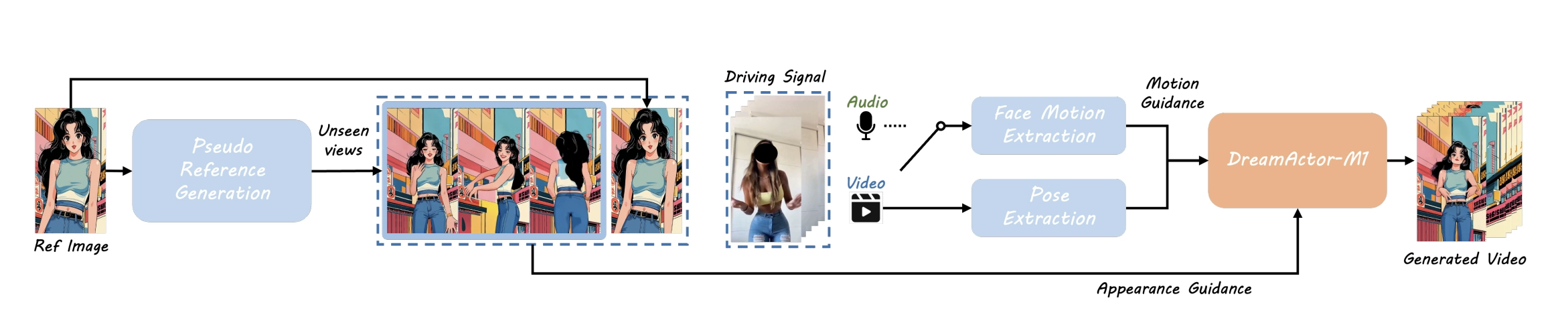
DreamActor-M1:由字节跳动开发的一种基于Diffusion Transformer(DiT)的人像动画生成框架,可以根据参考图片和驱动视频生成高质量、可控、长时一致的人物动画视频。具备全方位控制力、跨尺度适应性和长时序一致性。
它可以:
- 只需一张照片(人脸或全身)和一段视频结合,就能让照片里的人“动起来”,像视频中的人一样跳舞、说话、做动作。
- 做到表情细腻、动作自然、画质高清,而且不会“失真”或者“乱动”。
- 能控制让照片只动头或只动脸,也支持各种身材比例和语言根据语音生成同步口型的动画。
- 即使视频中有你从未见过的姿势,它也能自然衔接,效果非常稳定。
📌 简单理解:DreamActor-M1 是一个“让静态照片动起来”的系统。你给它一张照片和一段参考动作视频,它就能自动把照片上的人“变活”,做出视频中的动作、表情、甚至说话时的嘴型。
它解决了哪些问题?
以前的动画生成技术有三大痛点:
- 表情和动作做得不够细腻;
- 面对不同视角、不同距离的图片(如头像、半身照)适应不好;
- 视频一长,前后人物细节会对不上,穿帮。
✨ DreamActor-M1 的主要功能特点
✅ 1. 细粒度的人体动画控制
- 同时控制面部表情(如微笑、眨眼、嘴唇颤动)和身体动作(如转头、抬手、跳舞等)。
- 脸部、头部和身体的控制彼此独立又协同,实现更自然的动作合成。
✅ 2. 多尺度适应性强
- 无论是头像、半身照、还是全身照都能自适应生成对应范围的动作。
- 训练时使用多种分辨率和比例的数据,确保模型能处理不同尺度的输入图像。
✅ 3. 长时间动画一致性(Temporal Coherence)
- 在长视频合成中保持细节一致,避免“穿帮”现象(如背后的衣服颜色变来变去)。
- 引入“补充参考图像”,使模型在看不到区域也能填充一致内容。
✅ 4. 高保真、身份保持性强
- 合成视频中的人物风格、长相、发型等高度还原参考图像。
- 保证面部特征的独立性,不因驱动视频而改变人物本身外观。
✅ 5. 支持音频驱动的表情同步
- 可将语音信号直接转换为面部动作(如嘴型变化),实现音频驱动的人脸动画(如对口型动画)。
功能特性与扩展能力
✅ 控制能力(Controllability)
- 支持只转移面部表情或头部动作,适用于虚拟人直播、表情操控等场景。
- 支持人物骨骼比例自适应调整(如人物身高不同也能还原动作风格)。
- 支持任意头部方向下生成动作。
✅ 多模态驱动
- 可扩展为 音频驱动动画,自动生成多语言唇动同步视频(如 AI 虚拟主播口型同步)。
✅ 多样性与鲁棒性
- 兼容不同角色风格、不同类型动作,生成效果稳健、连续、自然。
核心创新

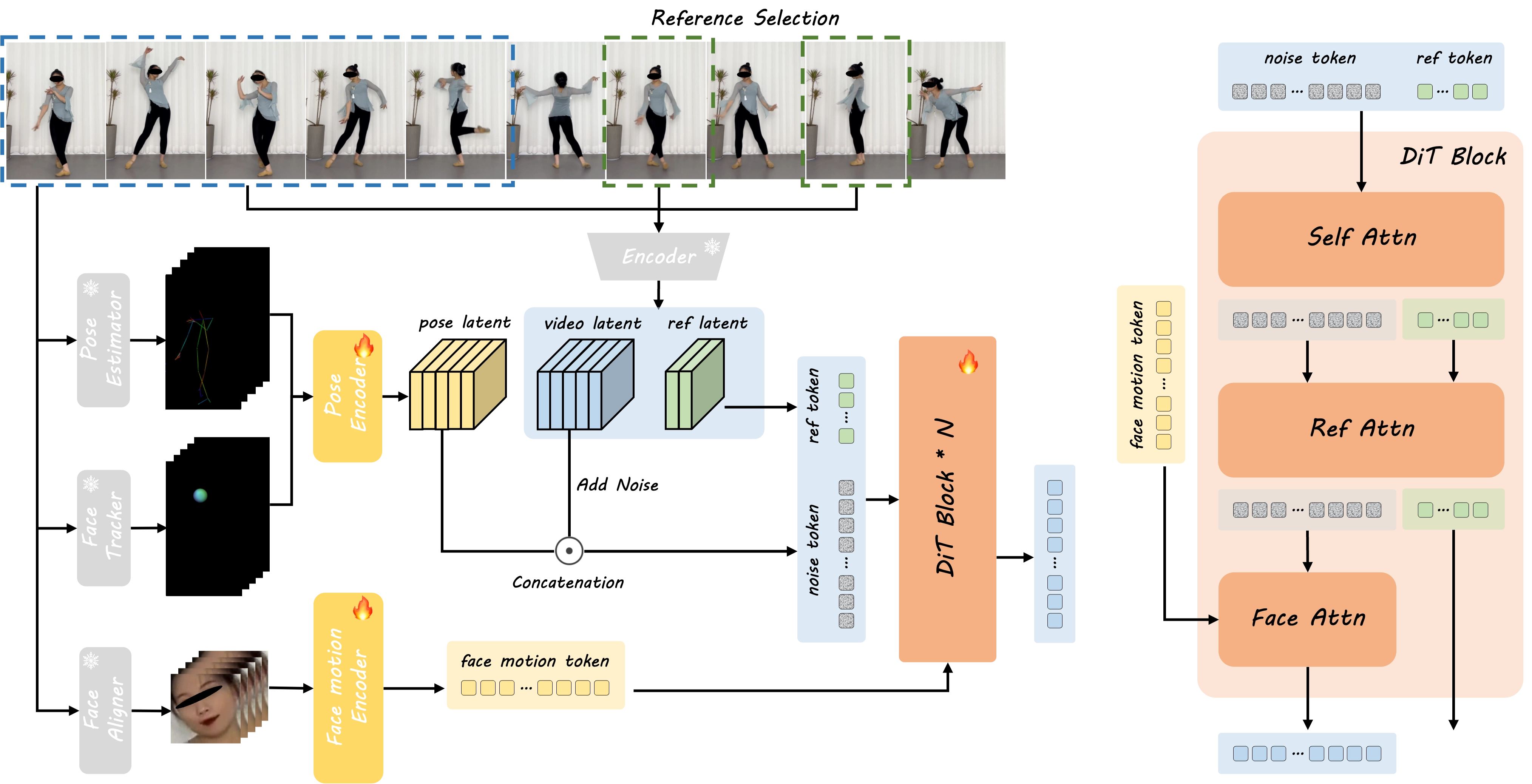
1️⃣ 混合动作控制(Hybrid Motion Guidance)
控制信号来源:
- 3D人体骨架(Body Skeleton)
- 3D头部球体(Head Sphere)
- 隐式面部表征(Implicit Face Features)
这些信息帮助模型精准控制身体姿态和面部表情,保持身份一致性。
2️⃣ 外观引导机制(Appearance Guidance)
- 从一张或多张参考图像中提取视觉细节,提供 身份与风格信息。
- 融入生成过程,提升图像的清晰度、外观一致性,特别是在被遮挡区域。
3️⃣ 动画生成模块(Diffusion Transformer, DiT)
- 输入为:动作控制信息 + 带噪视频潜变量 + 外观信息
DiT 在多轮去噪过程中融合以下三种注意力:
- Face Attention:用于控制面部动作
- Self Attention:保持帧间一致性
- Reference Attention:保持人物外观
实验结果
与多种当前主流 SOTA 方法进行定量和定性对比,DreamActor-M1 在所有指标上表现优异,特别是在面部与身体联动一致性、连续动作的自然程度方面效果显著。