@ArtificialAnlys 发表文章称 DeepSeek 刚刚发布的模型 R1 的后训练更新版本 R1-0528,显著提升了模型在多个智能评估中的表现,得分跃升至 68 分,与 Google Gemini 2.5 Pro 并列为全球第二,仅次于 OpenAI 系列。
跻身全球第二大人工智能实验室行列。
此次更新并未更换架构,而是通过强化学习技术优化模型推理能力,使其在数理、代码生成、科学推理等多项能力指标上大幅进步,展现出深厚的后训练调优能力。同时,token 使用量的增加也说明其响应更加详尽、考虑更全面。
在全球 AI 格局中,这标志着开源模型在智能能力上已接近闭源顶级模型水平。更重要的是,来自中国的 DeepSeek 正逐步缩小与美国领先 AI 实验室之间的差距,在某些领域已实现领先。
这一趋势说明,通过强化学习等策略的精细调优,即便在计算资源不如 OpenAI 的前提下,其他 AI 实验室也有机会追赶并接近最先进的智能表现。
以下是其内容翻译
Artificial Analysis (@ArtificialAnlys) 发布于 5 月 29 日:
DeepSeek 的 R1 超越了 xAI、Meta 和 Anthropic,与 Google 齐肩成为全球第二大 AI 实验室,同时稳坐开源权重模型的头把交椅。
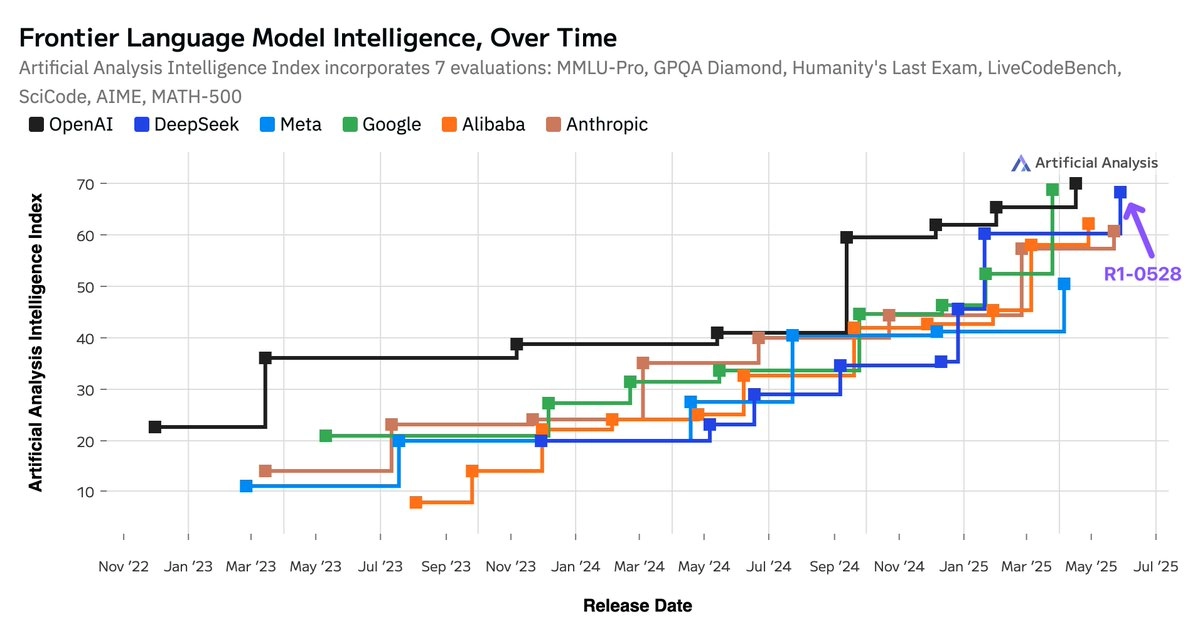
DeepSeek R1 0528 在我们独立运行的 7 项主要评估组成的 Artificial Analysis Intelligence Index 中得分从 60 提升至 68。这个涨幅相当于 OpenAI 的 o1 与 o3(从 62 到 70)之间的差距。
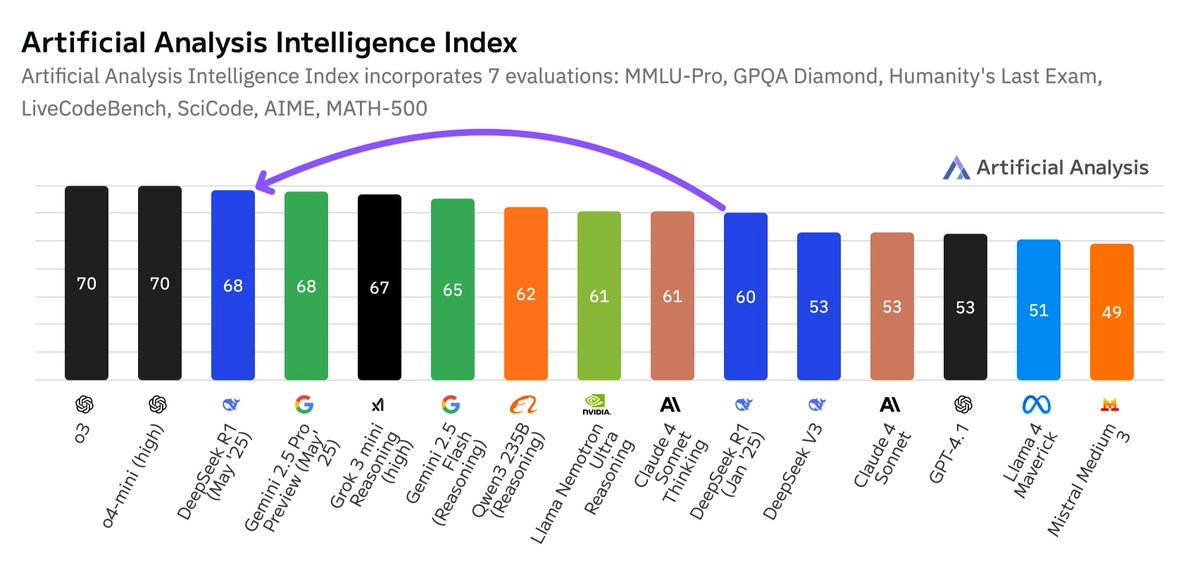
这使得 DeepSeek R1 智能水平高于 xAI 的 Grok 3 mini(高配版)、NVIDIA 的 Llama Nemotron Ultra、Meta 的 Llama 4 Maverick、阿里巴巴的 Qwen 3 253,并与 Google 的 Gemini 2.5 Pro 持平。
模型提升细节如下:
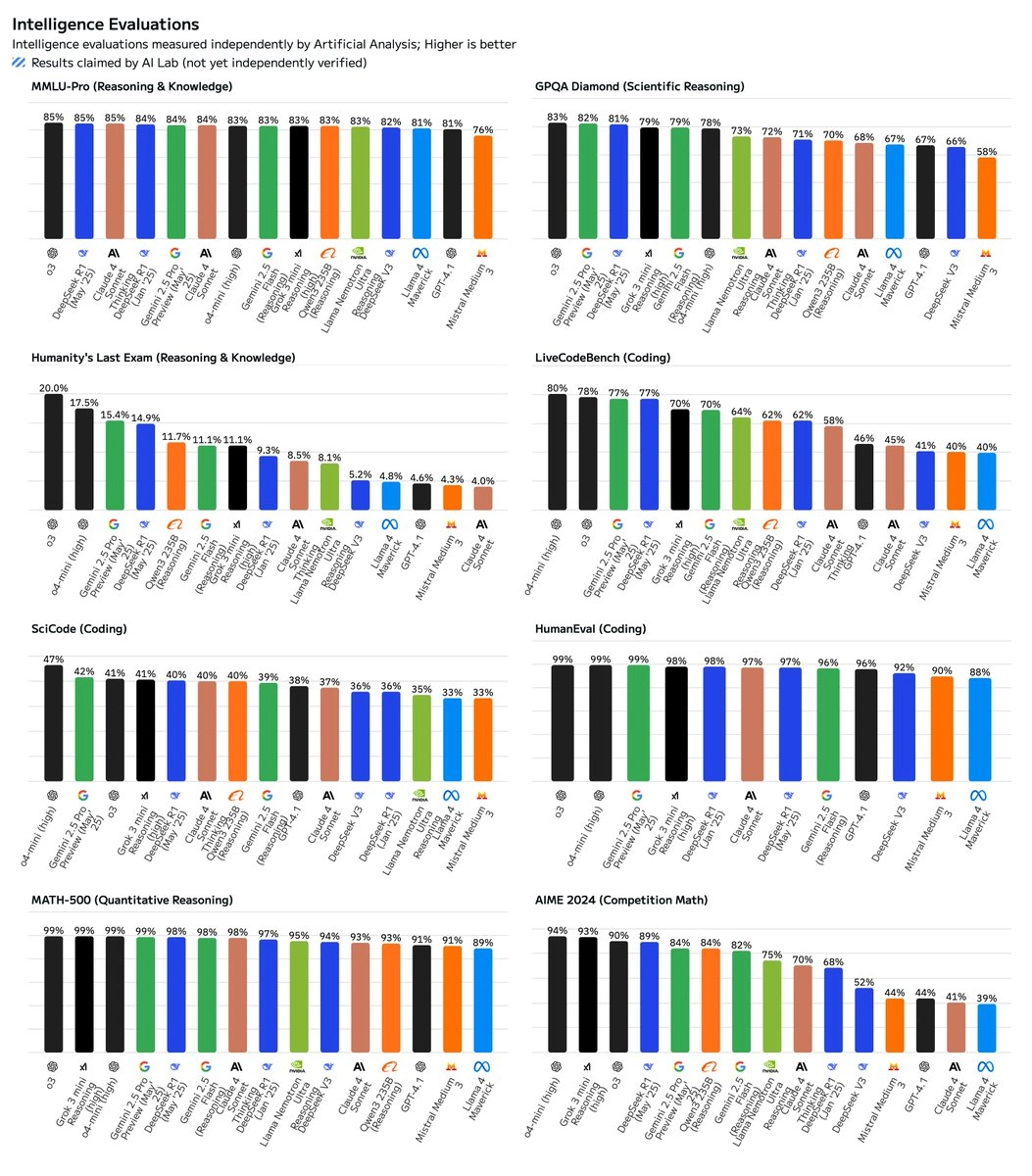
- 🧠 全面提升智能水平:在 AIME 2024(竞赛数学,+21 分)、LiveCodeBench(代码生成,+15 分)、GPQA Diamond(科学推理,+10 分)、Humanity’s Last Exam(推理与知识,+6 分)方面表现尤为突出。
- 🏠 架构未变:R1-0528 是一次后训练更新,未改变 V3/R1 架构——仍是一个拥有 671B 总参数(37B 激活参数)的超大模型。
- 🧑💻 编程能力显著增强:在人工分析编程指数中,R1 现已与 Gemini 2.5 Pro 持平,仅落后于 o4-mini(高配)和 o3。
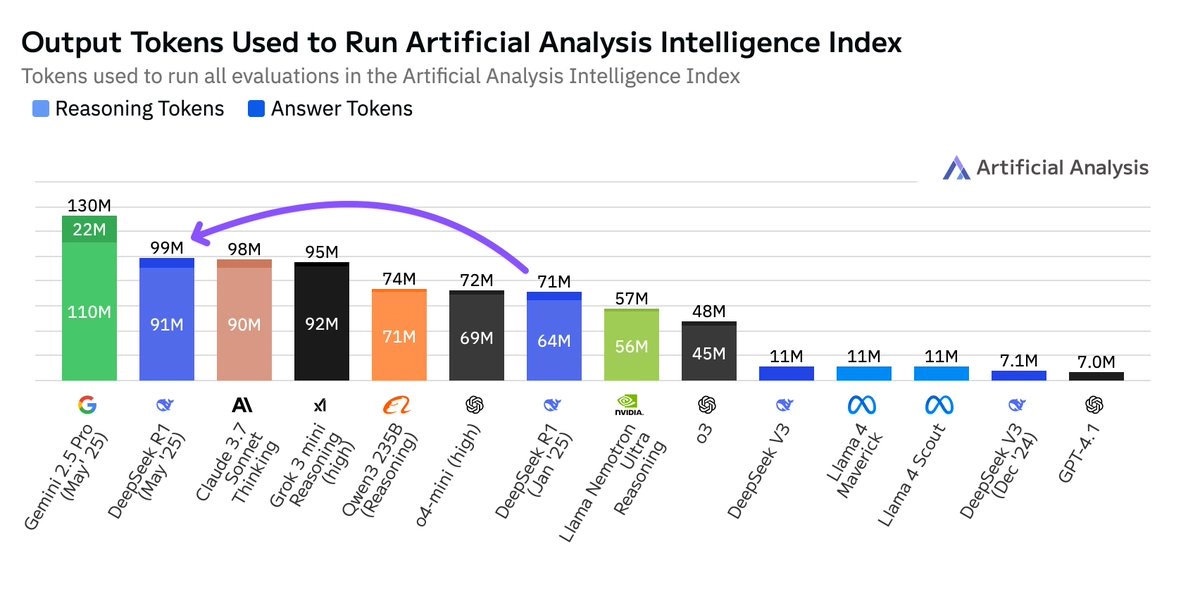
🗯️ Token 使用显著增加:R1-0528 在评估中使用了 9900 万个 token,比原版 R1 的 7100 万多出 40%。也就是说,新版本“思考更久”。但这仍不是最高,Gemini 2.5 Pro 使用的 token 数比 R1-0528 还多 30%。
关于 AI 的一些结论:
- 👐 开源与闭源模型的差距空前缩小:开源权重模型依然能保持与专有模型相当的智能增长。DeepSeek R1 自一月首次登顶全球第二后,此次更新再次回到同一位置。
- 🇨🇳 中美技术角力并驾齐驱:中国 AI 实验室的模型已几乎追平美国同行。本次发布再次延续这一趋势。目前,DeepSeek 在 AI 智能指数上领先 Anthropic 与 Meta。
🔄 强化学习推动智能提升:DeepSeek 在架构和预训练不变的前提下,通过后训练(尤其是强化学习)显著提升智能,验证了 RL 在推理模型中的关键作用。OpenAI 在 o1 到 o3 之间扩大了 10 倍 RL 计算量,而 DeepSeek 表现出其有能力跟上这一节奏。与预训练相比,扩展 RL 所需计算资源更少,效率更高,有利于资源有限的 AI 实验室。
详细报告:https://artificialanalysis.ai/models/deepseek-r1/providers