声明:本文来自于微信公众号数字生命卡兹克,授权Soraor转载发布。
晚上1点,OpenAI的直播如约而至。
其实在预告的时候,几乎已经等于明示了。
没有废话,今天发布的就是o3和o4-mini。
但是奥特曼这个老骗子,之前明明说o3不打算单独发布要融到GPT-5里面一起发,结果今天又发了。。。
ChatGPT Plus、Pro和Team用户从今天开始将在模型选择器中看到o3、o4-mini和o4-mini-high,取代o1、o3-mini和o3-mini-high。
我的已经变了,但是我最想要的o3pro,还要几周才能提供,就很可惜,现在o1pro被折叠到了更多模型里。
说实话纯粹的模型参数的进步,其实已经没啥可说的了,这次最让我觉得最大的进步点,是两个:
- 满血版的o3终于可以使用工具了。
2.o3和o4-mini是o系列中最新的视觉推理模型,第一次能够在思维链中思考图像了。
照例,我一个一个来说,尽可能给大家一个,非常全面完整的总结。
一.o3和o4-mini性能
其实没有特别多的意思,就跟现在数码圈一样,刷新了XX分数。
但是惯例,还是得放,而且坦白的讲,那个级别的模型已经不是我能触达他们智力上限的了。
首先是模型知识这块,我就一起放了。
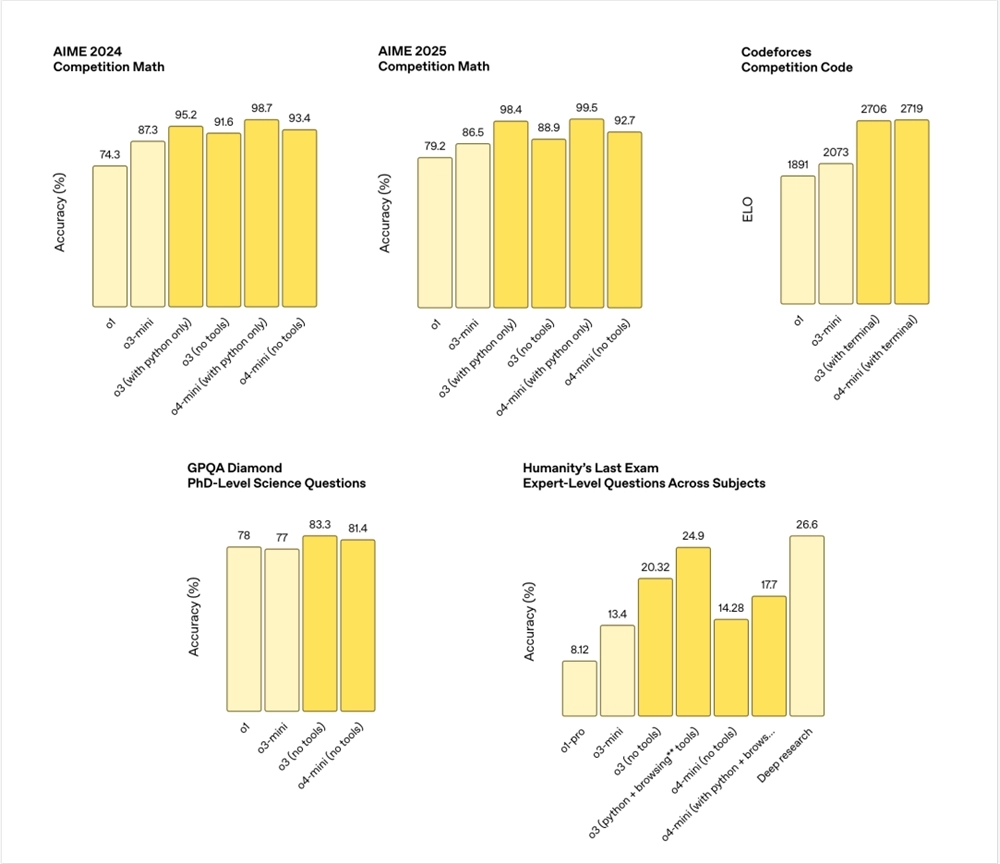
这块大概解释一下,别看底下模型那么多,乱七八糟,各种变体。
但是从最早的o1到如今的o3和o4‑mini,核心差别就在于模型规模、推理能力和插件工具的接入。
最开始的o1只是一个基础的推理大模型,它在2024年AIME数学赛上只有74.3%的准确率,在代码竞赛上的表现也相对平平。
紧接着推出的 o3‑mini,虽然参数量更小,但经过架构优化,在同一场 AIME上就跑出了87.3%的枫树,Codeforces的ELO也从1891提升到2073。
而完整版的o3,其实是比o3‑mini更大的大兄弟,o3其实最明显的变化就是能接入工具了。
比如在AIME2024里,o3跑裸模没接工具时能达到91.6%,一旦允许它调用Python,准确率就飙到95.2%。
同理,o4‑mini相当于小一号的o4,经过更先进的架构优化,在不开工具的情况下就能拿到93.4%,接入Python后则冲到98.7%,已经快干到满分了。
如果把视野放宽到跨学科的PhD级科学题(GPQA Diamond)和专家级综合测试(Humanity’s Last Exam),无需额外工具时,o3在科学题上能以83.3%稍微领先于o4‑mini的81.4%。
而面对专家综合考题,不带插件的o3准确率约为20.3%,添上Python、网络浏览甚至调用多种工具后能推到24.9%。
相比之下,o4‑mini从14.3%起步,借助插件也只能涨到17.7%,仍不及 o3。
最有趣的是,DeepResearch在这个专家综合测试上,力压群雄,但是也能理解,毕竟人本身就是一个基于o3微调的专门干这活的模型。。。
多模态能力这块。
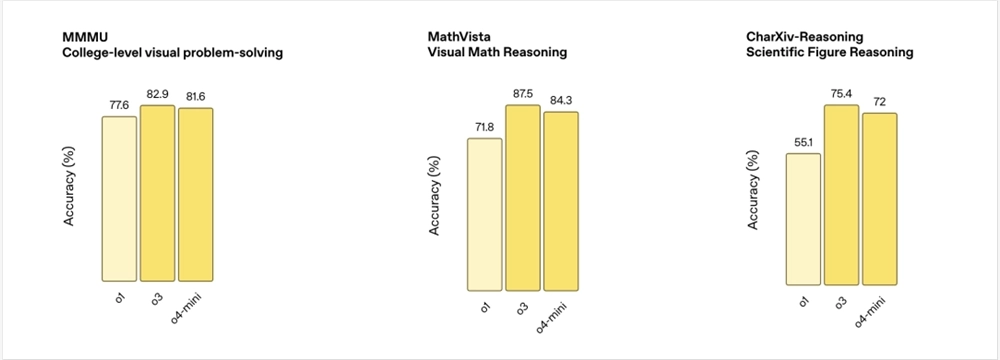
三个数据集。
MMMU:大学水平的视觉数学题库,题目里既有公式也有图形,考察模型把图像和数学符号结合起来解题的能力。
MathVista:专注视觉数学推理,题目多来源于几何图形、函数曲线、矩阵变换等图像,让模型从画面里看出数学规律。
CharXiv‑Reasoning:从科学论文(ArXiv)里抽取图表、流程图和示意图,要求模型根据科研图形回答问题,考验它的专业图表理解能力。
o1在大学级别的MMMU数据集上只能拿到77.6%,面对直观的MathVista 只有71.8%,CharXiv-Reasoning更是跪在55.1%的及格边缘。
o3一上来就把MMMU拉到82.9%,MathVista直接冲到87.5%,CharXiv-Reasoning也飙到75.4%。
这次是正二八经地把视觉推理任务推到了一个新高度。
代码能力这块。
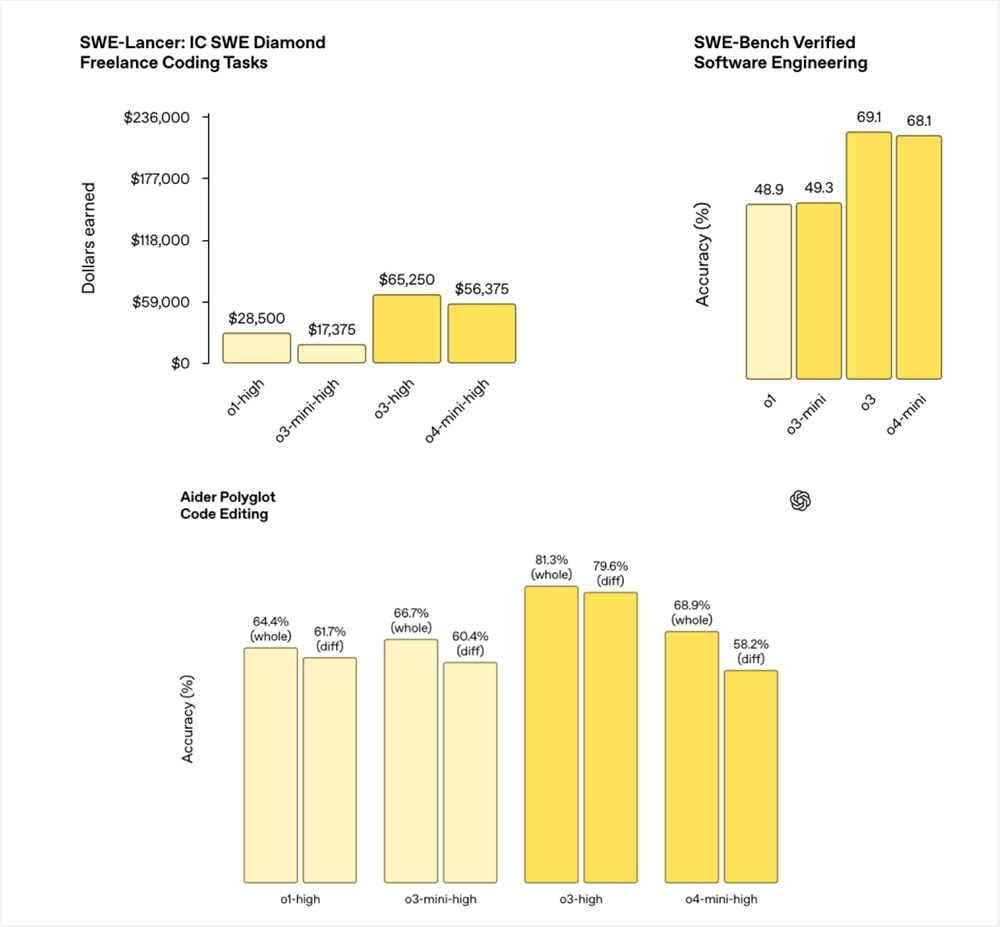
SWE‑Lancer: IC SWE Diamond上真实的自由职业软件工程任务,模型以“高奖励”模式接单,看看最后能拿到的收益是多少钱。
所有模型都直接上了high模式。o3直接挣起飞了。
SWE‑Bench Verified:一个经人工标注验证的软件工程题库,包括常见算法、系统设计、API 调用等,o3和o4-mini同样遥遥领先。
Aider Polyglot Code Editing:多语言代码编辑基准,分“whole”(整体重写)和“diff”(补丁式修改)两类。
o3还是强的,o4mini反而比o3mini还差了点。
工具使用这块。
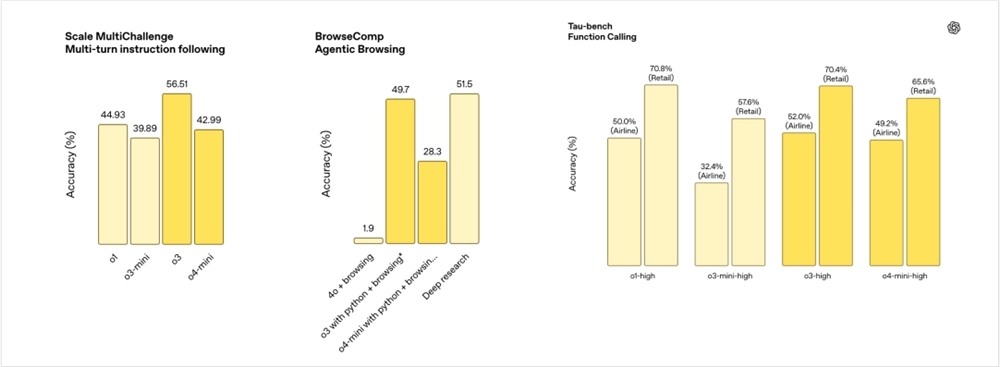
左边那个Scale MultiChallenge,多轮指令跟随,是一套用来测记性+执行力的题。
评测流程一般是:系统给模型一段设定,随后用户分好几轮追加、修改、插入条件,最后再要求一次性产出答案,模型既要把之前的上下文全部保住,又得正确理解最新指令,才能拿高分。o3突出一些。
中间那个BrowseComp Agentic Browsing,就是浏览器里干活的能力。题目会给模型接入一个虚拟浏览器,要求它自己去搜索、点击、翻页、在网页里抓信息,再整合成回答。
常规的AI搜索就是4o+联网的能力,低的有点可怜,o3加了Python和联网之后,居然快能追上DeepReasearch,这是让我有点没想到的。
最右边那个叫Tau‑bench 函数调用。它把模型放进有外部API可调用的场景里,看模型能否判断何时该把自然语言请求转成结构化函数调用,并把参数拼得毫无差错。常见两条赛道:
Airline ,比如就是根据乘客需求,生成正确的航班预订JSON。
Retail ,比如就是 根据购物指令,调用商品查询或下单接口。
如果模型选错函数、漏填参数、或者格式写歪,都会直接扣分,所以这项测验主要检验模型的意图解析到结构化输出链路是否稳固。
这块,居然o3相比o1,几乎没有任何提升。
然后我在翻System卡的时候,还发现一个有趣的数据。
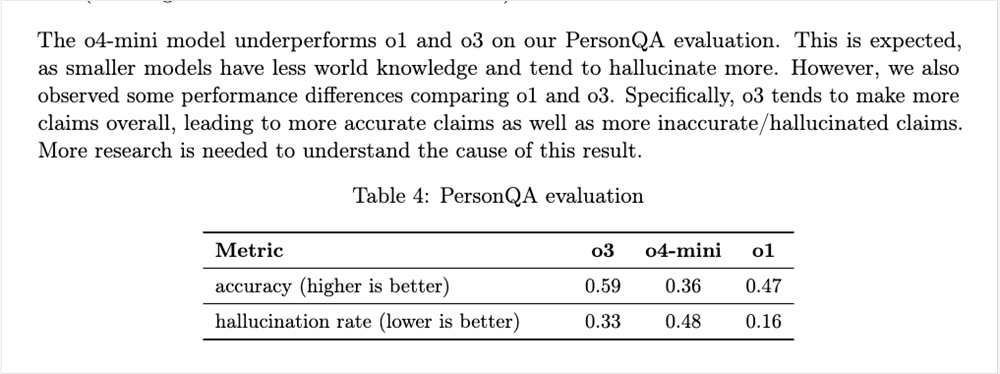
第一个指标是准确率,越高越好,第二个是幻觉率,越低越好。
o3因为在整体上,更敢下定论了,所以不会含糊其辞,也就是更准确了,但是幻觉率也飙升,直接干到了o1的两倍。。。
以上,就是o3和o4-mini的性能参数。
定价上。
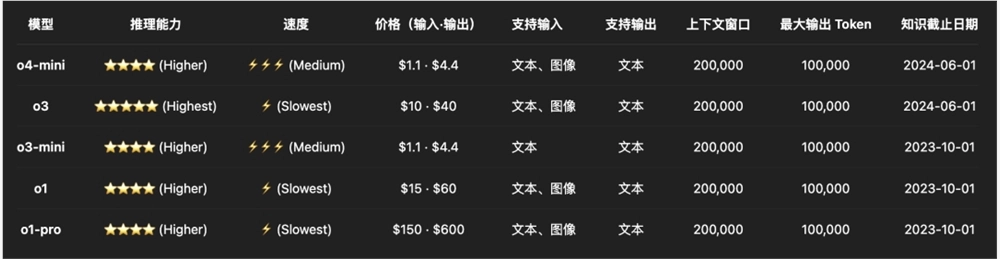
o3比o1的定价便宜了三分之一,o4-mini相比o3-mini没涨价。
OpenAI终于干了回人事。。。
二.使用工具以及视觉推理
o1和o1pro我之前有个巨大的痛点,就是这玩意不能使用工具,联网、代码解释器啥的,一个都不行。
然后只支持识图,连PDF文件,都传不上去,太傻了。
而这一次,o3和o4-mini直接拉满,不仅支持了OpenAI的所有工具,甚至还有了一个超级牛逼的新特性。
视觉推理。
单听这个很难理解,我直接给你们,看两个例子。
第一个,是一个非常经典的游戏,就是看图猜地点,但是不是那种没啥难度的,城市题,说实话,有建筑,太好猜了。
我们直接进一个专门玩这个的网站,叫图寻,参加每日挑战。
我的第一题,就是这个。

对,就这么个东西,让你猜这是中国的哪,在右下角的地图上打标,离终点越近,分越高。
我直接把这个扔给了o3,我们来看看,他的思考过程。

非常离谱的,自己去看图,把图片放大,一点一点思考,这个地方不对,哎换个地方我再放大看看。
以前模型的思维链,只有文字,而这次,这是大模型第一次,真正的把图片,也融入到了推理中。
我们再回过头来看看,刚才那道猜地题,它给出的答案。

虽然没有那么肯定,但是也给出了答案,北京门头沟、房山,109国道,妙峰山那一段。
我们来揭晓答案。
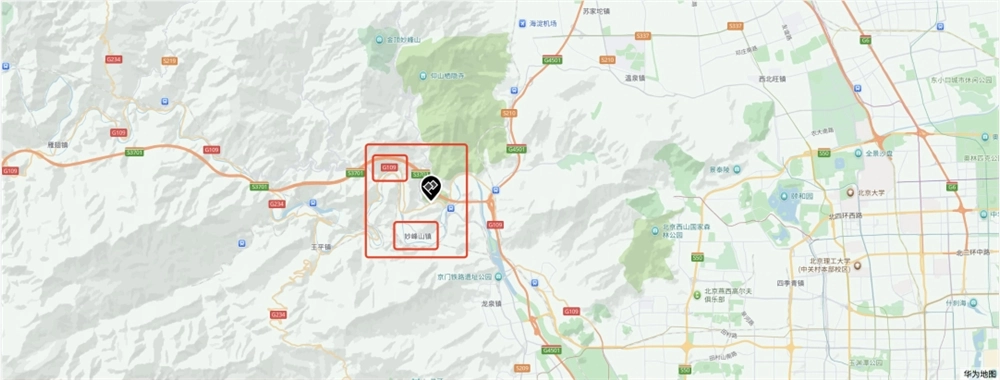
可能有些人对这个地点不熟悉,这个地方,叫北京,门头沟,109国道,妙峰山。
那一刻,我真的有点起鸡皮疙瘩了。
因为你会发现,AI开始像人一样去看图、像人一样去思考了。
以前你说AI懂图,懂什么?懂像素?懂特征?是的,它会提特征、会分类、会打标签,但它并不看图思考。
它是一个图像识别器,但不是一个图像思考者。
而今天,o3,是第一次让模型学会了看图思考,学会了视觉推理。
这个变化,堪称范式级别的跃迁。
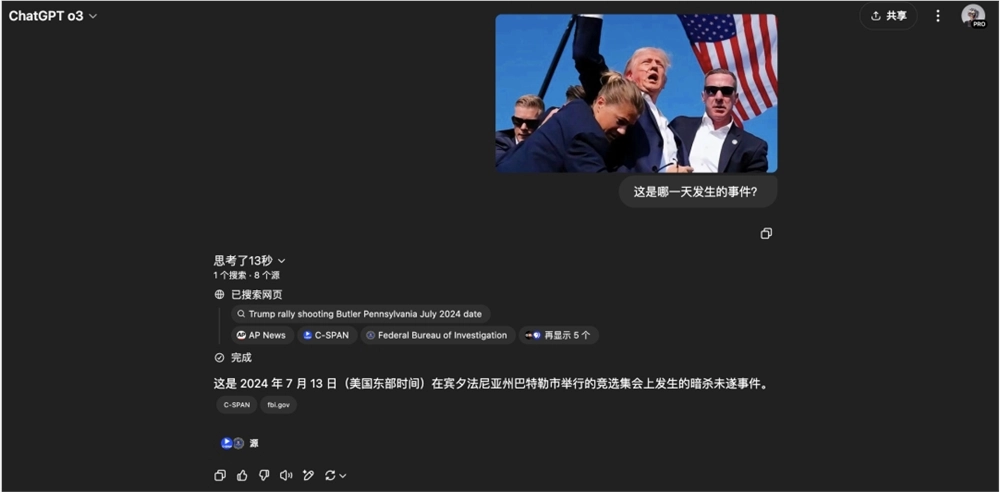
我们甚至可以,把一个事件的图片发给他,让他来寻找,这是哪一天发生的事件。
还有一个很有趣的例子,虽然不算成功,但是我还是想分享给你看。
前天,《流浪地球3》正式开机了,官方也发了一张大合照。
也官宣了沈腾的加入。
然后,我试图,让o3,在里面找到吴京。。。
第一次,失败了。

因为那天太晒,吴京和沈腾都带了帽子,几乎就无法靠脸识别了。
于是,我又去找了一张图。
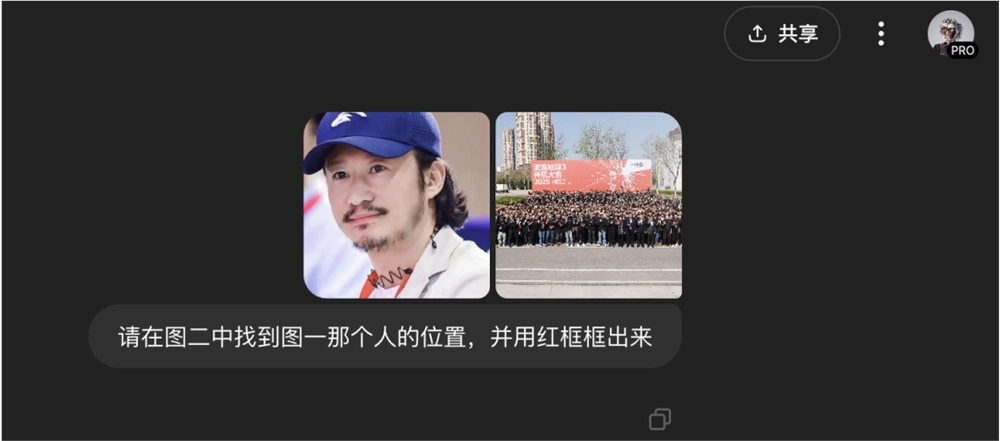
这一次,他成功了,当然,靠的是找帽子。

这个case,可以完整的展现出,o3的能力,包括在中间各种放大查看细节,跟python结合进行分析以及加红框等等。
视觉推理让AI具备了第一种专业场景下的观察力。
而视觉推理这个能力的普及,意味着很多原本需要人眼判断的岗位,会被彻底改写。
安全监控不再是看到异常才报警,而是看到将要发生异常就提前预判。
设计审稿不再是人力盯图,而是AI先过一遍排版,再交给人来最后决策。
医生看片子,也不再只是看片,而是由AI先提出几个可能的诊断路径和可能遗漏点,再辅助手术或治疗。
这就像,当年推理模型对非推理模型的冲击。
而现在,又一次上演。
写在最后
除了o3和o4-mini之外,OpenAI这次,还开源了一个AI编程工具。
开源地址在此:https://github.com/openai/codex
有兴趣的可以去试试。
这一次,看到OpenAI掏出来的模型。
我忽然想起很多年前,人类第一次拍到地球全貌时的震撼。
一颗蓝色的球,悬在黑色的宇宙中。
那张图,改变了很多人的世界观。
而今天,当AI第一次看懂图、思考图、把图当做世界的一部分去推理。
我们或许,也站在了某种第一次的起点。
它会改变什么?
我现在,还不知道。
但是一定会有所改变的。
我坚信。