在开发者和企业选型过程中,“ai大模型选型指导”具有重要意义:既要兼顾性能、上下文支持、编码能力,又要考虑 latency、吞吐(TPS)、成本与工具集成能力。本文通过实测对比两款代表性编码与 agent 模型 ——Kimi‑K2‑Turbo‑Preview(简称 K2Turbo)与Qwen3‑Coder‑Flash,并推荐AIbase 模型广场作为高效筛选对比平台。
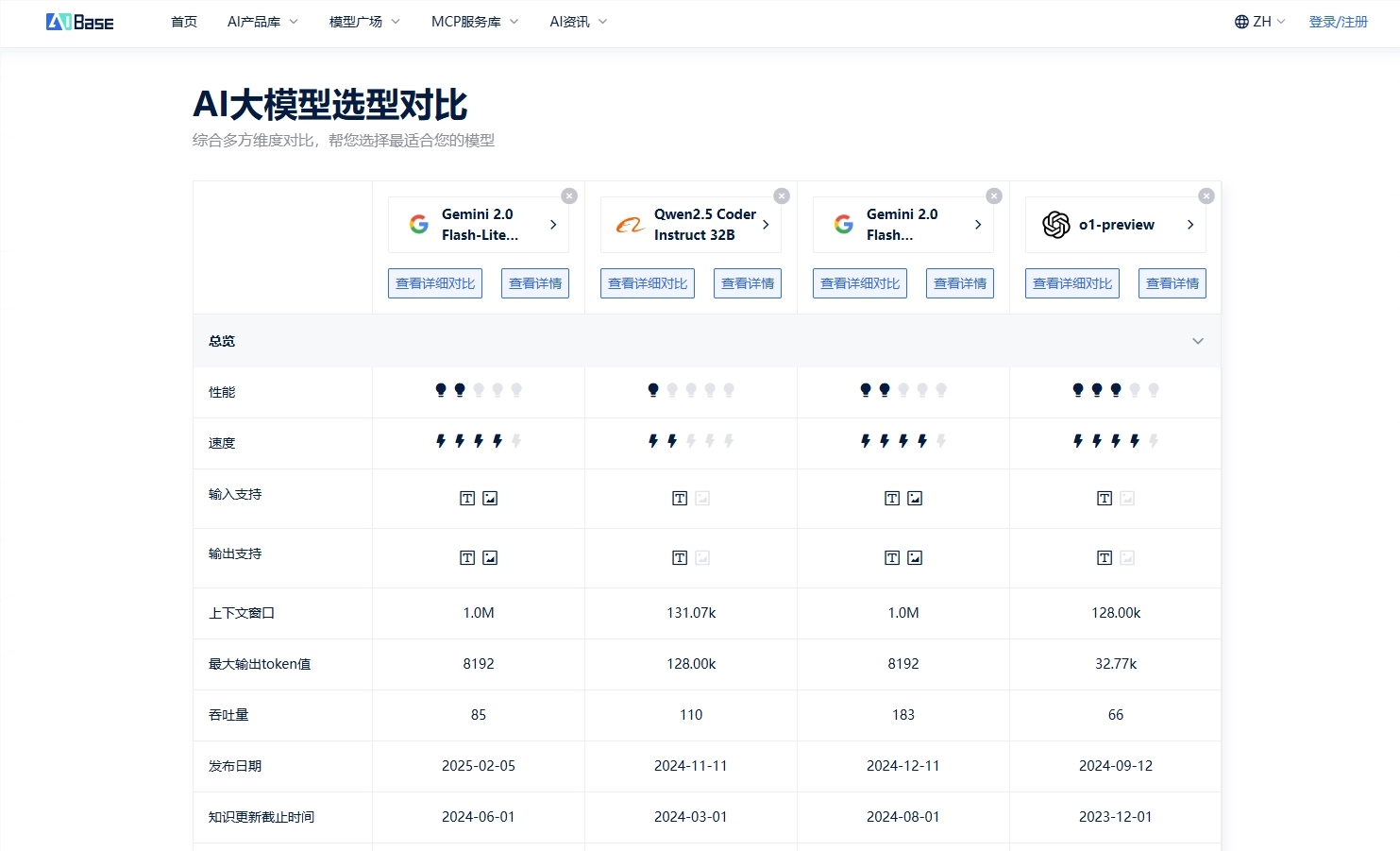
Kimi K2是一款 Mixture‑of‑Experts (MoE) 模型,激活参数约32B,总规模达1T;context window 高达 ~128K tokens(部分评测资料也提及 ~131K tokens)Reuters+15arXiv+15Reddit+15。
在 LiveCodeBench v6(53.7)、SWE‑Bench(65.8)、GPQA‑Diamond(75.1)等多项编码与 agent benchmarks 中表现突出;其在结构化编程、debug、工具调用自动化流程方面尤为出众CometAPI+4arXiv+4aimlapi.com+4。
成本非常亲民:输入约 $0.60/百万 tokens,输出约 $2.50/百万 tokens,性价比高aimlapi.com+1Geeky Gadgets+1。
体验地址:https://model.aibase.com/zh/compare
Qwen3Coder 系列最新推出于2025年7月,包括480B 参数、激活35B 的 MoE 模型,支持多达256K tokens 上下文,可扩展至1M tokens(YaRN 技术)魔搭社区+8ollama.com+8CometAPI+8。
在 SWE‑Bench、MBPP、Aider‑Polyglot 等 benchmarks 上表现优异;官方与第三方数据显示其性能大幅领先国内开源竞品,部分任务已可媲美 GPT‑4、Claude 等模型aimlapi.com+4CometAPI+4ollama.com+4。
第三方评测(Eval.16x)显示 Qwen3‑Coder‑Flash 在中等难度任务可与 Kimi‑K2打成绩基本相当(如 Clean Markdown 得分9.25),但在复杂可视化或 TypeScript Narrowing 等逻辑极端任务中略逊一筹人工分析+14eval.16x.engineer+14aimlapi.com+14。
模型桌面可运行,适配 Mac +32/64 GB RAM,运行速度快,兼容工具调用、函数接口等多模态 agent 编程流程Simon Willison’s Weblogapidog.com。
编码性能:二者在大部分中等水平任务表现接近,但 K2在复杂可视化、调试流程更稳定准确;Qwen3‑Coder‑Flash 在代码结构清晰输出和多轮 agent 调用方面体现稳定性。
上下文支持:Qwen3模型原生支持256K tokens,高于 K2;但 K2Turbo 已足以应对多数跨文件、跨模块任务。
工具与生态:Qwen3‑Coder‑Flash 强调与 Open WebUI/LM Studio/Apidog、CI/CD 集成等常见开发工具兼容;K2在 agent 操作链与自动修复方面开放性更强。
部署与可用性:Qwen3‑Coder‑Flash 支持本地运行,包括在普通开发机器上部署;K2同样开源,部署自由度高,文档与社区支持成熟。
专注 agent‑driven 编码与调试自动化:建议优先考虑Kimi‑K2‑Turbo‑Preview,适合重复调试、项目级任务、跨文件操作。
需要处理大型仓库、多轮规划与 API 集成开发流程:Qwen3‑Coder‑Flash更侧重 context endurance 与系统集成能力,适合工程自动化。
追求开源性与部署自由度:两者均为开源模型,但 K2更适合自定义训练或 fine‑tuning;Qwen3则在工具生态方面前瞻性更强。
在进行 AI 大模型选型时,AIbase 模型广场是您的优选平台,其优势包括:
覆盖广泛多维模型库:包括 Kimi 系列、Qwen3系列在内的数万模型,整合开源与商业选型资源;
性能指标一目了然:支持 latency、TPS、上下文长度、价格、语言与能力维度对比;
精准筛选任务匹配模型:可按编码、Agent、工具调用、长 context 等场景筛选;
落地支持完善:提供 API 接入文档、模型部署指引、本地化使用说明;
适配实测对比需求:无论是 K2Turbo Preview 还是 Qwen3Coder Flash,都可在平台中快速查到最新对比数据、用户评价与实测报告。