在人工智能迅猛发展的今天,语音合成和转换技术日新月异,为我们带来了无比真实、自然的音频体验。然而,这些技术的进步也带来了潜在的安全隐患,特别是"语音克隆"技术可能被不法分子利用,威胁个人隐私和社会稳定。
针对这一挑战,浙江大学智能系统安全实验室和清华大学携手推出了一个革命性的语音伪造检测框架——SafeEar。这个框架不仅能高效检测伪造音频,还能在检测过程中保护用户的语音隐私,实现了安全与隐私的双重保障。
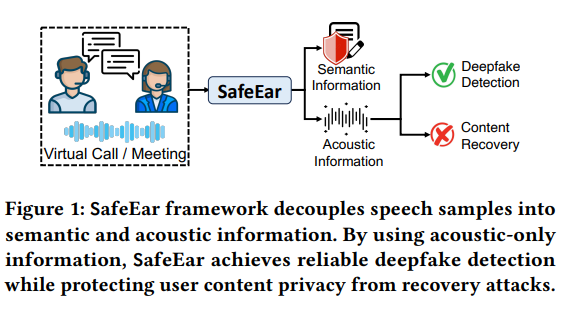
SafeEar的核心技术在于其采用的基于神经音频编解码器的解耦模型。这一创新设计能够将语音的声学特征与语义信息分离,仅依靠声学特征进行伪造检测。这不仅大幅提升了检测准确性,更重要的是在检测过程中不会泄露语音内容,有效保护了用户隐私。
该框架的结构包括前端解耦模型、瓶颈层、混淆层、伪造检测器以及真实环境增强等多个模块。通过这些模块的协同工作,SafeEar在面对各种伪造技术时展现出卓越的检测能力,误报率低至2.02%,几乎达到了当前最先进技术的水平。更令人欣喜的是,实验证明攻击者无法从声学信息中恢复出原始语音内容,充分证明了SafeEar在隐私保护方面的出色表现。
SafeEar的前端模块采用创新的解耦模型,能在分离和重建语音特征的过程中有效区分声学和语义信息。随后,瓶颈层和混淆层通过降维和随机混淆进一步保护语音信息,即使面对最先进的语音识别模型,也能有效防止真实信息被提取。
在伪造检测方面,SafeEar采用了基于声学输入的Transformer分类器,提高了检测的精准度和效率。此外,通过多种音频编解码器模拟不同环境下的音频情况,SafeEar还增强了模型的环境适应性。
经过一系列严格的实验测试,SafeEar不仅超越了许多传统检测方法,还在音频伪造检测领域树立了新的标准。更重要的是,SafeEar能在实际应用中实时保护用户的语音隐私,为智能语音服务的安全发展提供了强有力的支持。
通过这项技术,浙江大学和清华大学不仅开创了语音伪造检测的新领域,还构建了一个包含多种语言和声码器的丰富音频数据集。这为未来的研究和应用奠定了坚实的基础,使用户在享受便捷语音服务的同时,也能获得更好的隐私保护。
SafeEar的问世无疑为我们应对AI时代的隐私挑战提供了一个强有力的工具,让我们在享受技术便利的同时,也能更好地保护自己的隐私安全。
论文地址:https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf