声明:本文来自于微信公众号机器之心,授权Soraor转载发布。
随着上个月2025研究生考试的结束,最新的考研数学真题成为大语言模型尤其是推理模型的「试炼场」,将考验它们的深度思考能力。
业内曾有着这样一种共识:大语言模型在文字水平上的表现令人印象深刻,但说到数学就不甚令人满意了。去年一度火出圈的「9.9与9.11」比大小的问题,包括 GPT-4o 在内的很多大模型都翻车了,直到深度推理模型出现后才从根本上改善了这一状况。
OpenAI 发布的 o1模型在涉及复杂和专业的数理问题方面表现让人印象深刻,大模型在经过一定时间仔细思忖后,回答问题的能力和准确度大幅提升,这种被称为推理侧 Scaling Law 的现象已经成为继续推动大模型能力提升的关键力量。在黄仁勋最新CES2025的演讲中,他也把测试时(即推理)Scaling 形容为大模型发展的三条曲线之一。
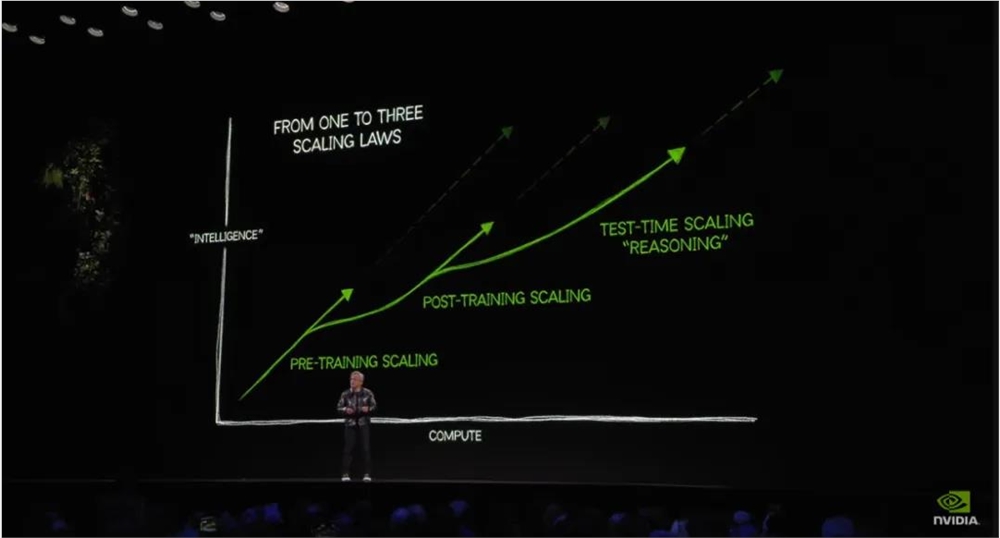
可以看到,继 o1之后,国内大模型厂商也陆续推出了自己的深度推理模型,并在某些任务上有亮眼的表现。数了一下时间轴大概是这样的:
2024年11月21日,深度求索团队发布 DeepSeek-r1模型;
2024年11月28日,阿里通义团队发布 QwQ 模型;
2024年12月16日,月之暗面团队发布 Kimi-k1模型;
2024年12月31日,智谱 GLM 团队发布 GLM-Zero 模型;
2025年1月6日,昆仑万维发布 Skywork-o1模型。
大家也许会好奇,这些深度推理模型的能力(尤其是数学推理能力)到底有多强,又是谁能拔得头筹呢?这时就需要一场公平的标准化考试了。
清华 SuperBench 大模型测评团队(以下简称测评团队)为了全面评估这些模型在数学推理方面的能力,结合2025年考研数学(一、二、三)的试题,专门对以上各家深度推理模型进行了严格的评测。同时,为了确保评测的全面性,参与评测的还包括各家的旗舰基础模型。
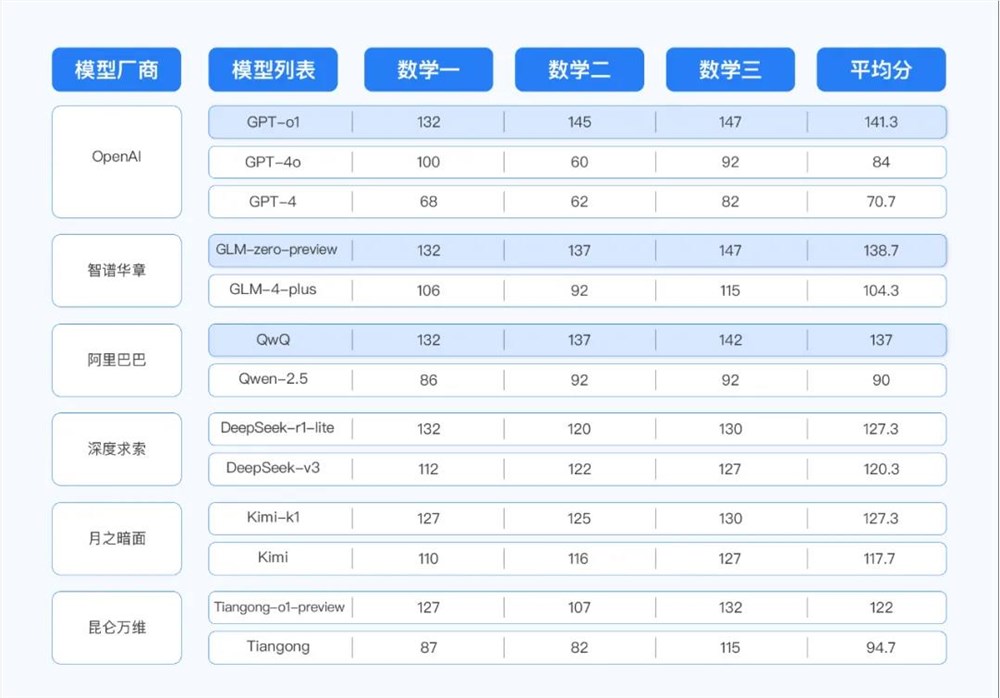
此次选择的13个模型具体如下:

从结果来看,所有模型中以平均分计,第一名是 OpenAI 的 GPT-o1模型,这也是没什么意外的。第二名则是来自智谱的 GLM-Zero-Preview,它以三门数学平均138.70的成绩仅次于 o1,成为国产大模型第一,且距第一名不到3分。第三名则是来自通义的 QwQ。
测试方法
在本次评测过程中,测评团队发现并非所有模型均提供 API 支持,且部分提供 API 服务的模型在输出内容长度超出一定限制时,会出现内容截断的情况。为确保评测工作的公正性与准确性,测评团队决定统一采用各模型厂商的网页端进行测试操作。
在测试过程中,每道题目均在独立的对话窗口中进行,以此消除上下文信息对测试结果可能产生的干扰。
鉴于部分模型输出存在一定不稳定性,为降低由此引发的分数波动,测评团队设定当同一模型在三次测试中有两次及以上回答正确时,方将其记录为正确答案。
结果分析
接下来从测试总分、单张试卷分数、深度思考模型 vs 基础模型三个方面来详细分析此次测评的结果。
总分
对于总分数,测评团队对三张试卷的分数进行求和并计算平均值,按照分数高低进行排序。结果如下图所示:
从图中可以看到,GPT-o1仍然处于领先的地位,是唯一一个达到140分以上的模型,相较于排名末位的 GPT-4,分数优势高达70分。
位于第二梯队(130分以上)的模型有 GLM-zero-preview 和 QwQ,分别斩获138.7分和137.0分。
DeepSeek-r1-lite、Kimi-k1、Tiangong-o1-preview、DeepSeek-v3则处于第三梯队(120分以上)。
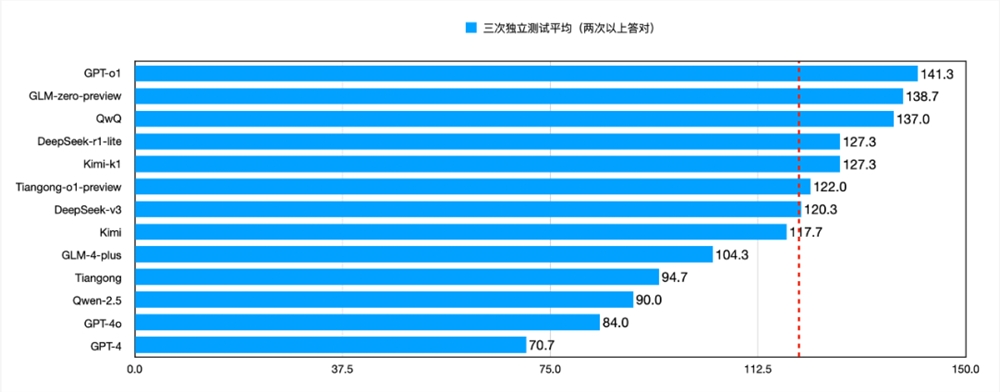
可以看出,深度思考模型普遍能够达到120+ 的水平。这也彰显了深度思考模型在解决数学问题方面的强大能力。
值得注意的是,曾于2023年位居榜首的基础模型GPT-4,在本次测试中仅获70.7分,位列末席。这一结果表明,在过去一年(2024年)中,语言模型在数学推理领域的进步显著。
而另一方面,在缺乏深度思考能力辅助的情况下,仅凭逻辑推理能力,DeepSeek-v3作为基础模型,已经能够跻身第三梯队,这说明基础模型和深度思考模型之间的能力并非界限分明。
单张试卷分析
为了更清晰地展现大模型在各张试卷答题能力方面的表现,测评团队对每张试卷的错题分布情况进行了深入分析。
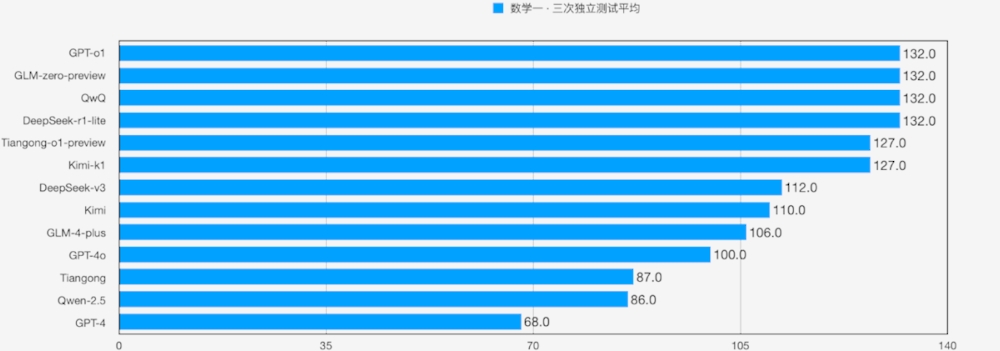
在数学一的评测过程中,GPT-o1、GLM-zero-preview、QwQ、DeepSeek-r1-lite 四款模型的得分相同。通过进一步剖析错题情况,测评团队发现所有模型均在第20题(12分,涉及曲面积分求解)以及第21题第二问(6分,涉及特征向量求解)上出现了错误。
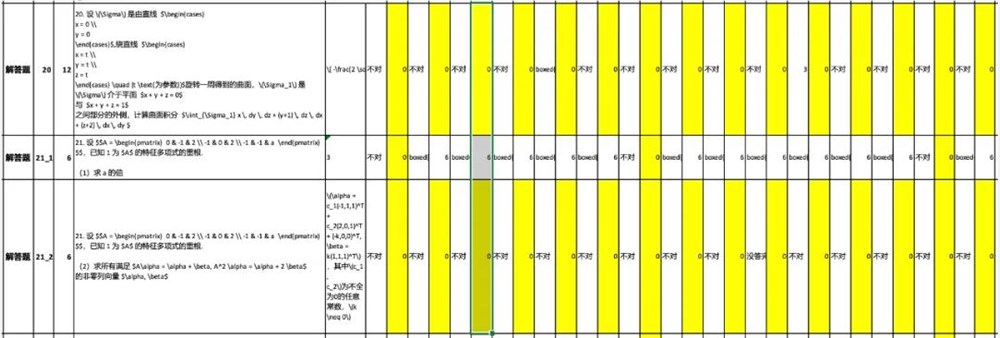
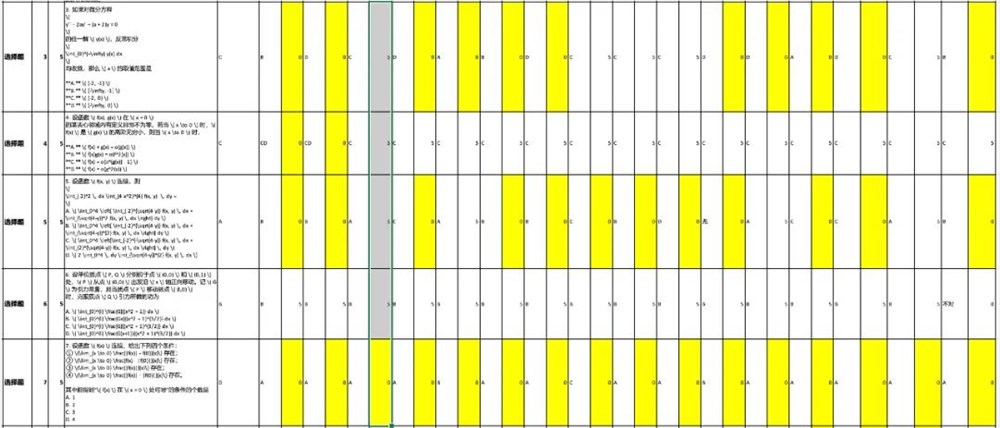
在数学二的评测中,各模型的分数分布较为分散。经统计分析发现,第3题、第5题、第7题成为所有模型犯错的集中区域。具体错题分布情况如下图所示:

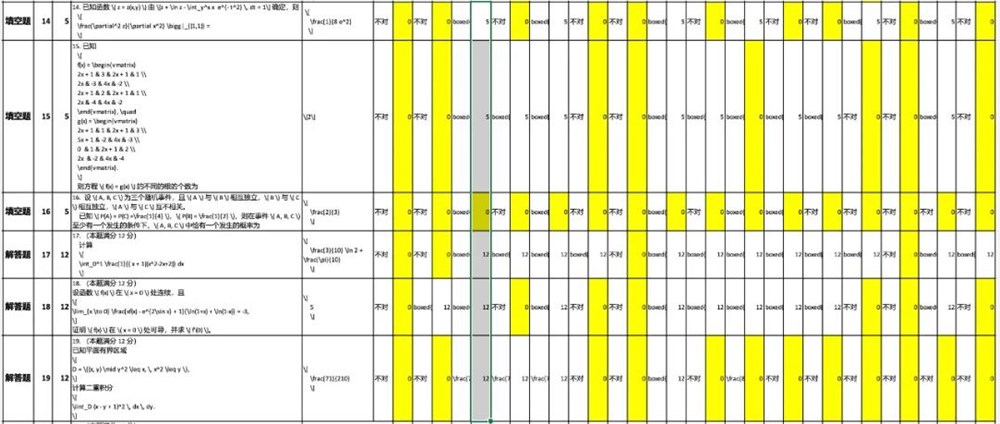
针对数学三的评测结果显示,模型出错的重灾区主要集中在第14题、第15题、第16题、第19题。相关错题分布情况如下图所示:

综合上述各试卷错题的具体分析,我们可以清晰地看到,GPT-o1(阴影列所示)在总计66道题目中,仅答错3.5道题;并且 GPT-o1答错的题目,其他模型亦普遍存在错误,这显示了GPT-o1目前依然是深度推理模型的天花板。
基础模型 vs 深度思考模型
最后,为了全面深入地探究各模型厂商在深度思考能力优化方面所取得的成果,测评团队对相应基础模型与深度思考模型进行了细致对比分析。
需要说明的是,此处对比并非意味着各深度思考模型是基于对应基础模型所做优化,其主要目的在于直观呈现各厂商在模型综合能力提升方面的进展与成效。
相关对比结果如下图所示:
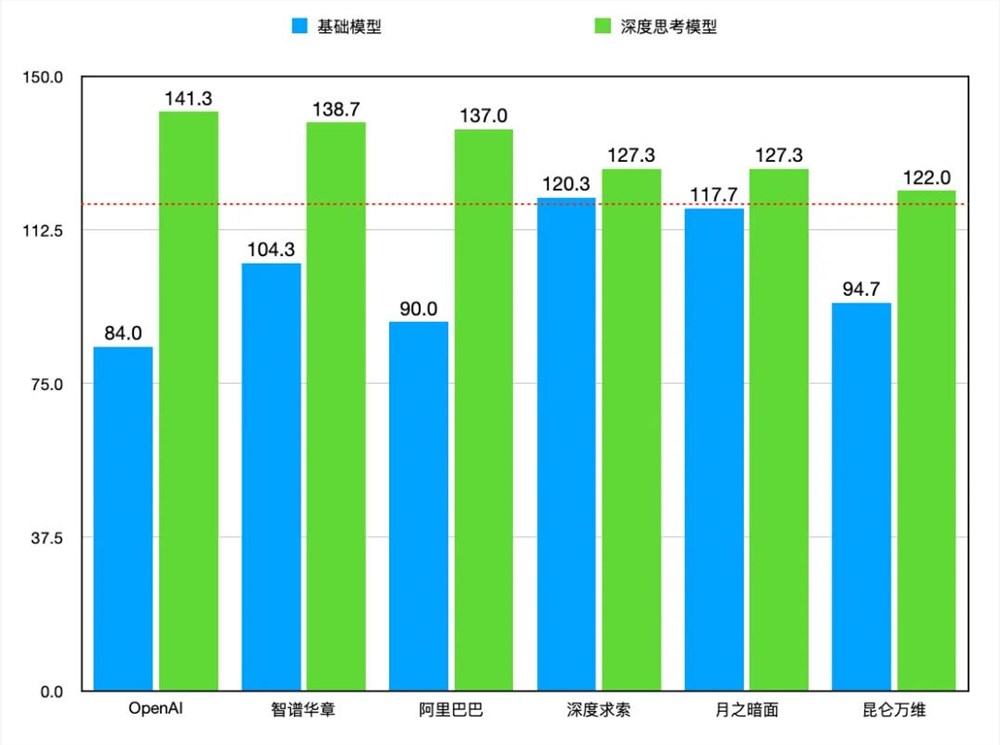
注:OpenAI 的基础模型采用的是 GPT-4o。
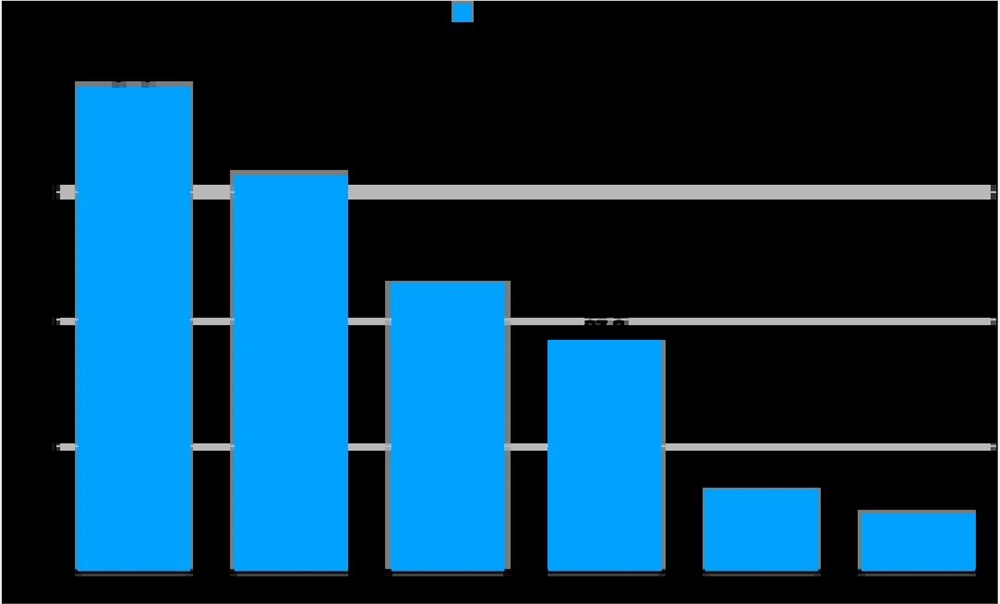
通过对比分析,OpenAI 的深度思考模型 GPT-o1相较于基础模型 GPT-4o,提升幅度最为显著,达到57.3分。紧随其后的是阿里的 Qwen 模型和智谱的 GLM 模型,提升幅度分别为47.0分和34.3分。
另外,深度求索和月之暗面的提升幅度相对较小,这主要是由于其基础模型本身分数较高。以深度求索为例,其基础模型 DeepSeek-v3初始分数高达120.3分,在参评基础模型中位居榜首。
在本次测试中,测评团队选取表现最为优异的基础模型 DeepSeek-v3作为参照基准,进而对各厂商深度思考模型的性能提升情况进行评估,相关数据呈现如下图所示:
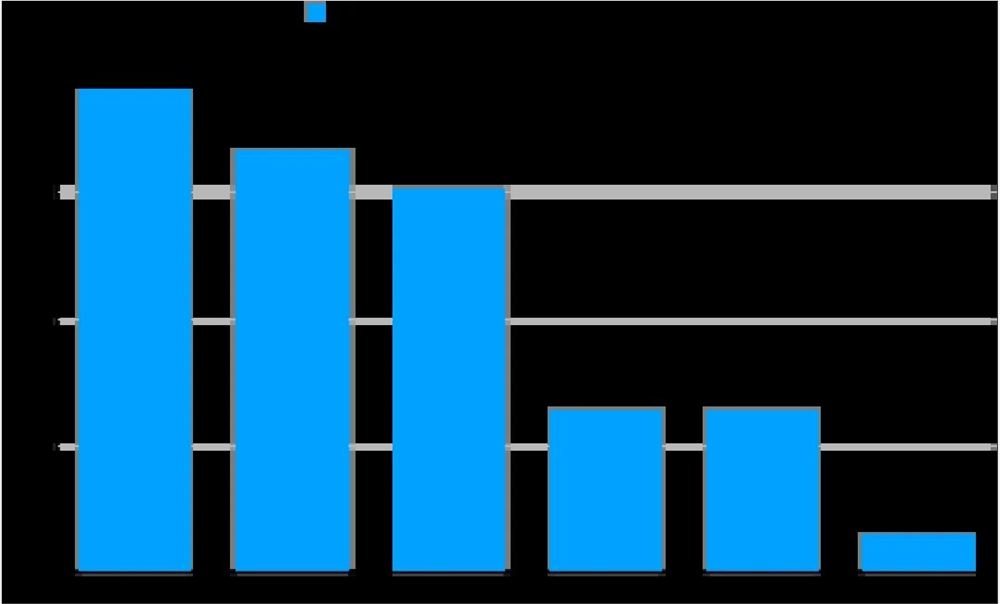
可以看出,OpenAI、智谱、阿里在深度思考模型上的性能提升做了很大的优化,而 DeepSeek-v3等其他模型在本项测试中的结果基本接近。
这些测试结果一一看下来,我们可以发现:虽然 OpenAI 的 o1在深度推理方面仍然是最强的,但国产推理大模型正在逐渐缩小与它的差距,此次智谱 GLM-zero-preview 和阿里 QwQ 的成绩说明了这一点。