Google 在 I/O 2025 上正式推出 Google AI Studio 的全新升级,面向开发者提供更强的 AI 原生开发平台。这次更新显著提升了 Gemini 模型的可用性、集成性与部署便捷性,打造“一站式 AI App 构建平台”。
核心更新亮点
1. 原生代码生成能力(Native Code Generation)
- 引入 Gemini 2.5 Pro 到 Studio 的代码编辑器,支持将文本/图像/视频提示直接生成 Web 应用;
- 新增 Build Tab:可快速构建、部署基于 AI 的 Web 应用(支持一键部署到 Cloud Run);
- 支持迭代开发:可在聊天对话中修改代码、查看 diff、返回历史版本。
2. 媒体生成中心(Generate Media)
- 集成 Imagen(图像)、Veo(视频)、Lyria(音乐) 与 Gemini(文本)多模态生成能力;
- 新增交互式音乐生成 App:PromptDJ,基于 Lyria RealTime 实现。
3.音频能力升级:语音更自然、响应更智能
🗣️ Gemini 2.5 Flash 支持的原生语音对话(Live API):
- 支持 30 多种自然人声(男女、口音、情感可调);
- 引入 主动音频识别能力:模型可区分用户说话与背景杂音,仅在适当时机应答;
- 更贴近人类自然对话节奏,适用于客服、虚拟助手、交互剧情等场景。
🔉 文本转语音(TTS)升级:
- 单人或多人对话生成;
- 支持语速、语调、情绪的多维控制;
Agentic 与工具生态
- 新增「Build」标签页
从文本、图像或视频 prompt 快速生成 Gemini 应用原型,集成 Gemini 2.5 Pro 模型。 - 智能代码助手
支持编辑现有应用代码,查看差异(diff)、回滚历史版本。 - 一键部署到 Cloud Run
无需配置服务器,自动托管 Gemini API Key,快速上线到生产环境。 - 全新「Generate Media」页面
集中调用 Imagen(图像)、Veo(视频)、语音生成等多模态模型。 - 支持 MCP(Model Context Protocol)
原生集成开源标准,方便构建复杂 AI 应用并对接第三方工具。 - URL Context 实验功能
模型可读取网页链接内容,用于摘要、比对、研究与查证。
🧱 1. 新增“Build”标签页:从 prompt 到 App 的极简生成
- 新的 Build 面板集成了 Gemini 2.5 Pro 模型
- 与 Google 的 GenAI SDK 紧密耦合
- 支持从文字、图像或视频 prompt 直接生成应用原型
- 自动生成 UI + 功能代码(适合前端或全栈原型搭建)
🛠️ 2. 代码助手功能上线:支持版本对比和撤回
- 可对已有项目进行 AI 辅助修改
- 提供“查看变更(diff)”能力
- 支持回退至历史版本(checkpoint 机制)
- 极大提升多人协作与版本控制效率
☁️ 3. 一键部署到 Cloud Run:零运维 AI App 生产化
- 应用构建完成后,可直接部署到 Google Cloud Run
- Gemini API Key 会自动保存在服务端,提升安全性
- 便于开发者将原型迁移至线上环境投入使用
🖼️ 4. 新增“Generate Media”页面:整合所有多模态模型能力
集中访问和使用:
- Imagen(图像生成)
- Veo(视频生成)
- Gemini(语言+跨模态生成)
- Native speech 模型(语音生成)
- 一站式调用多模态生成模型,适配创意、教育、内容等应用场景
🧩 5. 支持 MCP(Model Context Protocol)标准:增强生态兼容性
- Google GenAI SDK 现原生支持 MCP 协议
- 便于接入开源工具和第三方框架
为构建复杂对话系统或多模型交互应用提供标准接口
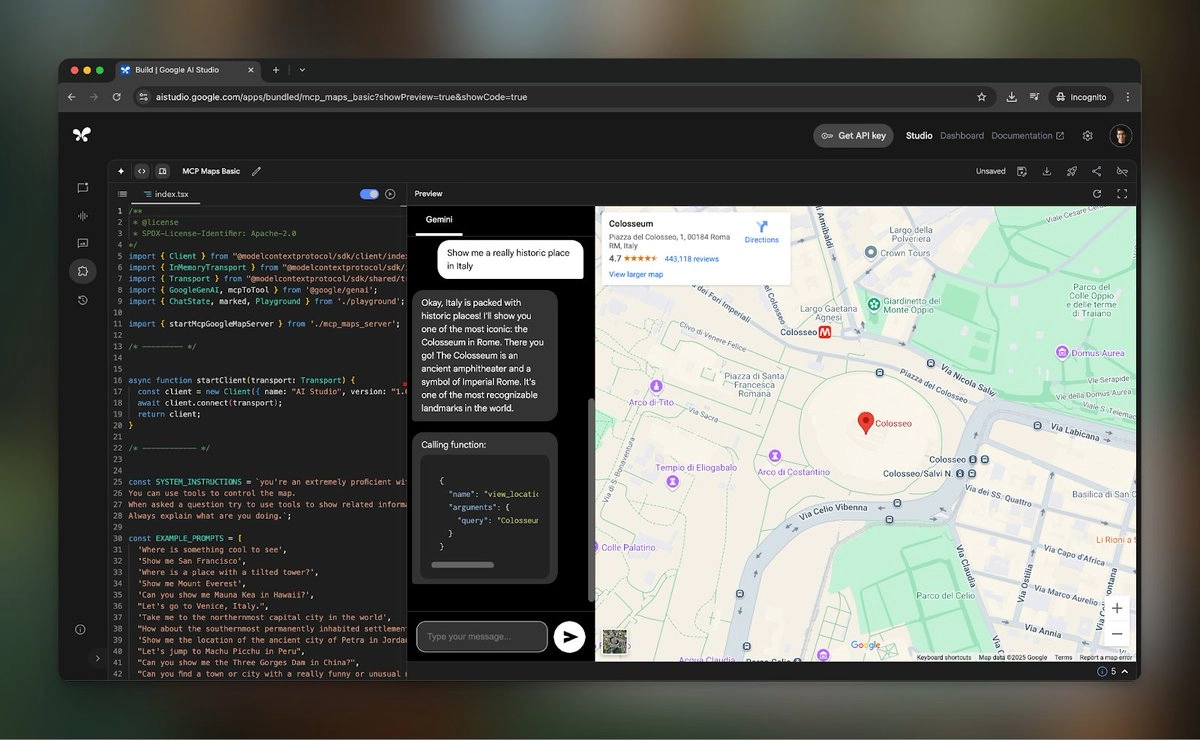
📸 示例截图展示:Colosseum 查询与代码并列视图
🌐 6. 实验功能:URL Context,让模型“读网页”
- 用户可直接输入网页链接
Gemini 可访问网页内容,用于:
- 事实核查(fact-checking)
- 内容摘要
- 信息对比
- 学术或企业级研究场景
详细内容:https://developers.googleblog.com/en/google-ai-studio-native-code-generation-agentic-tools-upgrade/