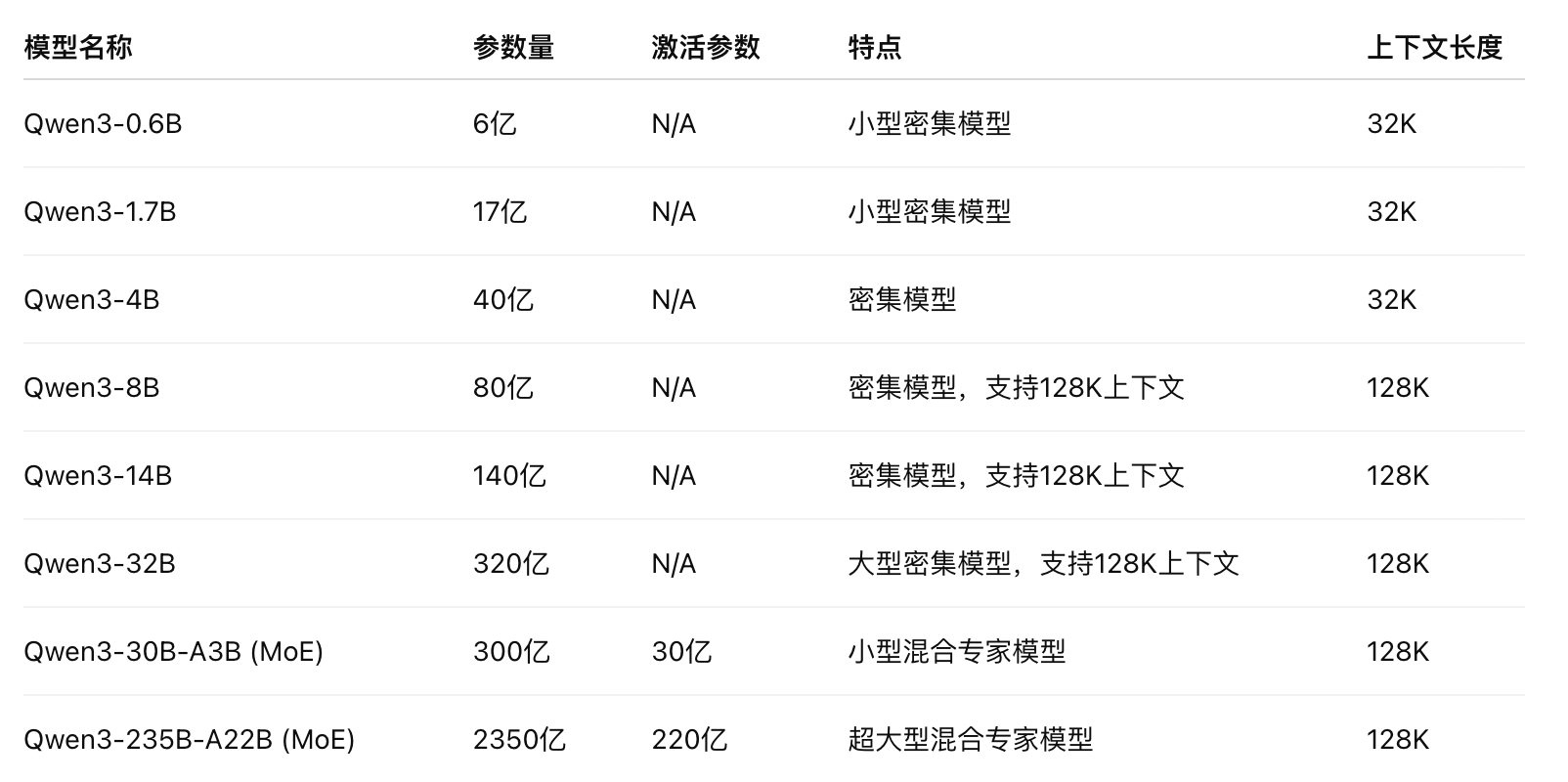
阿里云发布 是 Qwen 系列最新开源模型Qwen3
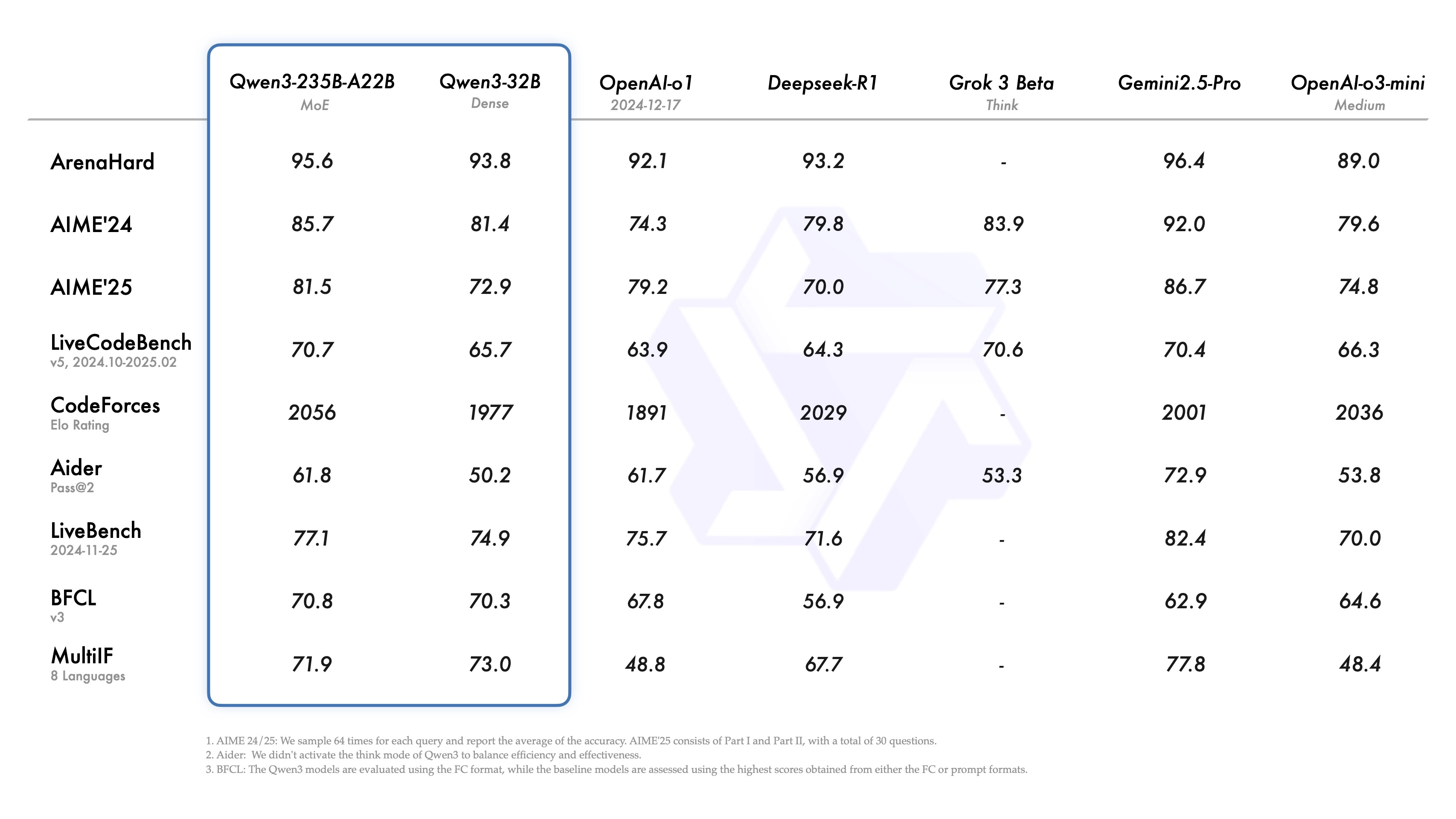
- 主推模型 Qwen3-235B-A22B(2350亿参数,总参数;220亿激活参数)在多个标准评测(编码、数学、综合能力)中,与 DeepSeek-R1、OpenAI o1、Grok-3、Gemini-2.5-Pro 等顶级模型竞争。
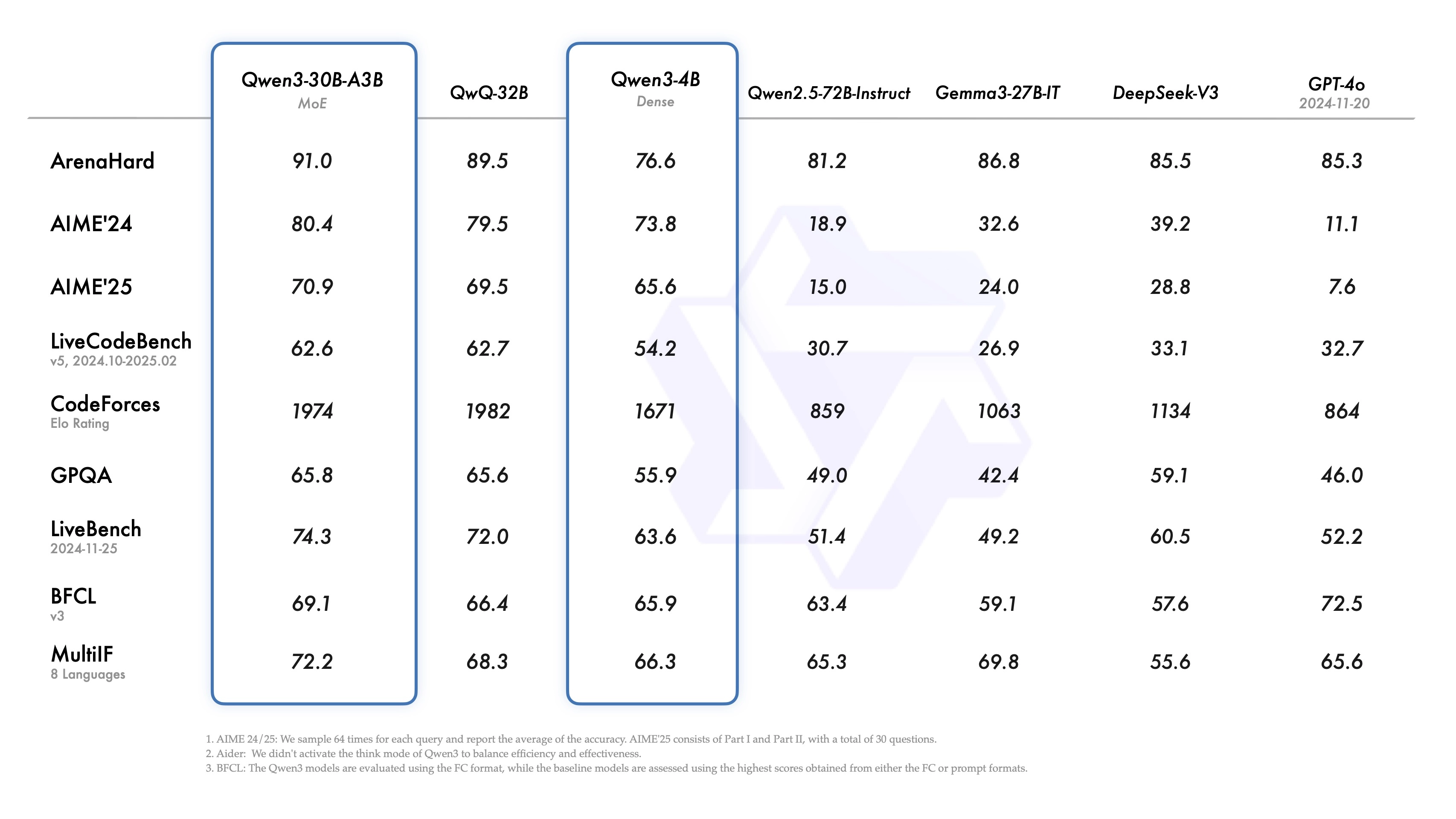
- 小型MoE模型 Qwen3-30B-A3B(300亿总参数,30亿激活参数)性能优于激活参数量10倍的 QwQ-32B。
- Qwen3-4B 体积虽小,性能却可媲美上一代的 Qwen2.5-72B-Instruct。
核心特点
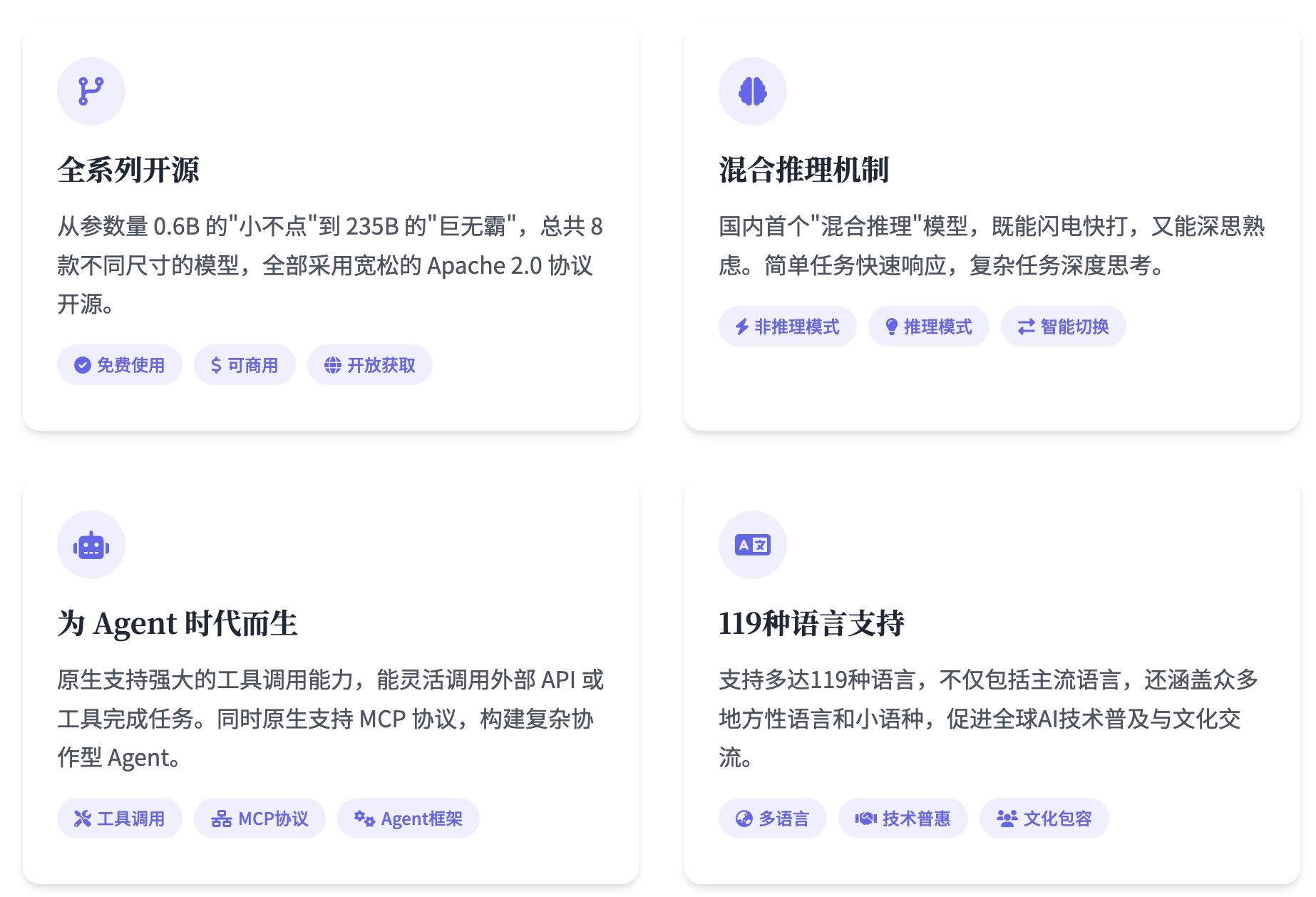
混合推理模式(Hybrid Thinking Modes)
思考模式(Thinking Mode):
- 步步推理,适合处理复杂问题。
- 分配更多计算资源,实现深度思考。
非思考模式(Non-Thinking Mode):
- 快速应答,适合简单直接的问题。
- 应用举例:难题时启用思考模式,简单问答时切换到快速模式。
支持通过 enable_thinking=True/False 参数动态控制,甚至可以在对话中使用 /think 和 /no_think 标签实时切换!
这种灵活性使用户能够根据当前任务控制模型的“思考”量。
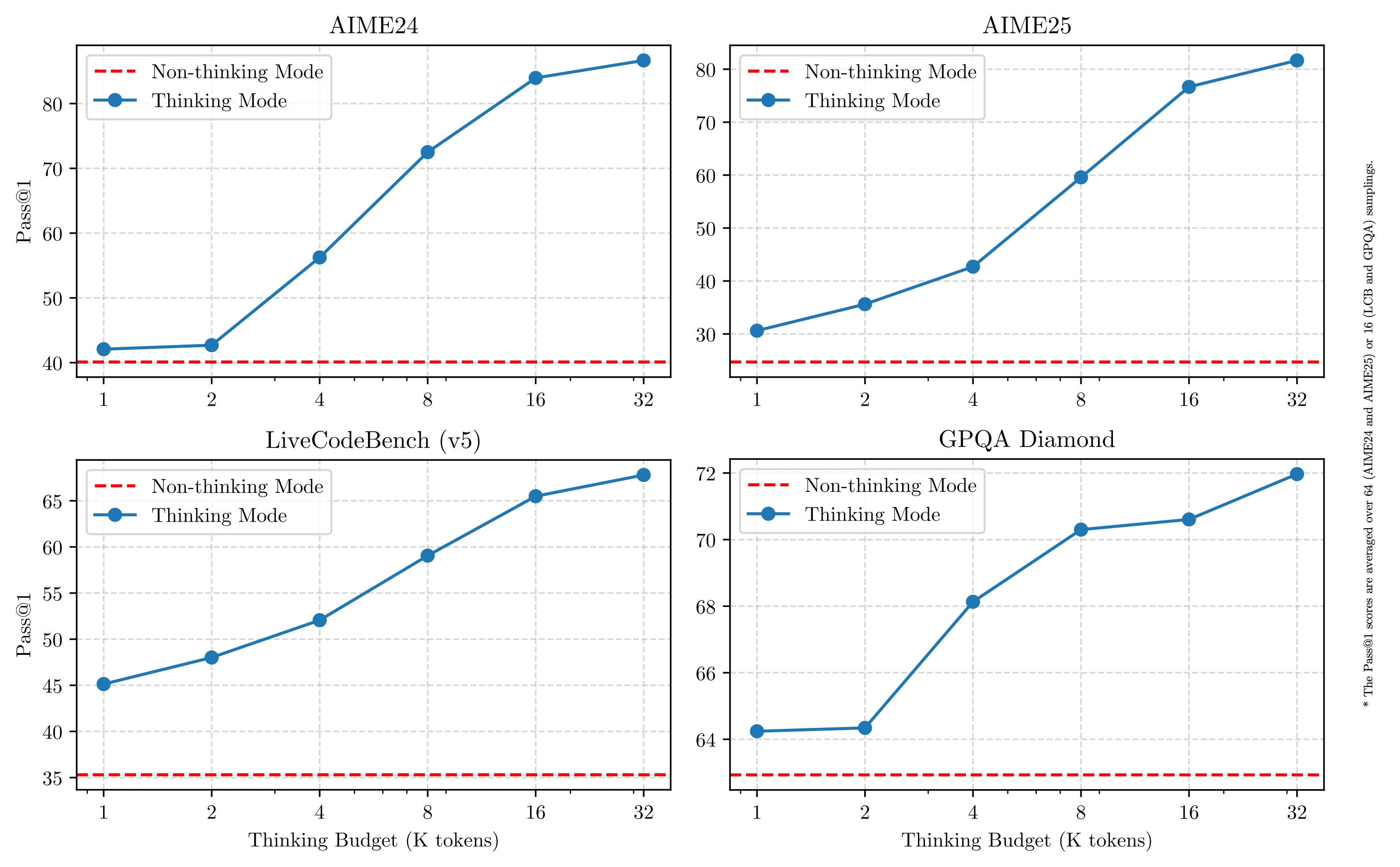
例如,较难的问题可以通过扩展推理来解决,而较简单的问题则可以立即得到解答。至关重要的是,这两种模式的结合极大地增强了模型实现稳定高效的思考预算控制的能力。
如上所示,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这种设计使用户能够更轻松地配置特定任务的预算,从而在成本效率和推理质量之间实现更优化的平衡。
多语言能力(Multilingual Support)
- 支持 119种语言与方言,覆盖世界大部分主流语言家族。
例如:
- 印欧语系(英语、法语、西班牙语、俄语)
- 汉藏语系(简体中文、繁体中文、粤语)
- 阿非罗-亚细亚语系(阿拉伯语、希伯来语)
- 南岛语系(印尼语、马来语、菲律宾语等)
- 还有日语、韩语、越南语、斯瓦希里语等小语种。
Agent能力提升(Agentic Capabilities)
- 深度优化了 代码生成 和 推理决策 能力。
与 Qwen-Agent 框架无缝结合,支持:
- 自定义工具调用(MCP配置)
- 内置常用工具(如时间查询、网页抓取)
- 流式多轮对话交互。
性能对比
训练细节
预训练(Pre-training)
数据量大幅提升:
- Qwen2.5使用18万亿tokens,Qwen3提升至36万亿tokens。
数据来源丰富:
- 包括网页、PDF文档(用Qwen2.5-VL抽取)、数学教材、代码样本。
阶段性训练:
- 基础语言能力训练(超30万亿tokens,4K上下文)。
- 知识密集型数据加强(如STEM、编程、推理,新增5万亿tokens)。
- 高质量长文本扩展,支持32K上下文。
性能提升:
- Qwen3-4B与Qwen2.5-14B性能相当。
- MoE模型使用仅10%激活参数达到密集模型水平,大幅节省推理成本。
后训练(Post-training)
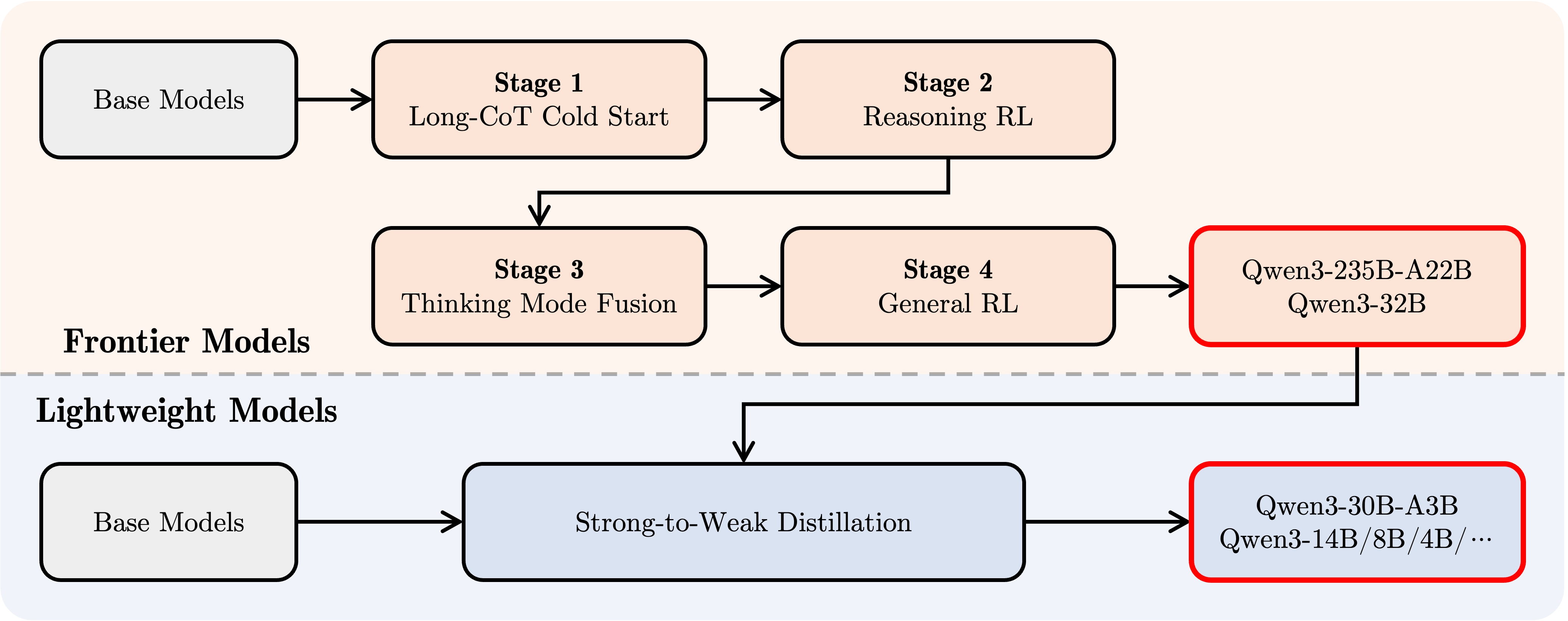
四大阶段打造思考与非思考混合能力:
- 长链推理(Long CoT)冷启动:大量长链推理数据微调。
- 推理强化学习(Reasoning RL):基于规则奖励优化推理能力。
- 融合非思考能力:思考型模型与常规指令模型融合训练。
- 通用领域强化学习(General RL):跨20+任务(如指令跟随、格式遵循、智能体交互)进一步优化。
快速体验
直接用官方通义 App或网页版 chat.qwen.ai
想在自己电脑上跑?
优先考虑 Qwen3-30B-A3B!如果你的显卡给力(比如有 24G 或更高显存),Qwen3-32B也是不错的选择。当然,更小的模型如 8B、14B 也可以根据你的硬件和需求选择。