在当今快速语音合成转换技术背景下,语音伪造日益严重,用户隐私和社会安全带来了不小的威胁。近日,浙江大学智能系统安全实验室和清大学联合发布了一种新型的语音伪造检测框架,名为 “SafeEar”。
这一框架致力于在保护语音内容隐私的同时,实现高效的伪造检测,充分应对语音合成带来的。
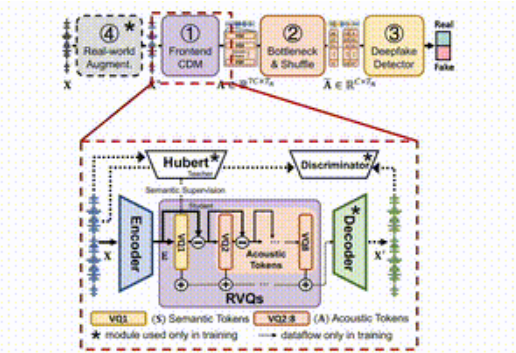
SafeEar 的思想是通过设计基于神经音频编解码器的解耦模型,巧妙地将语音的声学与语义信息分离。这意味着,SafeEar 仅依赖声学信息进行伪造检测,而无需接触音的完整内容,这样就能有效防止隐私泄露。
整个框架分为四个主要部分。
首先,前端解耦模型负责从输入的语音中提取目标声学特征;其次,瓶颈层和混淆层则通过降维和打乱声学特征,提高了对内容窃取的抵御能力;第三,伪造检测器利用了 Transformer 分类器来判断音频是否被伪造;最后,真实环境增强模块则通过模拟不同的音频环境,进一步了模型的检测。
项目入口:https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
经过在多个基准数据集上的实验,研究团队发现 SafeEar 的错误率低至2.02%。这意味着它在识别深伪音频方面非常有效!而且,SafeEar 还能够保护五种语言的音频内容,使其不易被机器或人耳解析,单词错误率高达93.93%。同时,通过测试,研究人员发现攻击者无法恢复被保护的语音内容,显示出该技术在隐私保护方面的优势。
此外,SafeEar 团队还构建了一个包含150万条多语言音频数据的数据集涵盖了英语、中文、德语法语和意大利语等多种,为未来的语音伪造检测和研究提供了丰富的基础资料。
SafeEar 的推出不仅为语音伪造检测领域带来了新的解决方案,也为保护用户的语音隐私铺平了道路。
划重点: