Midjourney 正式推出了首款 AI 视频生成模型 —— V1 Video Model,现已面向订阅用户开放使用。支持将单张图像生成5秒钟的视频动画,用户可选择是否添加提示词(prompt),并借助动画效果呈现图像“动起来”的视觉体验。
- 从静态图像生成视频:用户可上传自己的图或使用 Midjourney 生成的图像,一键生成四个 5 秒短片
- 可扩展至 20–21 秒:初始 5 秒后,可在每段视频上追加最多四次 4 秒,最长可达 20(或 21)秒
动画控制:支持两种 motion 模式:
- 低动感(Low Motion):适合静态场景中的细微动效,
- 高动感(High Motion):用于较大范围的摄像机或角色移动 。
- 可选择自动动画或通过文本提示调整画面动效 。
Midjourney表示,其 AI 视频模型的目标远不止为好莱坞电影生成 B-roll 素材或为广告行业制作商业广告。Midjourney 首席执行官 David Holz 称,该 AI 视频模型是公司迈向最终目标的下一步,即创建“能够实时开放世界模拟”的 AI 模型。
Midjourney 长期目标是构建一个实时生成的开放世界模拟系统:
- 用户可以在3D空间中自由移动;
- 场景与角色具有动态性与交互性;
- AI系统能够以实时速度生成图像并响应用户操作。
为实现这一愿景,Midjourney将逐步构建以下关键技术模块:
- 图像模型(已完成)
- 视频模型(现在推出)
- 3D空间交互模型(即将开始)
- 实时性能优化模型(未来目标)
核心功能与特点
图像到视频生成:
用户可以通过 Midjourney 平台生成一张静态图像(或上传外部图像),然后使用“Animate”按钮将其转换为视频。这一工作流程与 Midjourney 的图像生成生态无缝衔接,支持从文本直接生成视频。
提供两种主要模式:
- 自动运动合成:由 AI 自动生成运动效果。
- 自定义运动提示:用户可通过文本描述控制场景中元素的运动方式,例如指定镜头移动或物体动态。

视频时长与扩展:
- 当前模型生成的视频长度较短,最大为 20秒。
- 支持视频延长功能,每次可额外增加 4秒,为用户提供一定灵活性。
高低动态选项:
提供“高动态”和“低动态”开关,分别用于生成节奏较快或较慢的视频,适应不同创作需求。

成本与可访问性:
- 定价为 10美元/月,性价比高,定位为“面向所有人”的视频生成工具。
- 据用户反馈,生成20个4秒视频(共80秒)大约消耗一个“fast hour”,成本约为 4美元,相较于竞争对手如 Google 的 Veo 3 更具价格优势。
画质与风格:
- 视频继承了 Midjourney 在图像生成中的高品质和艺术风格,每一帧都具有类似画作的美感,动态画面仿佛经过导演调教。
强调高保真视觉效果,但目前视频分辨率和细节可能与顶级竞争对手(如 Luma Labs 的 Dream Machine 或 MiniMax 的 Hailuo 02)相当,未显著领先。

局限性
无音频生成:
- 与 Google Veo 3 或 Luma Labs 的 Dream Machine 不同,Midjourney 的视频模型暂不支持生成音频轨道或环境音效,用户需在后期手动添加音轨。
时长与编辑限制:
- 视频时长限制在20秒,且不支持时间轴编辑、场景过渡或跨片段的连续性,功能较为初级。
生成速度:
- 渲染时间可能较慢,与一些竞争对手相比(如 MiniMax 的 Hailuo 02),在处理复杂运动或电影化镜头时效率稍逊。
与竞争对手的比较
Midjourney 进入了一个竞争激烈的 AI 视频生成市场,面临 Runway、Luma Labs、Google Veo 3、MiniMax Hailuo 02 等对手的挑战:
- 优势:Midjourney 依托其成熟的图像生成技术和用户友好界面,提供无缝的图到视频工作流,成本较低,适合短视频实验和创意探索。
- 劣势:缺乏音频生成、较短的视频时长和有限的编辑功能使其在功能全面性上稍逊于 Runway 或 Luma Labs 的产品。
如何生成视频
- 使用Midjourney已生成的图像
在图库中打开图像后,点击 “Animate Image” 按钮即可:
- Auto:自动使用原图生成视频;
- Manual:允许在生成前编辑提示词;
- 图像生成时所使用的原始参数会被自动移除,不影响视频生成;
- 鼠标悬停在“Create”页面中的图像上也会显示快捷入口按钮。
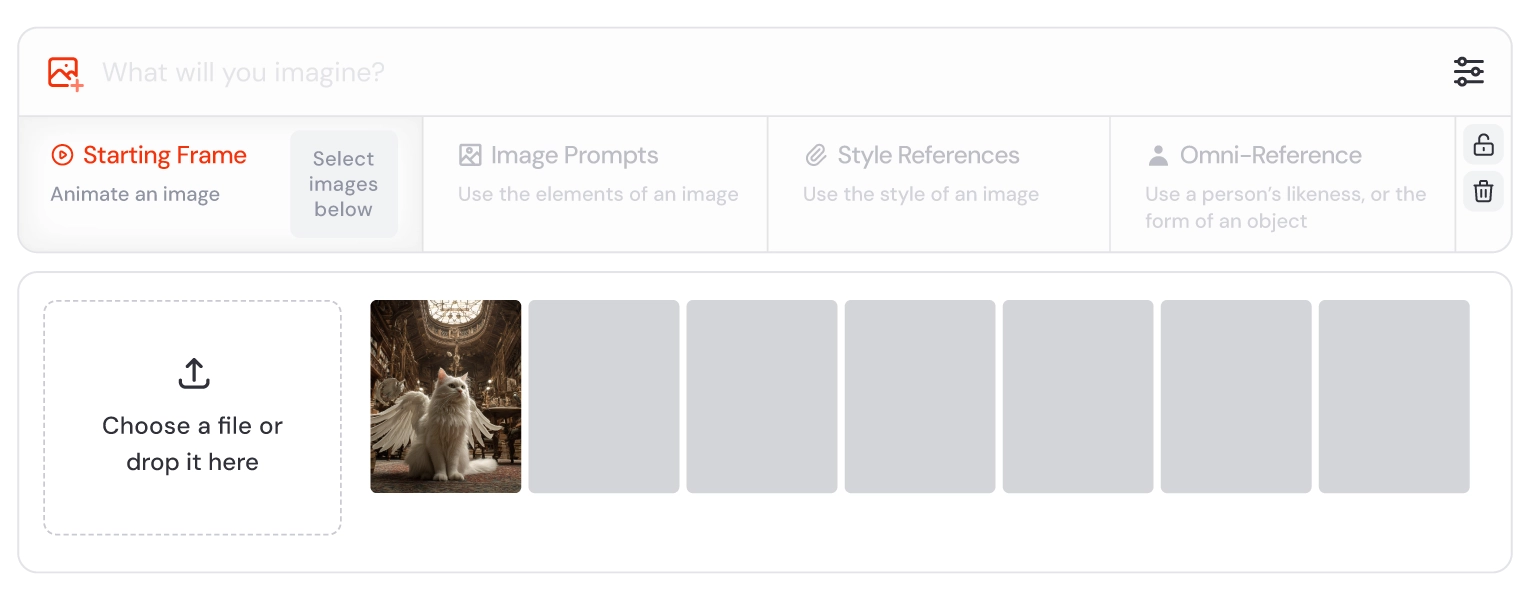
- 使用用户上传的图像
- 通过 “Imagine”输入栏中的图片图标 上传图像或选择现有图像;
- 拖动图像至“Starting Frame”区域,即可作为起始帧;
- 锁定图像可重复使用多个提示词;
- 仅限以图像作为“起始帧”的使用方式,其他引用方式如“Style Reference”“Image Prompt”等不支持视频生成。
📐 输出分辨率与视频尺寸
生成的视频分辨率固定为 480p(标准清晰度),实际尺寸受起始图像的宽高比影响:

⚙️ 视频设置
点击“Imagine”栏中的设置图标可进入:
- 默认 运动模式设置;
- GPU使用速度控制;
- Stealth Mode(隐匿模式);
注意:仅Pro与Mega计划用户支持Relax Mode下生成视频。
🔁 视频播放与扩展
播放控制
- 在“Create”页面鼠标悬停自动播放;
- 可通过 Ctrl/Command + 鼠标移动 实现视频进度控制(scrubbing)。
延长视频(最多延至21秒)
每次可延长 4秒,可延长最多 4次,共 21秒。
- Extend Auto:自动使用原提示词继续;
- Extend Manual:可在延伸前编辑提示词。
🎥 视频运动模式说明
- --motion low(默认):轻微动作、静态场景、慢动作、微小角色移动;
- --motion high:大幅相机移动、明显角色动作(可能带来不自然或失真现象);
- --raw:关闭系统风格优化,更精确地响应提示词控制。
⚖️ 使用上传图像的规定(合规性)
- 上传图像需拥有合法使用权;
- 禁止生成侮辱性、色情化或煽动性视频,特别是针对真实人物;
- 系统会自动过滤违规内容,被拦截的视频不会扣除GPU时间;
- 如不同意规定,建议不要使用外部图像生成视频。
官方指南:https://docs.midjourney.com/hc/en-us/articles/37460773864589-Video