在 Google I/O 2025 上Google DeepMind首次公开了其正在开发的前沿技术 —— Gemini Diffusion,这是一种将扩散模型应用于语言建模的全新方法。
什么是 Gemini Diffusion?
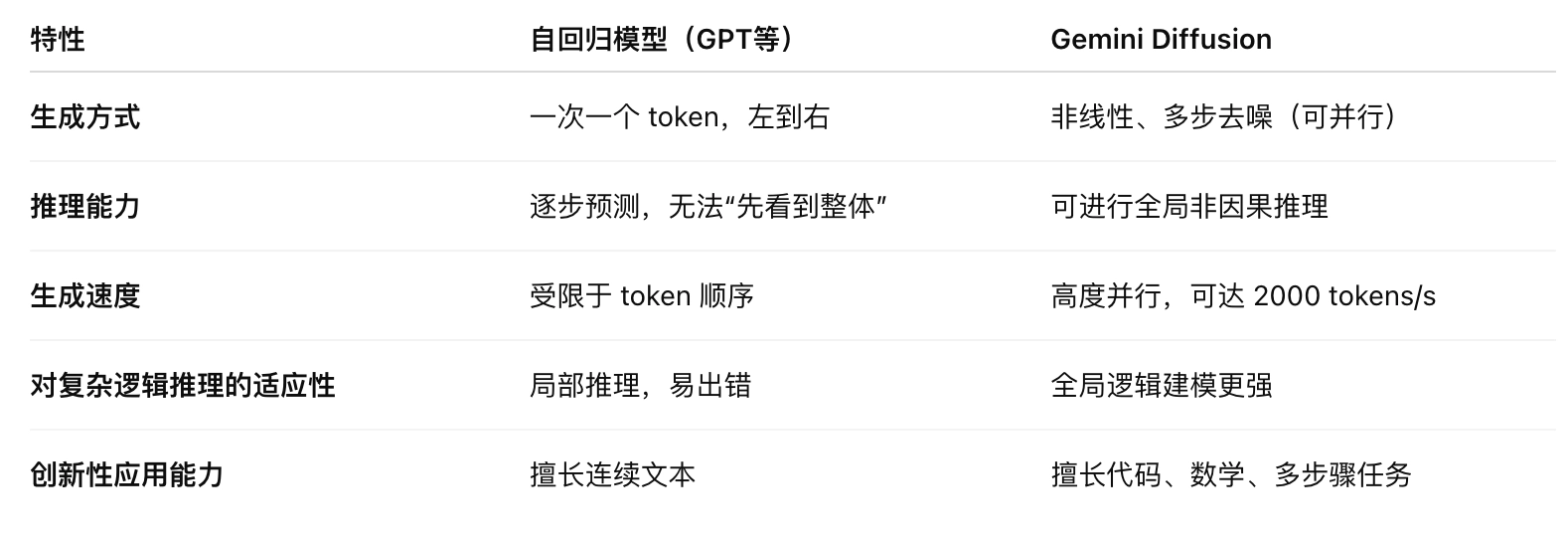
- 传统语言模型(如 GPT)采用自回归(autoregressive)机制,一次生成一个 token。
- Gemini Diffusion 则借鉴图像生成领域的“扩散模型”机制——通过逐步去噪的方式生成完整输出。
这种非因果(non-causal)推理方式带来了两个重大优势:
- 惊人的生成速度:可达 2000 token/秒,包括 tokenization、预填充、过滤等全部计算流程。
- 更强的全局推理能力:不依赖一步步线性生成,能够在整体范围内思考问题。
模型原理
🆚 与传统自回归模型的区别
自回归模型(如 GPT、PaLM 等):
- 按顺序预测下一个词(token),一个接一个生成。
- 优点:结构简单、广泛应用。
- 缺点:生成速度慢、全局连贯性受限。
Gemini Diffusion 模型(基于扩散机制):
- 核心思想:从随机噪声中逐步“去噪”生成文本,类比于图像扩散模型(如 Stable Diffusion)。
- 每一步不是直接生成词,而是对当前生成的内容进行微调和纠错。
- 能更快实现内容构建,并能在生成过程中进行错误修正(error correction)。
主要优势
工作方式:先将一个“完整的文本表示”加入噪声破坏,然后训练模型逐步“去噪”,恢复为合理文本。
优势:
- 允许整体式生成:可以一开始生成一个大致草稿,然后反复迭代改进;
- 天然支持纠错与编辑:因为本质上每一步都在“调整”内容;
- 适合复杂结构的生成:如数学、编程语言,要求结构和语义严谨。
🧩 自然的纠错机制
- 传统模型生成错误需要外部工具检测与重写。
- 扩散机制本身包含逐步修正过程,使得输出更流畅、准确。
🧮 数学与代码处理能力强
- Gemini Diffusion 在“可验证的结构化内容”上表现优越。
- 例如:数学表达式、程序代码,需满足语法正确性与逻辑一致性,扩散模型更擅长这类“编辑式生成”。

案例演示
1. 编程场景表现卓越
Gemini Diffusion 特别擅长代码生成,Brendan 称之为“vibe coding”体验:几乎是实时写出高质量代码。
实测速度达 2000 tokens/秒,这个速度包括了:
- tokenization
- 预填充(prefill)
- 安全过滤
- 输出合成
👉 对比 GPT-4/Claude 等自回归模型,速度提升非常显著,适合高频互动或低延迟场景(如代码编辑器、聊天机器人等)。
2. 复杂数学问题也能轻松解决
传统语言模型(如 GPT-4o)在面对“先答后解”、“跨步骤逻辑”的数学题时容易失败,因为它们是逐步预测的,每一步都会放大之前的错误。
Gemini Diffusion 采用非因果结构,可以“先构建完整答案的逻辑框架,再填充细节”。
📌 示例问题 1:
题目:「(√(81) * (2/3))² + (15 - 3) / (2²)」请先给出答案再推导过程。
答案:39
✅ Gemini Diffusion 正确完成,GPT-4o 未能解出。
📹
3. 非线性、多步骤推理能力
📌 示例问题 2:
题目:「150 到 250 之间有多少个质数?先输出数量,再列出所有质数。」
答案:18 个质数,列表输出为 [151, 157, ..., 241, 251]
✅ Gemini Diffusion 准确完成,GPT-4o 同样失败。
📹
4. 非自回归结构 = 推理不再被“顺序”限制
扩散机制的非自回归特性让模型可以全局优化答案结构,解决那些需要“先知道结尾再写开头”的任务,打破传统 token-by-token 限制。
应用前景与影响
✅ 应用场景
- 高可靠性语言生成(如金融、法律、医疗文本)
- 编程辅助工具(代码生成、错误修复)
- 数学问题自动解答
- 文本编辑、润色、重写任务
🚀 技术前景
- 有望与图像/语音等多模态扩散模型融合;
- 打破现有大型语言模型范式,形成“后自回归时代”的新一代架构;