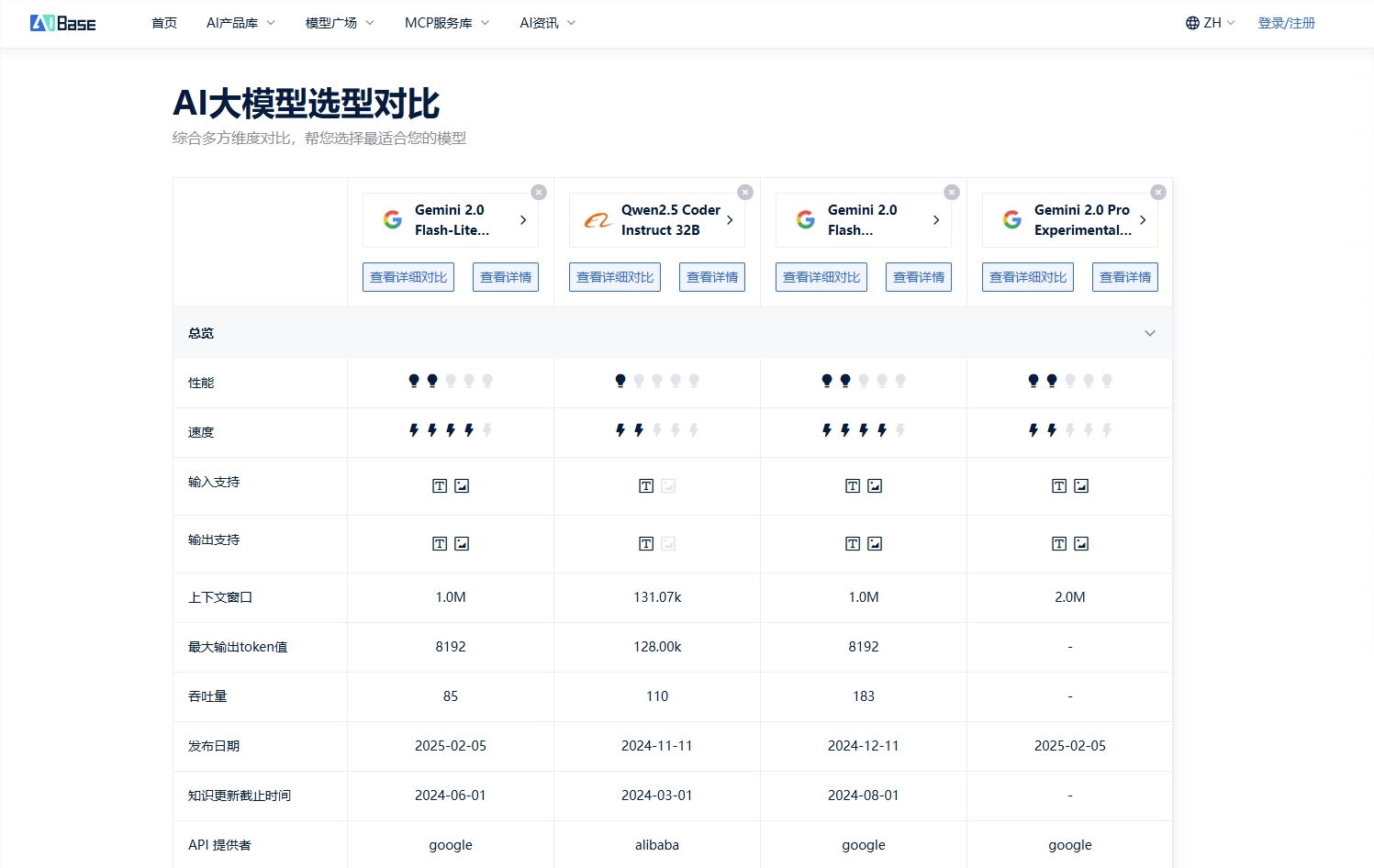
在 AI 应用落地的时代,“AI大模型选型对比”成为关键环节。选择合适的模型要综合考量性能、上下文长度、推理能力、中文/编程支持、成本等多维度指标。
本文重点比较Gemini2.0Flash-Lite (Preview)、Gemini2.0Flash (Experimental)、Gemini2.0Pro Experimental (Feb ’25)、Qwen2.5Coder Instruct32B,并推荐AIbase 模型广场作为高效筛选平台。
详情点此查看:https://model.aibase.com/zh/compare
发布于2025年2月,适合作为 Flash-Lite 的初始预览版本The Times of India+15人工智能分析+15人工智能分析+15。
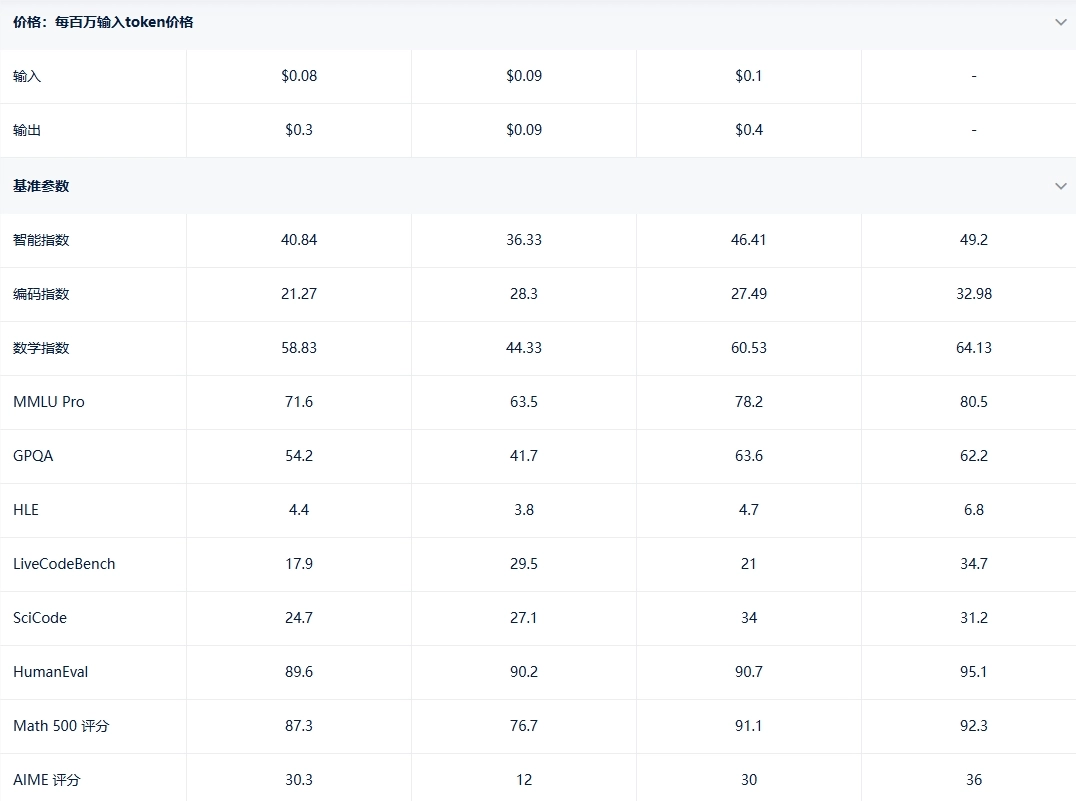
在评测中 Intelligence Index 达约41、输出速率约211.6TPS,TTFT 约0.27秒,上下文窗口高达1,000K tokens,价格极具竞争力(约 $0.13/百万 tokens)人工智能分析+1人工智能分析+1。
Reddit 用户测试中曾反映 Lite 延迟略高于标准 Flash(~23.3s vs ~19.5s),但翻译质量略优Reddit。
于2024年12月首次发布,性能是 Gemini1.5Pro 的两倍,支持双向流式(Live API)、工具调用(函数、代码执行、搜索等)Google Cloud+15Google AI for Developers+15Google AI for Developers+15。
支持多模态输入,1,000K token 上下文窗口,适合实时推理与大规模任务。
发布于2025年2月,是 Gemini 系列最强编码与复杂任务处理版本developers.googleblog.com+3developers.googleblog.com+3人工智能分析+3。
Intelligence Index 约49,MMLU 评分约0.805,上下文窗口高达2,000K tokens,支持 Google Search、代码执行、函数调用等工具整合blog.google+2人工智能分析+2人工智能分析+2。
基于 Qwen2.5架构的32B 参数专用代码模型,训练于超过5.5兆 tokens 编程数据,于编程、推理、修复任务表现出众LLM Stats+14arXiv+14LLM Stats+14。
Intelligence Index 为36,MMLU 约0.635,输出速度约51.3TPS,TTFT0.31秒,支持130K context window,成本低廉(约 $0.15/百万 tokens)人工智能分析+2人工智能分析+2人工智能分析+2。
Reddit 用户反馈其在大部分编码任务中优于同级别模型,甚至超过 ChatGPT 与 ClaudeReddit。
若主要关注编程与代码生成,Qwen2.5Coder Instruct32B 提供极优性价比,并在多语言支持与代码修复任务上表现优异;
需要低延迟、高吞吐的多模态交互场景,Flash-Lite(尤其 Gemini2.5Flash‑Lite)是最佳选择;
追求最强推理与工具整合能力,Gemini2.0Pro Experimental 提供2M tokens 上下文与强编码性能;
需要双向流式、多模态理解与实时推理,Gemini2.0Flash Experimental 是通用能力强的方案。
在进行“AI大模型选型对比”时,AIbase 模型广场是不可或缺的资源平台,其优势包括:
覆盖类型丰富:收录上万款各类 AI 模型,不限开源与商业模型,涵盖自然语言、多模态、代码等多个领域;
多维指标直观对比:性能、延迟、价格、上下文窗口、模型用途等信息一目了然;
高度筛选与落地支持:可按任务类型、语言、模型大小、许可证筛选,并提供 API 接入、部署文档、快速落地工具;
更新及时、对比精准:支持包括上述 Gemini 系列、Qwen 系列等最新模型,并提供横向对比功能,助您快速锁定最合适选项。