ChatDLM:第一个扩散语言模型 (DLM),是深度融合 Block Diffusion 和 Mixture-of-Experts (MoE) 架构的大模型,实现了全球最快的推理速度,即将开源。
它采用并行块级扩散、动态专家路由、超大上下文窗口,能在 NVIDIA A100 GPU 上达到2800 tokens/s推理速度,支持131,072 tokens的超长上下文。
该模型有中国公司Qafind Labs 开发。
- 参数大小: 7B
- 极快速度:每秒能处理2800个token,远超其他AI模型。
- 超大记忆:一次能“记住”13万词(131,000 tokens),可以处理长文档、小说、代码等超长内容。
- 聪明分工:模型会把输入分成许多小块,同时用不同“专家”模块处理,再智能整合,既快又准。
主要基准测试成绩:
- HumanEval (0-shot):92.0
- Fill-in-the-Middle:84.2
- ARC-E (0-shot):83.9 > 在代码理解、插入、复杂推理等任务上表现出色。
2800 tokens/s有多快?
- “token”可以理解为“单词碎片”,通常一个英文单词1-2个token,中文一字一个token。
- 2800 tokens/s 指的是,AI每秒能处理、生成2800个token(比如2800个汉字,或者2000多英文单词)。
眨眼速度
- 人眨一次眼大约0.3秒
- 2800 tokens/s = 0.3秒内处理840个token
- 等于:你刚眨一次眼,AI已经“写完”了大半篇短文。
人类说话速度
- 普通人说话大约每分钟120-200单词 ≈ 2-3单词/秒 ≈ 3-6 tokens/秒
- 它是人的500-900倍!
- 你还在说“Hello, my name is...”,AI已经能完成一页英文文档。
一本20万字的小说
- 20万字 ≈ 200,000 tokens
- 它只需70秒就能“读”完一整本。
多说无益,我们上视频对比下看看↓
主要功能有哪些?
- 回答速度非常快,能让聊天更自然流畅。
- 可以让用户“指定”输出的风格、长度、语气等细节。
- 可以只修改一段话里的某个部分,而不用重新生成全部内容。
- 能同时应对多个要求,比如要它生成一个有多项要求的答案。
- 翻译能力很强,可以在多种语言之间准确转换。
- 用的算力资源少,使用成本低。
核心技术解构与创新点
什么是“扩散模型”?
- 原理:先随便“生成”一堆带点噪声(有点像画一幅模糊草图),再慢慢地修正,逐步“抹掉”错误,最后变成一段高质量的文本。
- 类比:就像画画时,先画一个大致轮廓,然后慢慢修改,细节越来越清楚。
和老的AI模型(如GPT)有什么不一样?
- GPT 类似“一笔写到底”,每次都从头生成后面内容;
- ChatDLM 的“扩散”方式可以同时多处优化,更快,而且可以只修正一部分。
技术亮点再通俗点说
- 能快,是因为“并行”——像多个人一起画画,速度更快。
- 能省钱,是因为用得更少的算力,效率更高。
- 能随意改,是因为它不需要全部推倒重来。
1. Block Diffusion(分块扩散)机制
- 基本原理:传统语言模型通常一次性处理整段文本,而 ChatDLM 会把输入文本拆分成许多“块”(如每块512个token),每块独立且并行进行扩散生成。每一轮,模型对每个块进行去噪和优化,通过“跨块注意力”机制,让各块能够互通全局信息,确保输出的一致性和上下文连贯。
- 优势:这种分块和并行处理方法,使模型处理长文本时,运算复杂度显著降低,推理速度大幅提升,同时具备很好的全局一致性。
2. 块级并行(Block Parallelism)与上下文管理
- 高效并行:所有块的反向生成过程可以同时进行,显著提升吞吐量。块之间通过“摘要token”实现上下文的全局共享,复杂度从传统的 O(n²) 降低到 O(n√n)。
- 超大上下文支持:通过精心设计的位置编码(RoPE)和分层缓存策略,ChatDLM 能稳定地支持长达13万token的输入。这对于文档级生成、超长对话、跨章节内容分析等场景尤其有意义。
3. Mixture-of-Experts(专家混合)架构
- 动态专家路由:每一层含有32到64个不同的“专家”子网络,输入数据会动态选择最适合的2个专家进行处理。
- 并行执行:专家选择与扩散过程同时执行,表达力更强,推理效率几乎无损。
- 实际效果:这种机制能让模型更灵活应对多样化、复杂的文本需求,提升理解和生成的深度。
4. GPU 推理和效率优化
- 动态迭代分组:对每个块按难易程度分组,容易的块可以提前结束,节省计算资源,整体平均推理步骤约为12步。
- 混合精度:全部矩阵和注意力操作采用BF16,确保计算精度的同时降低内存占用。
- 分布式并行和切分:支持多GPU分布式推理与训练,方便模型大规模应用和部署。
性能如何
代码相关能力
- ChatDLM在HumanEval(92.0)、MBPP(76.2)、EvalPlus(82.4)等多个代码测试上都为或接近最高分
- Qwen2.5 7B、GPT-4o Mini在部分代码测试略有接近,但整体仍低于ChatDLM
综合推理与常识评测
- MMLU: ChatDLM 69.5(与Qwen、LLaDA、LLAMA3持平或略高)
- BBH: 57.6(仅次于Qwen2.5 7B的63.9)
- ARC-E: 83.9(全表最高,遥遥领先)
- ARC-C: 59.8(也为最高)
- 其它如Hellawag、WinoGrande、PIQA、RACE,ChatDLM表现均处于第一梯队
数学与推理
- GSM8K(小学数学): ChatDLM 77.2(高于大部分模型)
- MATH(高等数学): 39.6(仅次于Qwen2.5 7B的41.1)
- GPQA(科学推理): 36.6(略高于LLaDA 8B和Qwen2.5 7B)
- Countdown/Sudoku/Trip Planning等任务: 绝对分数都不高,但ChatDLM在Sudoku表现突出(81.0)
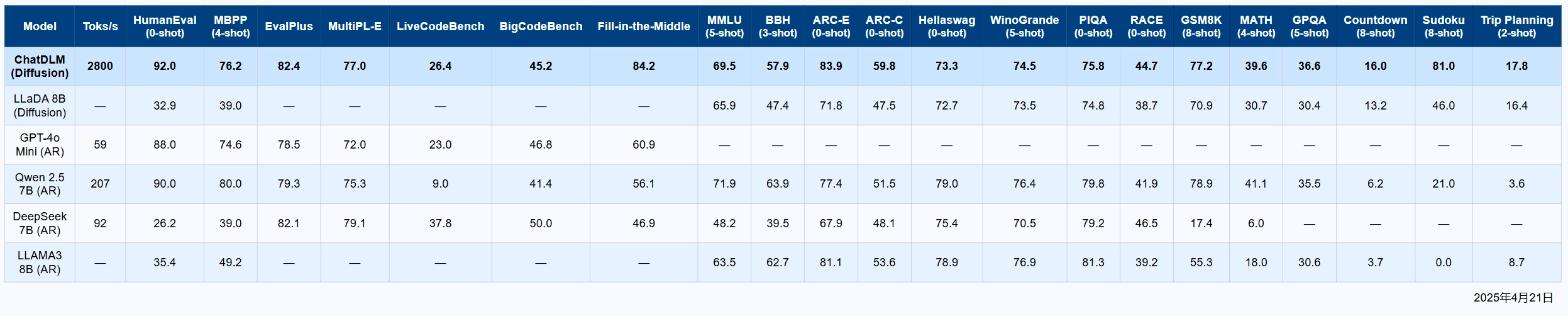
- 速度优势巨大
ChatDLM的生成速度比其它所有对比模型快1-2个数量级,在实际大规模部署、实时交互、长文档生成等场景极具价值。 - 综合能力领先
在代码生成、文本理解、推理、常识、部分数学任务等权威基准上,ChatDLM均为全表第一或处于领先梯队,特别是在HumanEval、Fill-in-the-Middle、ARC-E等方面优势明显。 - 极强的泛用性
表格横向对比显示,ChatDLM在大多数领域(代码、推理、常识、数学等)没有明显短板,是少有的“全能型”模型。 - 与自回归主流模型对比
ChatDLM采用分块扩散推理,不仅速度更快,且能在多个任务上超越自回归方式的开源主流模型(如Qwen、LLAMA3、DeepSeek等)。
ChatDLM 未来要做什么?
- 多模态能力:不只会处理文字,未来还会处理图片、甚至声音。
- 更细致的内容控制:让用户想要什么样的输出,都能“精确调教”AI给你。