Deep Research 实践经验总结:从“进度条”到“提示词”,一次搞懂!
最近有很多朋友向我咨询:“Deep Research 的用量是怎么算的?”又因为目前 Plus 每个月只能用 10 次,大家都非常担心浪费。其实一句话就能总结——只要开始出现 “Starting Research” 的进度条,就算使用了一次。在进度条出现之前,怎么问都不算。下面就为大家分享一些 Deep Research 的使用流程、注意事项和提示词模板,帮助大家更好地运用这一强大的研究功能。
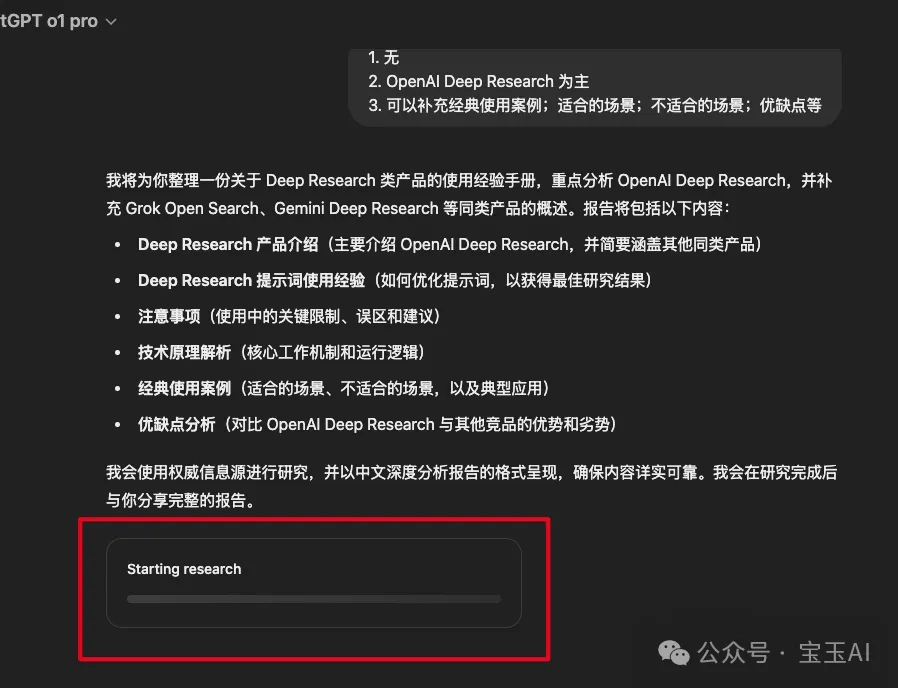
一、如何判断 Deep Research 用量
一句话总结:从开始出现 Deep Research 进度条就算一次,之前都不算。
Deep Research 的完整流程
- 提出主题你先要告诉 ChatGPT 需要研究什么主题。
- ChatGPT 询问澄清问题ChatGPT 通常会向你询问一些澄清问题,确保理解你的研究需求。
- 回答澄清,触发研究当你回答了上述澄清问题后,ChatGPT 会再回复一条消息,并提示“将开始报告”,随后出现 “Starting Research” 的进度条。注意:从这一步开始就会扣除一次 Deep Research 用量。
- 报告生成研究进度条走完后,ChatGPT 会给你发送完整的报告,这标志着一次 Deep Research 流程的完成。
二、Deep Research 使用注意事项
- 进度条出现后,你可以随时离开进度条开始后,无论你是关闭窗口、刷新网页、切换到其他会话还是新开会话,都不会影响已经开始的 Deep Research 流程,它会在后台继续执行并最终生成报告。
- Deep Research 可以后续追问当报告生成结束后,如果你要继续追加信息重新生成报告,有两种选择: 1). 直接提问,会使用你开始会话时选择的模型继续对话,报告内容可以作为上下文;比如说你从 GPT-4o 开始的,那么你在报告生成后,如果继续提问,实际上是 GPT-4o 基于你报告和提问内容回复,但是可能会受限于上下文长度无法完整理解报告内容; 2). 重新生成新报告:Deep Research 是一次性生成的,但是你可以继续在当前会话选中“Deep research”按钮,这样可以把当前会话内容作为输入,或者把内容复制出去新开会话选中“Deep research”按钮重新开始一次新的生成。内容复制出去处理一下再生成会更好的对输入进行控制,但是麻烦一些。你无法追加新的信息让它继续深度研究。如果你在当前会话里继续追问,后续的回答将由其他模型(如 GPT-4o)接管。如果你对报告不满意,需要重新修改提示词再新开一次会话进行 Deep Research。
- 灵活切换模型你可以先选任何模型(如 o1 pro/o1 等),再让它进行 Deep Research。若后续还打算继续追问报告内容,建议在 Deep Research 开始前就选一个更强的模型(比如 o1 pro / o1)来进行分析。
- 选择信息源和报告语言建议在提示词中加一句“请选择权威信息源”(并不一定要非英文来源不可,重点是权威信息源,这样可以过滤掉一些不好的信息源,当然你也可以加上“优先英文信息源”)。如果希望报告是中文,直接在提示词末尾加一句“请形成中文报告”即可。如果不小心生成了英文报告,又看着费劲,可以在当前会话,让它翻译,也可以复制完整内容,新建会话,选择 o1 pro 或 o1 模型(最佳翻译效果),翻译提示词参考:“请将下面的内容用中文重写,尊重原意,保持格式不变无删减:”
- 引入外部资料的方法如果报告需要访问收费网页上的内容,你可以手动复制成 Markdown,然后在提示词中用 XML 标签包起来。如果有图片内容,直接上传即可。如果要分析视频内容,需要先把视频转成文字,同样用
标签包住,再放进提示词里。我一般会用AIStudio 的 Gemini 转成文本。你可以一次粘贴几千行代码也没问题(用 XML 包起来),但要注意输入框粘贴有上限。如果太多,可以把代码放在公开的 GitHub 仓库,让 Deep Research 去分析链接即可。 - 写报告或写代码都行Deep Research 不仅能写报告,还能写代码。只要你提示它“生成的结果是代码”,它就会尝试从网上搜索相关代码库并提供解决方案。
- 文献质量与报告质量如果想让它“阅读”一本书并进行提炼,需要注意输入长度有限,无法直接输入一本完整的书。大部分流行书籍已经在模型中有训练数据,所以它会参考网上已有的书评。资料越多、质量越高,报告越漂亮;如果资料很少,它也无米下炊,生成的报告质量可能有限。
三、Deep Research 提示词模板参考
一个常见的提示词模板大致可分为背景信息、任务要求、和输出格式三个部分。
1. 背景信息
在这里填写所有对它生成报告有帮助,但模型本身访问不到的信息,比如:
- 付费文章
- 视频文字稿
- 图片或 PDF(可作为附件)
- 其他任何对于生成有帮助的内容
当背景信息较多时,务必用 XML 标签包裹,避免 AI 混淆指令。例如:
<background>
<news>
「付费新闻」
</news>
<article>
「付费文章」
</article>
<transcript>
「视频文字稿」
</transcript>
</background>
2. 任务要求
在此明确你想要什么样的报告或研究结果,例如:
- 主题:你希望分析、研究或讨论的具体范围
- 信息源:希望它检索的文献库、学术论文、政府网站、GitHub 等
- 研究要点:需要关注的核心点,是深度解析还是简要摘要
- 语言或风格:是中文、英文或其他语言?
3. 输出格式
这里说明你对报告最终呈现形式的要求:
- 语言:中文报告、英文报告或双语
- 数据格式:是否需要用表格呈现数据(它暂时画不了图表)
- 段落和标题:是否需要分级标题、索引等
参考示例:
```
检索时使用权威信息源,英文为主。
输出格式: - 深度分析报告 - 中文报告 ``` 提示词模板并不是必须的,可以随性一点,你可以把写提示词使用 Deep Research 当成去交代一个实习生帮你写分析报告,你怎么交代实习生就怎么写提示词。
四、总结
- Deep Research 的使用次数:只要出现“Starting Research”进度条,就会扣除一次用量。
- 保持灵活:不满意就重新开始,新开会话前最好做好提示词规划。
- 结合大模型优势:如果要深入分析或后续追问,选用更强的模型如 o1 pro / o1 更合适。
- 慎重选择资料:外部资料要提前整理好,使用 XML 标签嵌入提示。
- 尊重版权、合理引用:在使用外部资料时,务必保留引用信息,切勿违规。
希望这篇文章能让你更好地理解和使用 Deep Research。在实际使用中,不妨多加尝试和探索,慢慢就能摸索出最适合自己的使用方式。祝大家玩得开心,也能高效地完成研究和写作任务!如有更多问题,欢迎在评论区留言交流。
提示:如果你想让 Deep Research 提供权威信息源,在提示词中加一句“请选择权威信息源”。如果要生成中文报告,只要在提示词里加“请形成中文报告”即可。不小心生成英文报告且看着费劲,使用下面的提示词翻译:“请将下面的内容用中文重写,尊重原意,保持格式不变无删减:” 欢迎大家在留言区分享你们的使用心得与经验,一起探讨 Deep Research 的更多玩法!