Meta Platforms今日发布其Llama模型的全新精简版本,包括Llama3.21B和3B两款产品,首次实现了大规模语言模型在普通智能手机和平板电脑上的稳定运行。通过创新性地整合量化训练技术与优化算法,新版本在保持原有处理质量的同时,将文件体积缩减56%,运行内存需求降低41%,处理速度更是提升至原版4倍,单次可连续处理8,000字符文本。
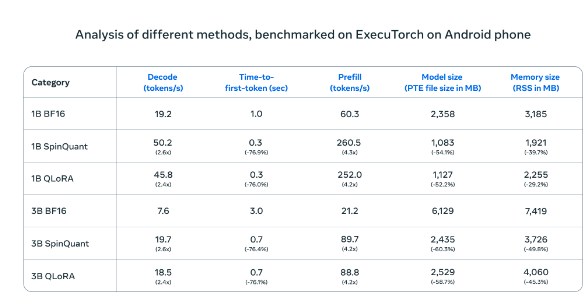
在 Android 手机上进行测试时,Meta 的压缩 AI 模型(SpinQuant 和 QLoRA)与标准版本相比,速度和效率都有显著提升。较小的模型运行速度提高了四倍,而内存占用却减少了
在OnePlus12手机的实际测试中,这款压缩版本展现出与标准版本相当的性能表现,同时大幅提升了运行效率,有效解决了移动设备算力不足的长期困扰。Meta选择采取开放合作的市场策略,与高通、联发科等主流移动处理器制造商展开深度合作,新版本将通过Llama官方网站和Hugging Face平台同步发布,为开发者提供便捷的接入渠道。
这一策略与行业其他巨头形成鲜明对比。当谷歌和苹果选择将新技术与其操作系统深度整合时,Meta的开放路线为开发者提供了更大的创新空间。此次发布标志着数据处理模式正从集中式服务器向个人终端转变,本地处理方案不仅能更好地保护用户隐私,还能提供更快捷的响应体验。
这项技术突破可能引发如同个人电脑普及时期的重大变革,尽管仍面临设备性能要求、开发者平台选择等挑战。随着移动设备性能的持续提升,本地化处理方案的优势将逐步显现。Meta期望通过开放合作的方式,推动整个行业向更高效、更安全的方向发展,为移动设备的未来应用开发开辟新途径。