Recently, the Institute of Automation, Chinese Academy of Sciences, and the CASIA-Zhidong Taichu team jointly introduced a novel method – Vision-R1. Leveraging R1-like reinforcement learning techniques, Vision-R1 significantly enhances visual localization capabilities. This method achieves a 50% performance boost in complex tasks such as object detection and visual localization, even surpassing existing state-of-the-art (SOTA) models with over ten times the parameter scale.
Currently, image-text large models typically rely on a "pre-training + supervised fine-tuning" approach to improve responsiveness to user instructions. However, this method presents significant challenges in resource consumption and training efficiency. Vision-R1 innovatively changes this by combining high-quality instruction-aligned data with reinforcement learning. The method designs a visual task evaluation-driven reward mechanism, providing strong support for the model's target localization ability.
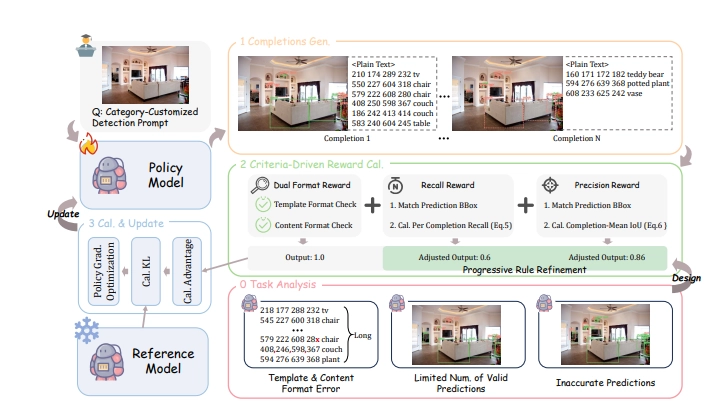
Specifically, the Vision-R1 reward mechanism comprises four core components: First, it employs multi-target prediction to ensure effective quality assessment in dense scenes; second, a dual-format reward is designed to address formatting errors in long-sequence predictions; third, a recall reward encourages the model to identify as many targets as possible; finally, a precision reward ensures higher quality of generated bounding boxes. These designs interact synergistically, creating a "1+1>2" optimization effect, enabling superior performance in complex visual tasks.
To address the challenge of predicting high-quality bounding boxes, the research team also proposes a progressive rule adjustment strategy. By dynamically adjusting the reward calculation rules, the model continuously improves its performance. The training process is divided into beginner and advanced stages, gradually raising the reward standards to achieve a transition from basic to high precision.
In a series of tests, Vision-R1 demonstrated excellent performance on the classic object detection dataset COCO and the diverse-scene ODINW-13 dataset. Regardless of the initial performance, models trained with Vision-R1 showed significant improvements, further approaching the capabilities of professional localization models. This method not only effectively enhances the visual localization capabilities of image-text large models but also provides new directions for future multimodal AI applications.
Project Address:https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1