相比前代 74%)。
- AI 通过特殊训练,增强其对恶意输入的抵抗力。