聊天机器人(如ChatGPT、Claude等)有个很大的限制——它们能“记住”的内容有限,因为模型的上下文窗口(token限制)是有上限的,常见的比如 8k、32k、甚至 128k tokens。
一旦超过这个长度,前面说过的话就会被截断、丢失,导致:
- 聊天断层,前后逻辑不连贯
- 用户体验下降,机器人反应“健忘”
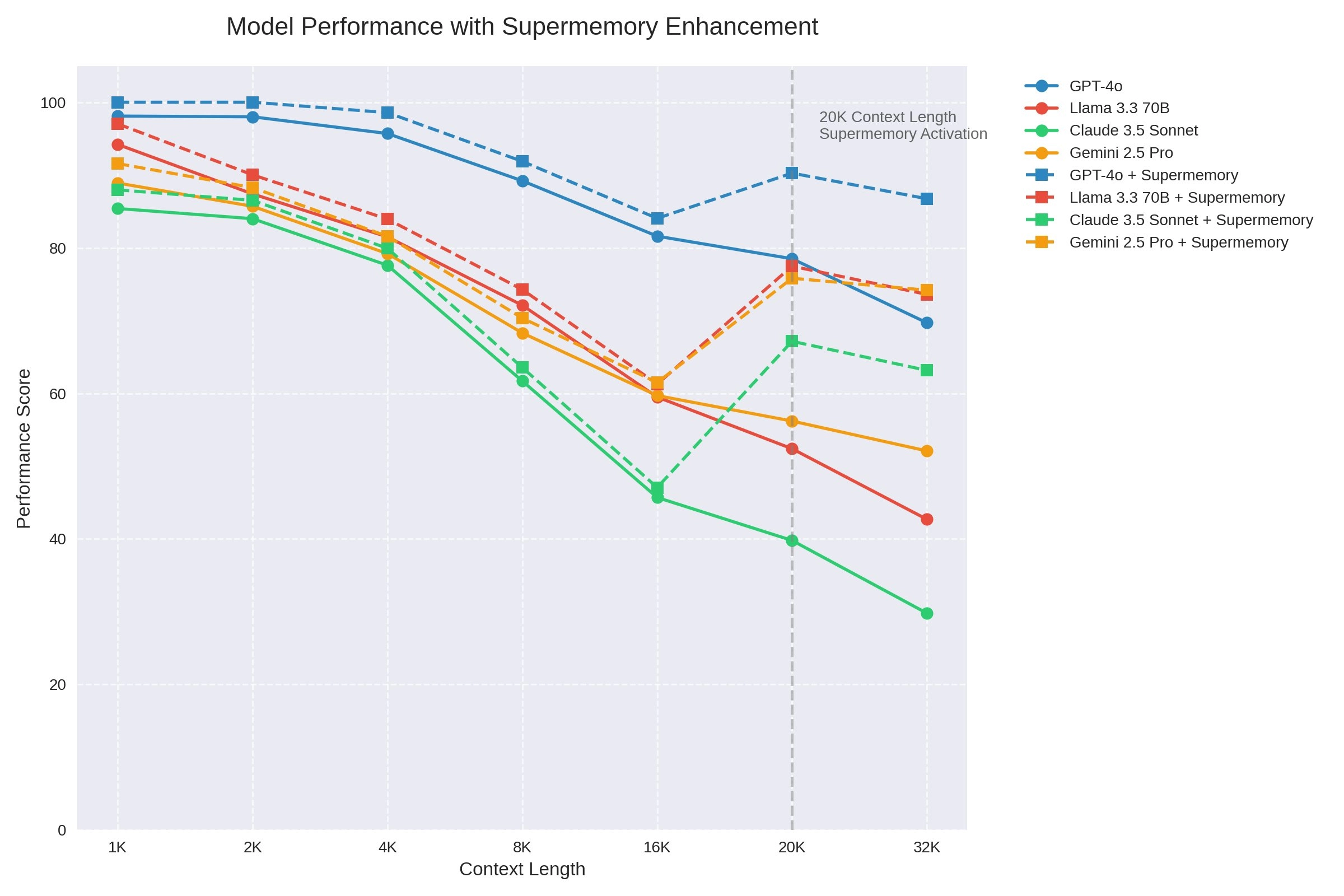
Supermemory 为了解决这个问题, 推出 Infinite Chat API,可扩展任何模型的上下文长度。它可以让你的聊天应用“拥有长期记忆”,而且无需重写任何应用逻辑。
它作为一个智能代理(proxy)透明地集成在现有的LLM(大语言模型) API前端,无需更改应用逻辑即可支持超长对话。
- 声称可 节省 90% token 和成本,同时还能提升模型性能。
- 使用极其简便:只需一行代码切换,立即可用。
- Infinite Chat API 通过在 应用与 LLM 之间作为透明代理,只传输生成良好响应所需的必要上下文,从而避免大模型在上下文过长时性能下降(如20K tokens以上)。
成本结构:
- 免费开始使用
- 每月固定费用 $20
- 每个线程前 20k token 免费,之后 $1/百万 token
它就像是一个“超级记忆外挂”:
- 自动管理和压缩对话内容
- 动态取出有用的旧内容做上下文补充
- 几乎不增加延迟
- 能节省大量Token开销
它的核心是什么?——智能代理 + 记忆系统
Supermemory 以“代理层”的方式嵌入在你现有的 OpenAI API 调用前面,做了三件事:
1. 透明代理(Transparent Proxy)
你原来请求 OpenAI 的接口,现在只要把 URL 换成 Supermemory 的地址,它会中转你的请求给 LLM(大语言模型),对你的业务代码没有入侵式修改。
2. 智能分段与检索(Chunking + Smart Retrieval)
- 它会把长对话“拆成块”,并用自家的算法保持这些块语义连贯
- 当需要继续对话时,它会自动从历史记录中提取最相关的上下文片段,而不是靠你一股脑地发送整个历史
3. Token 自动管理
- 它能根据上下文智能控制 token 使用,防止成本失控
- 同时避免请求失败或内容被截断的情况
实际使用方式
非常简单。以 OpenAI 的接口为例,只要:
- 到 Supermemory Console 获取 API Key
- 把你的请求 URL 换成:
https://api.supermemory.ai/v3/https://api.openai.com/v1 - 在请求头里加入 x-api-key,填你的 Supermemory API Key
支持多种语言客户端,官方文档提供 TypeScript 和 Python 示例。
性能与费用——实用又不贵
✅ 性能优势
- 无限上下文:突破 OpenAI 等模型的 token 限制,可处理任意长度对话
- 节省成本:因为只提取有用信息,可减少最高 70% 的 token 使用
- 几乎零延迟:作为代理转发,请求速度基本不变
- 响应更稳定:上下文提取更精确,回复更贴切
💰 价格模型
- 免费额度:存储 100,000 tokens 无需付费
- 标准计划:$20/月,超出免费额度后启用
- 增量计费:每个对话前 20k token 免费,之后每百万 tokens 收费 $1
出错了怎么办?稳定性保障机制
如果 Supermemory 自身出错(比如检索失败或内部异常),它不会影响你的请求:
- 会自动绕过,直接将请求发给 LLM(如 OpenAI)
- 你还是能得到 LLM 的返回结果,最多是没有优化后的上下文
- 响应中会附带诊断 header,例如是否修改过上下文、处理了多少 tokens 等,便于调试
支持范围和兼容性
Supermemory 支持所有兼容 OpenAI API 的模型和服务,包括但不限于:
- OpenAI 的 GPT-3.5 / GPT-4 / GPT-4o
- Anthropic 的 Claude 3 系列
- 其他提供 OpenAI 接口兼容层的服务商
而且,它本身不限制速率,只会受到你所用 LLM 服务的限制。
总结一句话:
Supermemory Infinite Chat 是一个高兼容、无侵入的“对话记忆增强器”,让你的聊天应用突破上下文限制,更省钱、更智能、可持续。