OmniTalker 是由阿里巴巴 Tongyi Lab 开发的一种端到端、实时、文本驱动的虚拟人头部生成系统,可以从文本直接生成配音同步的人脸视频,且支持实时零样本风格迁移(zero-shot style replication),即从一个参考视频中同时提取视频中人物的说话风格和面部风格,实现语音和面部动作的协调合成。
例如:
- 比如雷军的视频),它就能学会“雷军怎么说话、怎么表情”,然后用这种风格去说你写的文字!
- 不用你训练模型、调参数,也不用配音演员,全自动!
- 还能实时生成视频,不卡顿,适合直播、AI 虚拟人等使用场景。
主要创新点与功能
过去做这种说话视频,需要 好几个步骤拼起来(文本转语音 → 音频驱动嘴型 → 拼接成视频),容易:
- 出错(声音和表情不同步)
- 风格不一致(说得像机器人)
- 慢(处理流程长)
OmniTalker 的创新点在于:
它把这一切都整合到一个大模型里,一次性完成,听起来更自然,嘴型和语气完全匹配,还能“模仿风格”。
✅ 零样本多语言风格复刻
使用不同语言文本 + 一个参考视频,可以生成风格统一、同步自然的音视频内容。例如:
- 输入中文文本 → 输出英文配音+对应面部动画;
- 例如模拟某人讲话风格,生成内容风格一致的视频。
✅ 情绪表达驱动
可以生成表达**不同情绪(高兴、愤怒、悲伤等)**的虚拟人效果,面部表情自然,与语音风格协调。
✅ 长时段生成支持
可生成较长的视频内容,同时保持语气、节奏、动作风格的一致性。
核心技术拆解

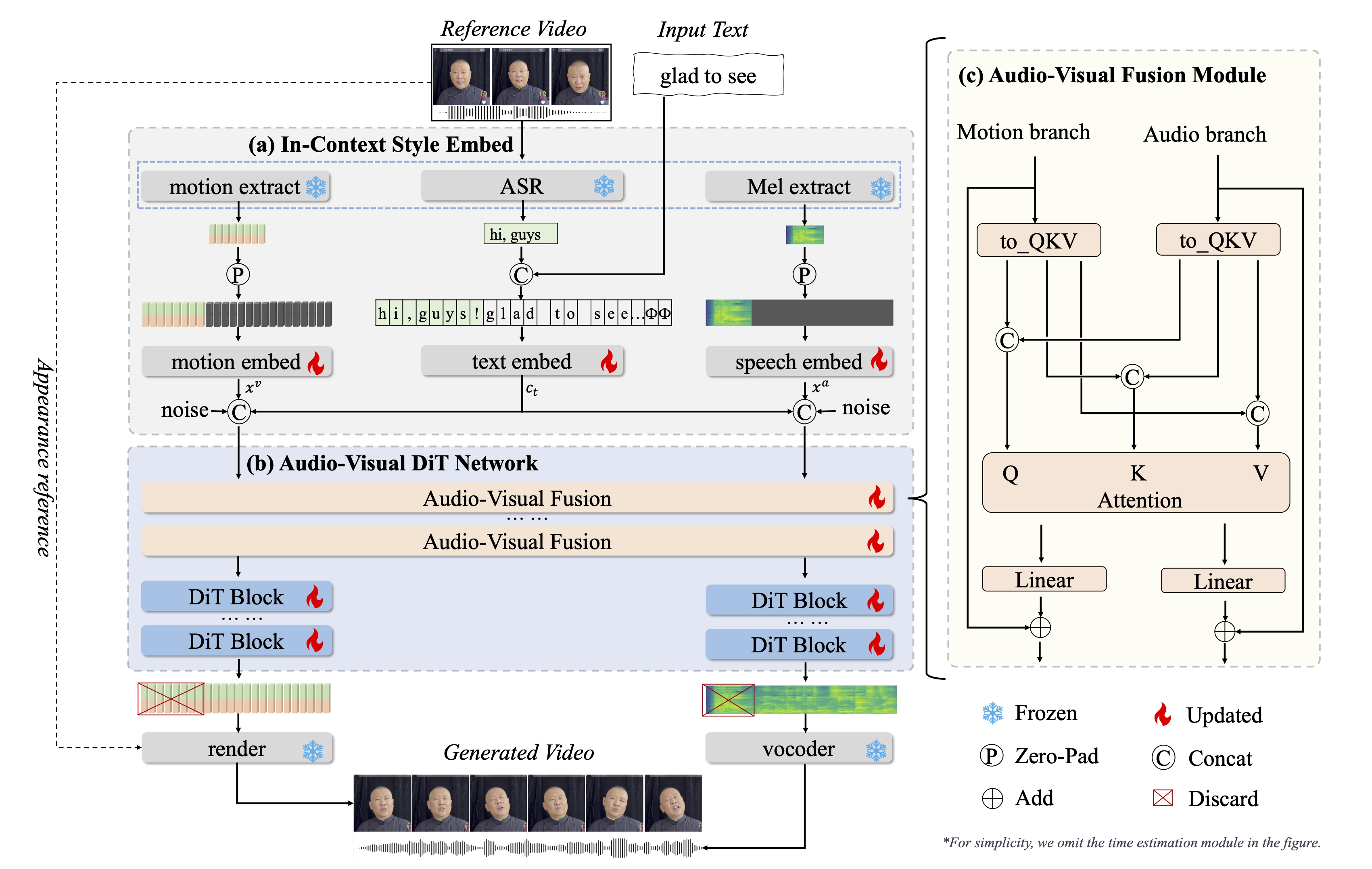
1. 统一音视频生成框架
OmniTalker 不是传统的“文本 → 语音 → 视频”级联模型,而是将文本直接映射到配音 + 视频,消除传统方法中的错误累积、延迟大、音画风格不一致等问题。
2. 双分支扩散-Transformer架构(DiT)
- 音频分支:从文本生成高质量 Mel-spectrogram(声谱图);
- 视觉分支:生成精细的人头姿态与面部动态;
- 音视频融合模块:保证生成的声音与人脸动作同步,风格一致。
3. 上下文学习(In-context learning)
从一个参考视频中一次性提取说话风格和面部表情风格,无需额外训练或风格编码器,实现“零样本”泛化。
4. 实时推理效率
- 模型仅 0.8B 参数规模;
- 推理速度高达 25 帧/秒(FPS);
- 支持实时交互场景,如 AI 视频助手、实时虚拟主播等。
交互性和应用场景

- 可集成到 OpenAvatarChat 等对话系统中,支持实时虚拟形象对话;
- 适用于 AI 数字人、AI 虚拟主播、实时远程视频会议助手、教育培训视频生成等场景;
项目地址及更多演示:https://humanaigc.github.io/omnitalker/