搭建 Voice Agent 就像是把大象装进冰箱,看上去只有三步很简单:
1)选择 LLM/STT/TTS 大模型
2)接入 WebRTC 或 WebSockets 进行实时传输
3)调整参数封装
但在实际使用过程中,却困难重重:
“😫回声太大、噪音太多”、“人声太杂听不清👂”
“人工智能如智障,说话都不能打断🤐”
“延迟太高反应慢🐢”、“又有新模型了又要重新接😞”
“三段式看着简单实现的工程太难💻”
“多模态数据间的实时传输太麻烦了、搞不定啊 🤯”
“CPU消耗怎么这么高?!!😢
于是,对话式 Voice Agent 开源框架——TEN Framework应运而生!
TEN 解决了 Voice Agent 搭建过程中与多模态数据传输复杂、延迟高的问题,并且将LLM、STT、TTS 等模型进行模块化、自由调用,为开发者减少实现时的工程问题,更加聚焦于场景与业务内容,快速完成产品的落地与验证,并能够真正用于实际生产 💪
🤔 那么,TEN 是什么?
TEN 是一个实时对话式 Voice Agent 引擎,可以帮助开发者快速搭建可音视频交互的 AI Agent。
目前已经支持包括Deepseek、OpenAI、Gemini等在内的全球各大主流 STT、LLM、TTS 厂商。
同时 TEN 可以支持接入Dify与Coze,只需配置 bot ID/API,就能让你的 bot 开口说话。

(TEN 已经支持的 extension)
支持语音、文本、图像等数据传输,充分发挥多模态优势
同时支持级联模式(STT-LLM-TTS)与端到端模式(End to End)打造音视频交互
内置 RTC,解决语音交互时的延迟问题,基于TEN Framework 搭建的 Agent,优化最佳情况下延迟仅650ms
自带 VAD,在与 AI 语音交流过程中可以随时打断、还原真实对话
已支持全球主流的 STT、LLM、TTS 等插件,配置 key 即可
及时跟进最新技术,24h 内完成接入 OpenAI Realtime API、Gemini2.0
支持 C++/Go/Python/Node.JS 等各类编程语言(JavaScript 即将支持)
支持Agent 在 Windows/Mac/Linux/移动端等的跨平台使用
AI 外呼中心,如:企业客服/外呼中心/专业咨询......
让客户打电话给你定制的 AI Agent 专家!
Demo 里演示的是心理咨询专家,可以看到 Agent 在听到“我”说心情不好时语气也低沉了下来,语音在这种场景下比文字更合适。
故事机/智能音箱/AI 玩具/智能家居......
目前已支持 ESP32,你可以直接与 ESP32进行低延迟、可打断的对话,让他给你讲个故事。
TEN目前支持 Trulience avatars 虚拟形象,让你的 AI 导购/虚拟宠物/AI 游戏陪玩......
你可以让小狗与你切换方言、进行语音交流;
也可以和 AI 一起下棋,动嘴就能操控,解放双手。
自然语言交互界面(LUI)会越来越进入我们的生活。
用语音开启浏览器、电脑 App、记 memo......你也可以用 TEN 打造自己的“贾维斯”。
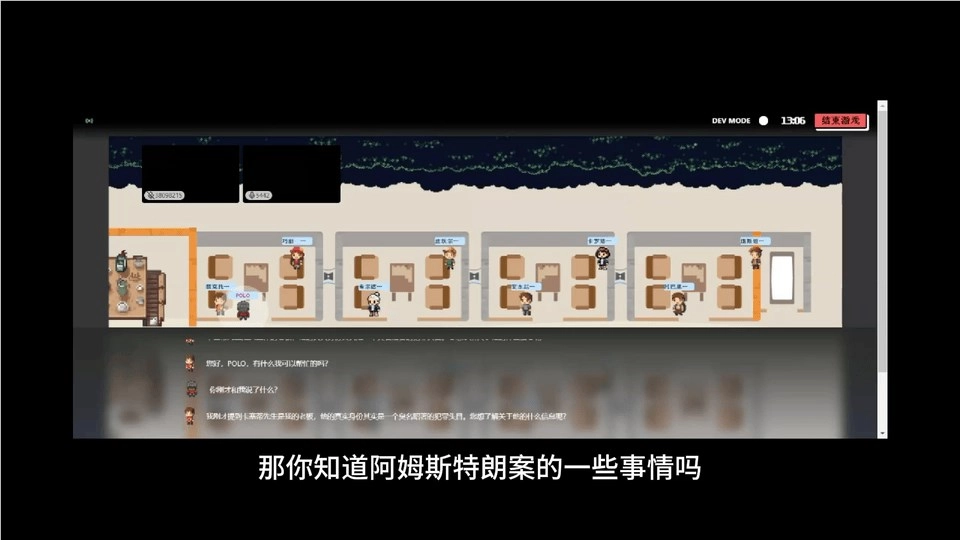
语音剧本杀之东方快车谋杀案。
跟 NPC 聊聊案件发生时 TA 们都在做什么,沉浸式体验,一个人也可以玩剧本杀。
在使用 Gemini2.0模型时,TEN 不仅能听见,还能看见!
当通过摄像头/屏幕共享与 TEN 分享图片时,他不仅可以精准地认出小猫咪的颜色,还能辨别出具体品种!🐱
TEN 提供了 Storyteller 作为 usecase,内置文生图模型插件,可引导用户去共同完成一个故事,同时生成精彩的配套图片
如果您是新手,希望能够 step by step 的学习如果使用 TEN Agent,欢迎参考油管博主 Developer Digest 的教程👇
如果您已经基本了解 TEN 了,也欢迎尝试最新上线的虚拟人 TEN + Trulience👇
最后,如果你对 TEN 感兴趣,欢迎star项目,支持并跟进项目最新动态!
😺 快速体验链接:https://agent.theten.ai/
💻 本地部署 Github 链接:
https://github.com/TEN-framework/TEN-Agent