在Google I/O 2025 大会上,Google 宣布了 Gemini 2.5 Pro 和 Flash 的功能增强,同时引入了多个突破性能力,包括:
- 高阶推理模式 Deep Think
- 原生音频交互能力
- 多语言语音生成
- 电脑操作能力(Project Mariner)
- 安全性与开发体验优化

Gemini 2.5 Pro:全面升级的通用大模型
✅ 更强的智能表现
学术与实用能力大幅提升:
- 在 WebDev Arena 排行中拿下最高 ELO 评分 1415(网页开发任务);
- 在 LMArena 的人类偏好评分中,多个维度居首;
100 万 token 上下文窗口:
- 支持复杂多轮对话、长篇文档处理、视频逐帧理解。
📚 教育场景的首选模型
集成 LearnLM(由教育专家协作训练):
- 更擅长解释知识、引导学习;
- 在教学对话、人类评测中,超越 GPT-4 与 Claude 等竞品。
- 成为当前最适合学习与教学场景的通用模型之一。
Deep Think:实验性“深度思维”模式
🧠 高阶逻辑能力
- Deep Think 是 Gemini 2.5 Pro 的一项新实验特性,支持模型“多假设并行推理”,在回答前模拟多路径思考;
目前已在以下高难任务中表现优异:
- USAMO 2025(美国数学奥林匹克):领先成绩;
- LiveCodeBench(代码能力竞赛任务):排名第一;
- MMMU(多模态推理):准确率达 84.0%。
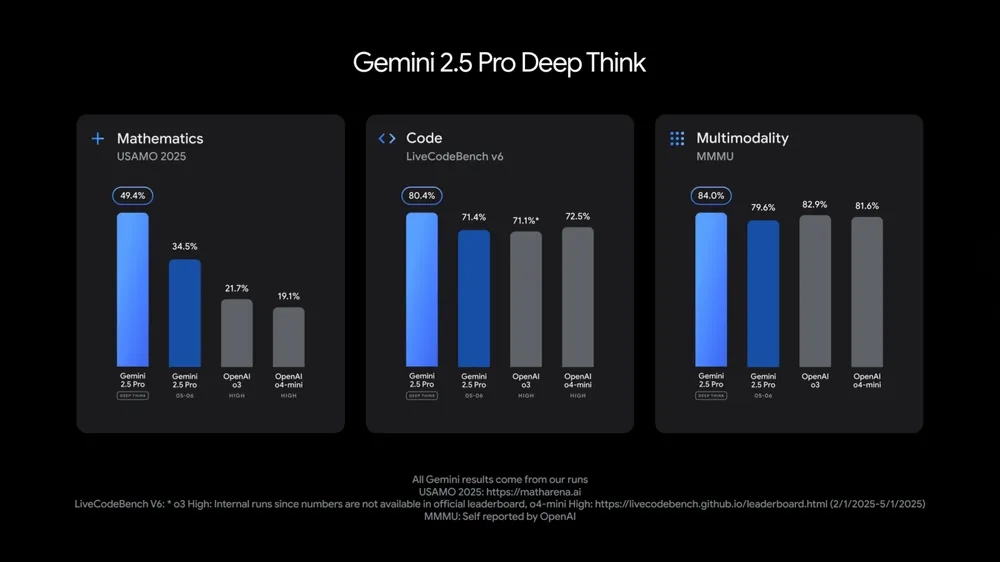
⚠️ 当前状态
- 仅开放给“受信开发者”(trusted testers);
- 正在接受更严格的安全评估,预计未来逐步放开。
Gemini 2.5 Flash:轻量高效的“AI 工具马达”
⚡ 更快、更省、更聪明
- 设计目标:低延迟 + 高吞吐量 + 低成本;
- 在推理、多模态处理、长文本任务中全面提速;
- Token 使用减少 20–30%,显著降低推理成本。

📦 使用渠道
- 现已通过 Google AI Studio、Vertex AI 及 Gemini App 向开发者与公众开放。
原生音频能力:对话更自然、情感更丰富
🔊 新功能亮点
Native Audio Output:
- 支持自然语音生成,可控制语调、情绪、说话风格;
- 适配 24+ 种语言,支持多语种无缝切换;
Text-to-Speech(TTS)升级:
- 可生成双角色对话语音,表现轻声细语、情绪起伏;
Live API 扩展:
- Affective Dialogue:识别用户语气情绪并匹配反馈;
- Proactive Audio:自动屏蔽背景杂音,智能判断是否回应。
Project Mariner:让 Gemini 控制你的电脑
🖱️ 关键能力
- 引入“模拟人类操作电脑”的能力:点击、填写表单、网页交互;
已与以下企业展开合作测试:
- Automation Anywhere、UiPath、Browserbase 等;
- 将于夏季向开发者开放更多 API 测试权限。
安全性大升级
🛡️ 防御新型攻击
- Gemini 2.5 显著加强对“间接提示注入攻击(Indirect Prompt Injection)”的防护;
- 通过新的检验机制提升系统在工具使用场景中的鲁棒性;
- 目前为 Google 最安全的模型版本。
Google还在 Gemini API 中添加了对模型上下文协议 (MCP) 定义的原生 SDK 支持,以便更轻松地与开源工具集成。