声明:本文来自于微信公众号AI新榜,作者:王萌 阿虎,授权Soraor转载发布。
泼天的流量终于轮到谷歌了!
这段时间,谷歌“一句话P图”功能已经被广大网友玩疯了。现在打开社交平台,到处都是网友用Gemini跑出来的“神图”。
比如,让世界名画秒变表情包:
上班迟到怎么办?别着急,跟老板说正在通勤路上,有图有真相:

还有网友“无中生友”,拿一张AI生图就能应付催婚:
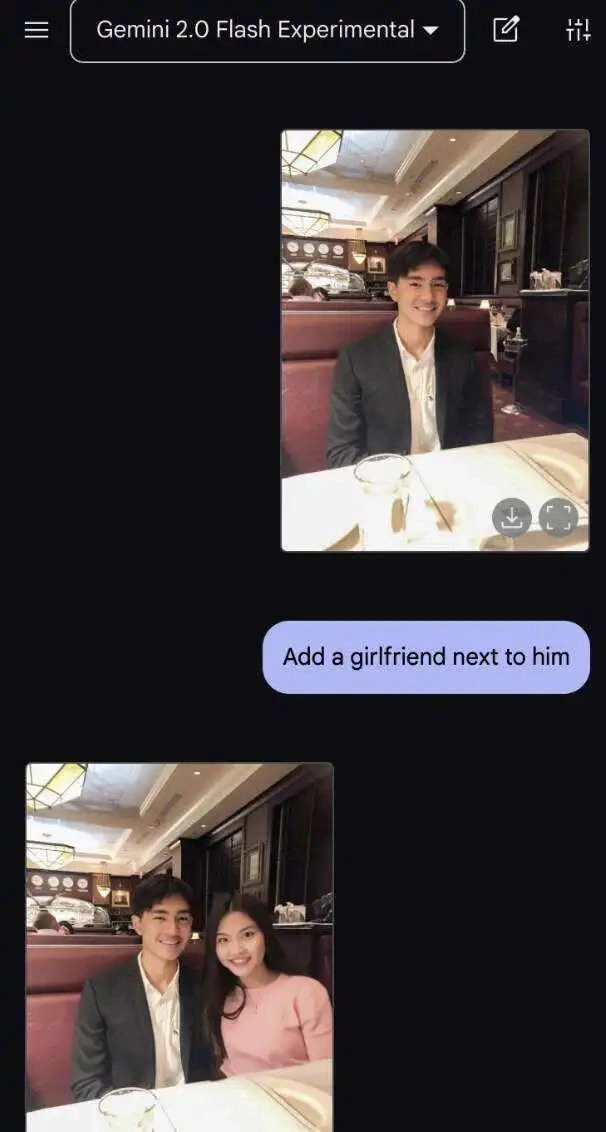
你没看错,这些图都是Gemini亲自下场P的
不仅如此,Gemini2.0Flash还有最强搭档,它可以和Three.js联合生成3D模型:

也有网友将它和Sora联动,生成了一组商业广告:

更夸张的是,现在拍摄证件照不需要PS了,也不用去线下门店,直接靠AI:
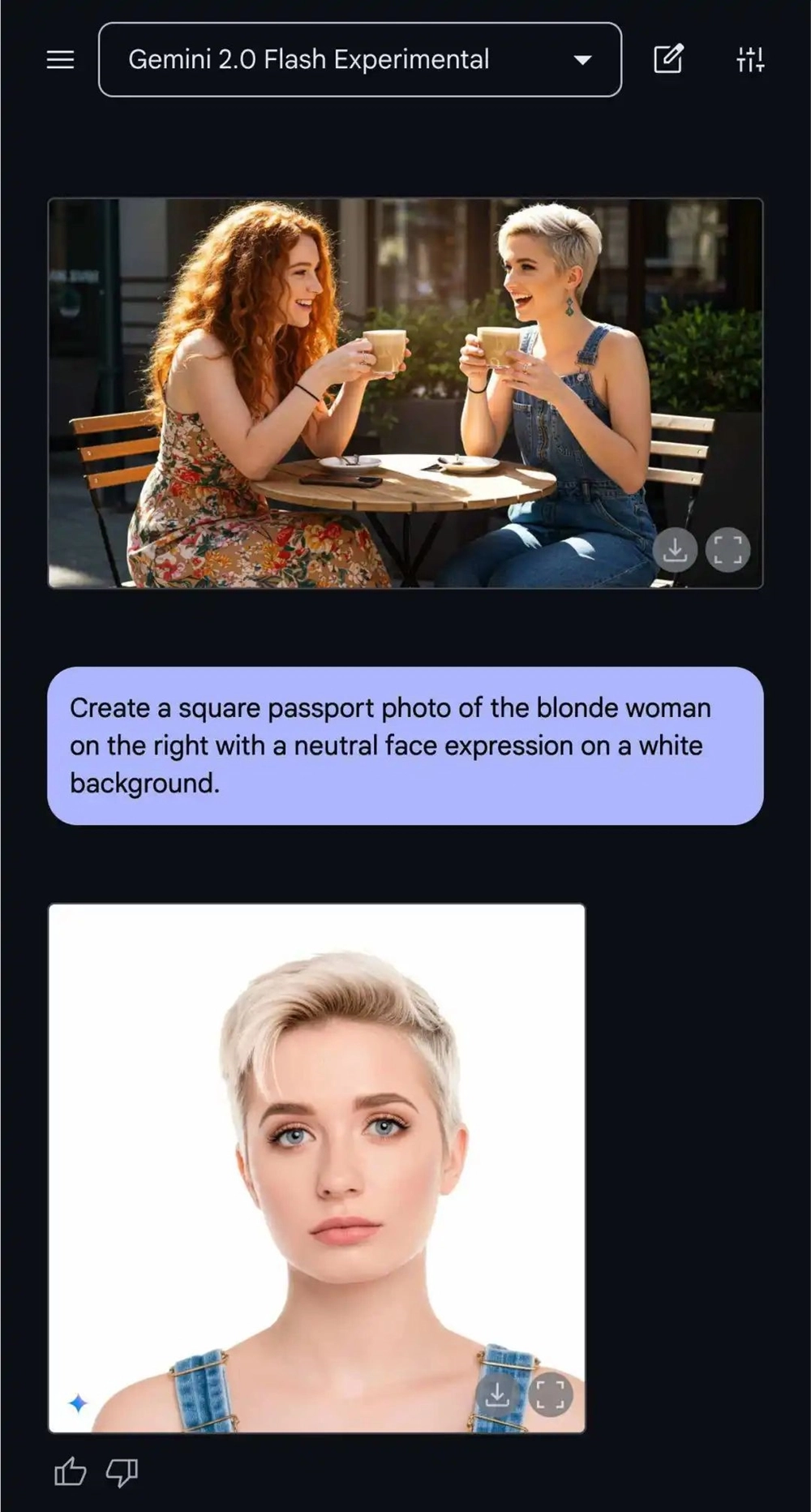
最近,谷歌扩大了Gemini2.0Flash模型图像功能的访问权限,开发者可以通过Google AI Studio和Gemini API免费体验。(体验地址:
https://aistudio.google.com/prompts/new_chat?model=gemini-2.0-flash-exp。)
据了解,Gemini2.0Flash可以结合多模态输入,增强推理能力和自然语言理解,并生成图像。这意味着,现在我们只需要一句话,就可以完成复杂的图像编辑,这在以前可是需要PS、Canva才能实现。
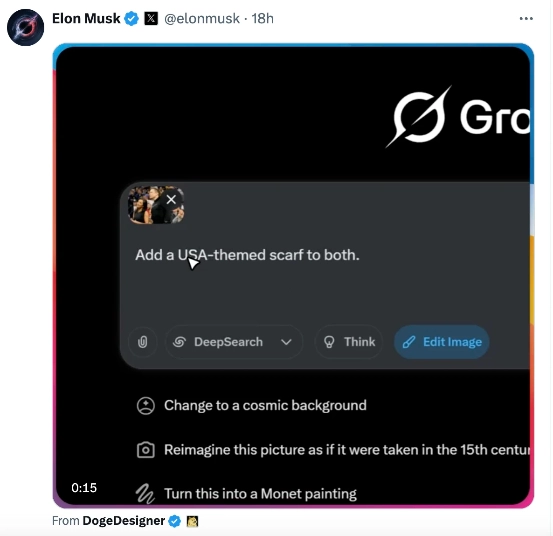
谷歌Gemini2.0Flash究竟有多火爆?这一功能上线几天后,连马斯克都慌了,紧急更新了Grok3的图像编辑功能。
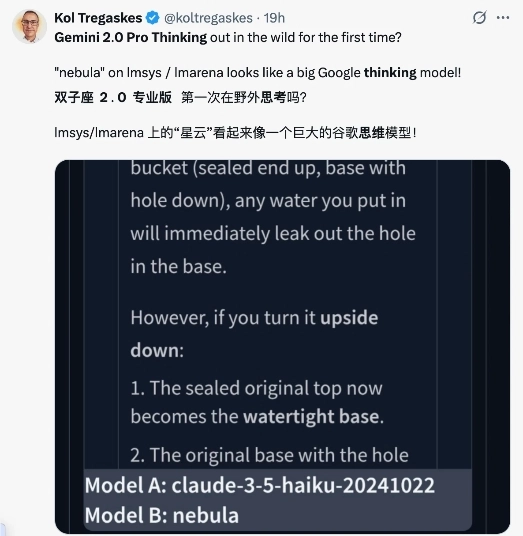
从上周开始,谷歌频繁更新了Gemini的相关功能,连深度推理模型Gemini2.0pro thinking也已经“蓄势待发”。
一年前,谷歌在I/O大会上预告的画布、实时视频对话、图片编辑等新功能,均在这两周内逐一兑现,引发了一波又一波的讨论。这一次,谷歌能靠Gemini成功“逆袭”吗?这几天我们集中地试了试。

Gemini靠“言出法随”爆火,
实测效果如何?
目前,Gemini2.0Flash可以在Google AI Studio中免费体验(需要魔法,地址美国),用户只要在首页右侧选择框中,将模型切换到Gemini2.0Flash Experimantal就可以直接开始对话了。
无论你是想修改原图细节,还是想“无中生有”生成超现实场景,都可以让Gemini实现。比如,我想让这张图“烟花在空中绽放”,只要直接给提示词就可以完成:

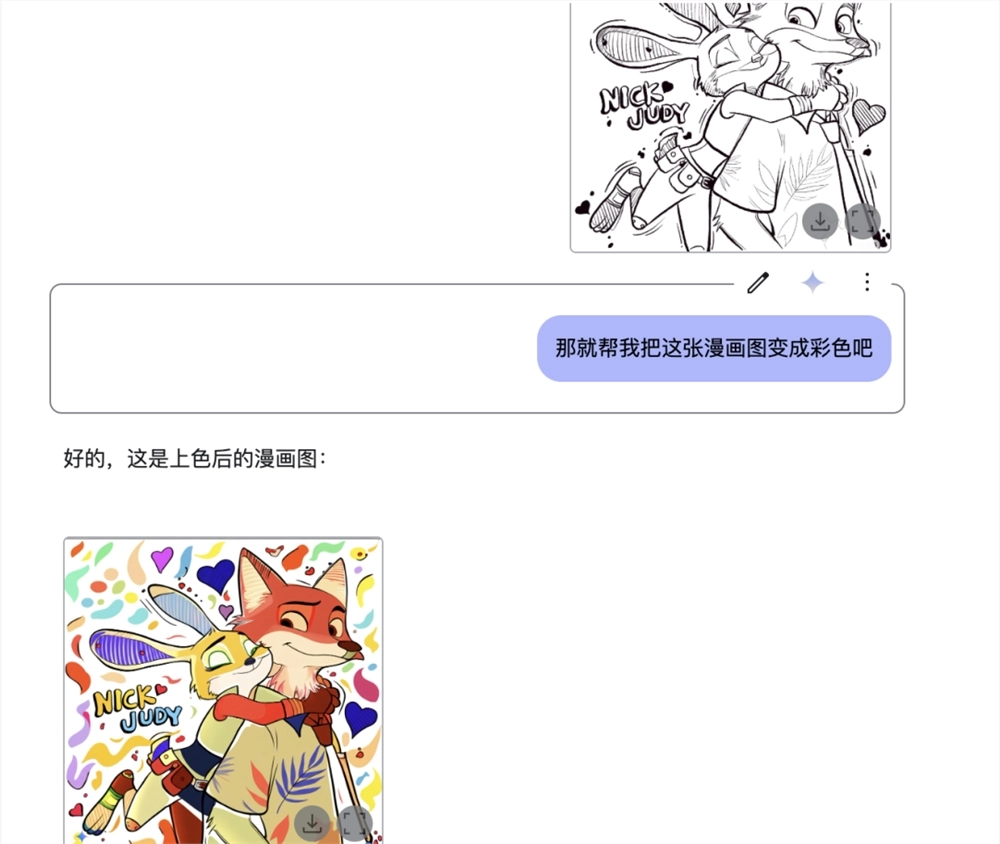
我们再增加一点难度,让它给漫画线稿上色,Gemini也靠想象力完成了:
还有网友测试下来,Gemini能够生成连续的电影分镜,同时保持画面内容的一致性,我也来试了试:
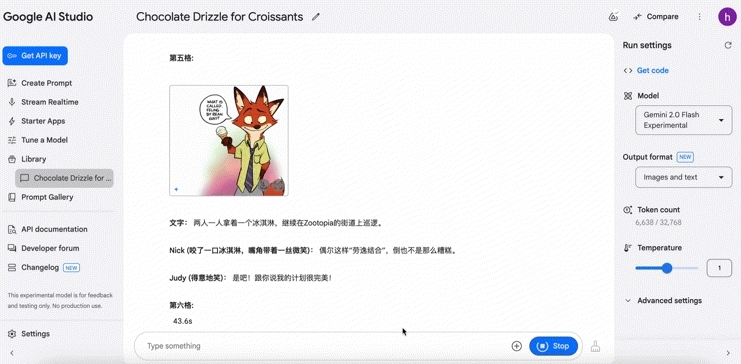
可以看到,Gemini不仅生成了图片,还配上了每个场景的描述内容,对它来说,画连环画不成问题。尽管狐狸的耳朵部分有轻微瑕疵,但图片中的尼克和朱迪的一致性维持得还不错,整体在可接受范围内。
除了可以改动局部细节、生成连续分镜之外,还可以让Gemini改动图片的视角。这个功能对于设计师、电商从业者来说非常实用,可以直接生成不同视角的产品图。
比如,我想让Gemini生成一个小狗的“后视图”,看看能不能解决AI以前无法解决的“大象转身”问题。

这一环节,Gemini也不是次次成功。
实测下来我发现,与其说一些特定的镜头语言、A提示词专业术语,不如直接用白话表示,生图的效果会更好。
举个例子,我需要给这个胡萝卜上色,可能是因为限定了太多条件,Gemini直接生成了一个全新的物件:

但如果直接说“给胡萝卜上色”,出来的效果就是这样的:

虽然还是略有不同,但至少不是毫不相关了,重要的特征都被抓住了。
我们再来试试Gemini对于超现实以及复杂场景的构建和想象能力,比如让它生成“城市巨物”,这也是之前AI圈很流行的一种生图玩法。
提示词:场景是上海,在上海最高的楼上趴着一只巨型的纯灰色蓝猫,猫的身躯大得几乎跟大楼一样宽。图片呈现巨物感,超现实感和神秘感

我还可以更进一步,将图片中的猫换成狗:

以上玩法仅仅使用了Gemini单一模型,还可以将Gemini和其他AI工具结合,让最终的生成效果更好。
比如,我让它和混元3D联动,先用Gemini生成了一张经典梗图,并让它细化各个字母的3D细节,再用混元生成了英文字的模型:
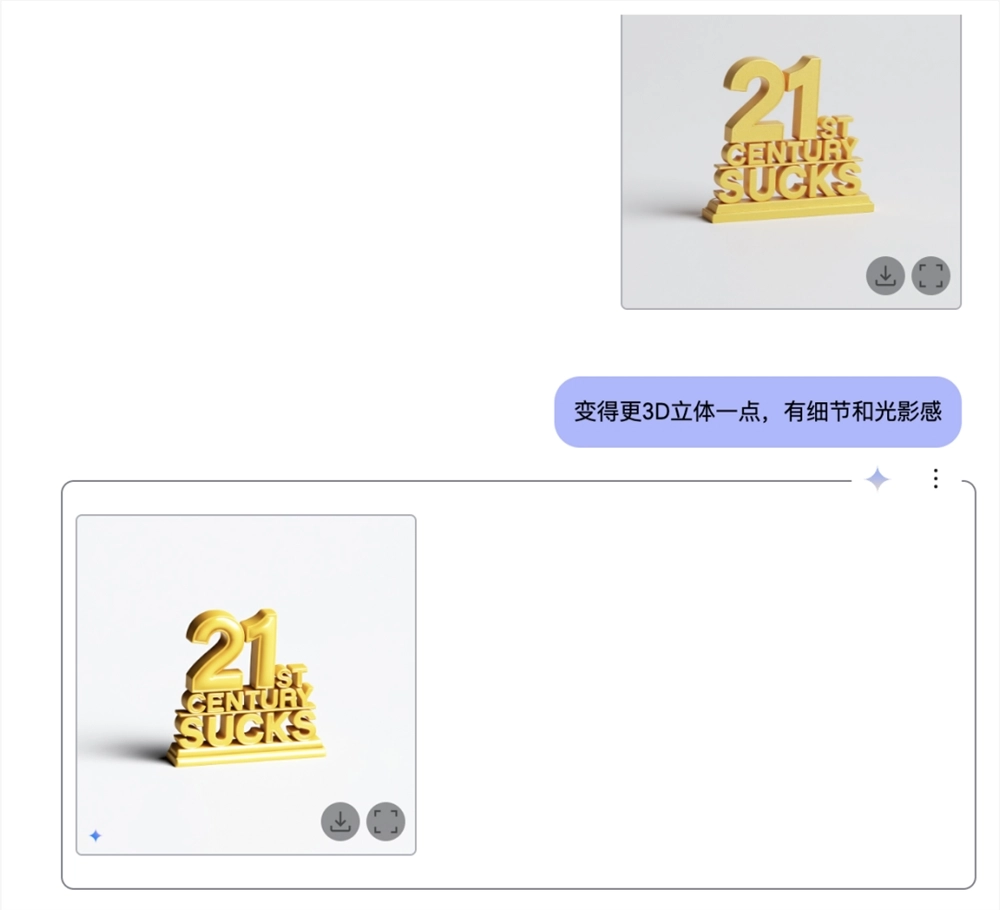

要知道,这个文字我直接用AI3D模型Tripo跑了几十次都没有满意的效果。
Gemini2.0Flash还有很多待挖掘的新玩法,比如可以移除图片水印、智能重建空白区域等等,这些功能让不少网友直呼:“PS的末日来了。”


Gemini越来越清晰的未来:
更具通用性的个人助手
当然,原生多模态的Gemini2.0Flash并不只有“用嘴P图”一种玩法,3月初至今,还有不少陆续更新的小功能也值得一试。
比如Deep Research、Personalization、Gems、Canvas,还有最新出现的Gemini Live屏幕内外多模态识别,几乎是从多个方面全方位为我们展示了谷歌如何一步一步将Gemini打造为通用个人助手。
这其中的任何一项,如果放在OpenAI可能都要开一场20分钟的发布会了

。
Deep Research
Deep Research实际上并不是一个新功能,最早也是由谷歌率先发布。但因当时Gemini1.5Pro表现逊色,很快被OpenAI抢走热度。
如今基于Gemini2.0Flash Thinking的Deep Research在整体实力上有了明显提升。Gemini不仅能完整呈现整个研究过程,而且每个引用参考网页都可点击直达,这一细节对核准信息非常有帮助。
最后生成的结果还能直接一键生成Audio Overview,也就是谷歌在3月19日更新的AI文本转播客功能,能把文档、论文改编成日常对话,提高理解效率。
最后生成的播客音频大伙来感受一下,语音、语气、各种重音和停顿,都与真人对话非常接近,可惜目前只支持英文。
Canvas
人与AI协作已经成为共识,但具体怎么操作却有很多种不同解法,谷歌Canvas可能是其中比较高效的一种。
它的主要呈现方式是增加了一个协作区域,用户可以直接在结果上修改润色,如果是编程代码可以在生成代码后看到预览并直接调试,还能一键导出到Google文档方便多人协作。
不过,最吸引我的还是一些小交互的设计,例如直接划字询问Gemini。右侧三个选项分别是改变长度、改变风格和修改建议,每个大的选项中还提供了多个小选项,例如在我们可以在“改变长度”选择“短”“超短”“长”“超长”。
Gems&Personality
除了这些功能以外,Gemini还有一个“Gems”功能,类似于很多国产AI厂商有的“智能体”广场或ChatGPT的GPTs功能,也就是通过简单的预设定制AI小助手,给不同需求的用户开箱即用的多样化AI应用,还能自己创建Gems,而且完全支持中文。
别忘了谷歌本身作为全球最大的搜索引擎和信息聚合平台,还有大量应用和信息生态优势,“Personalization”功能就很好地利用上了这一点。
在关联谷歌账号后,Gemini可以根据你过往的搜索记录提供个性化的回答,据说搜的越多答得越准。
屏幕识别和实时视频识别
3月22日,Reddit网友“Bard”展示了激活Gemini悬浮窗后,手机端Gemini已经上线了一个全新的按钮“与Live共享屏幕”。
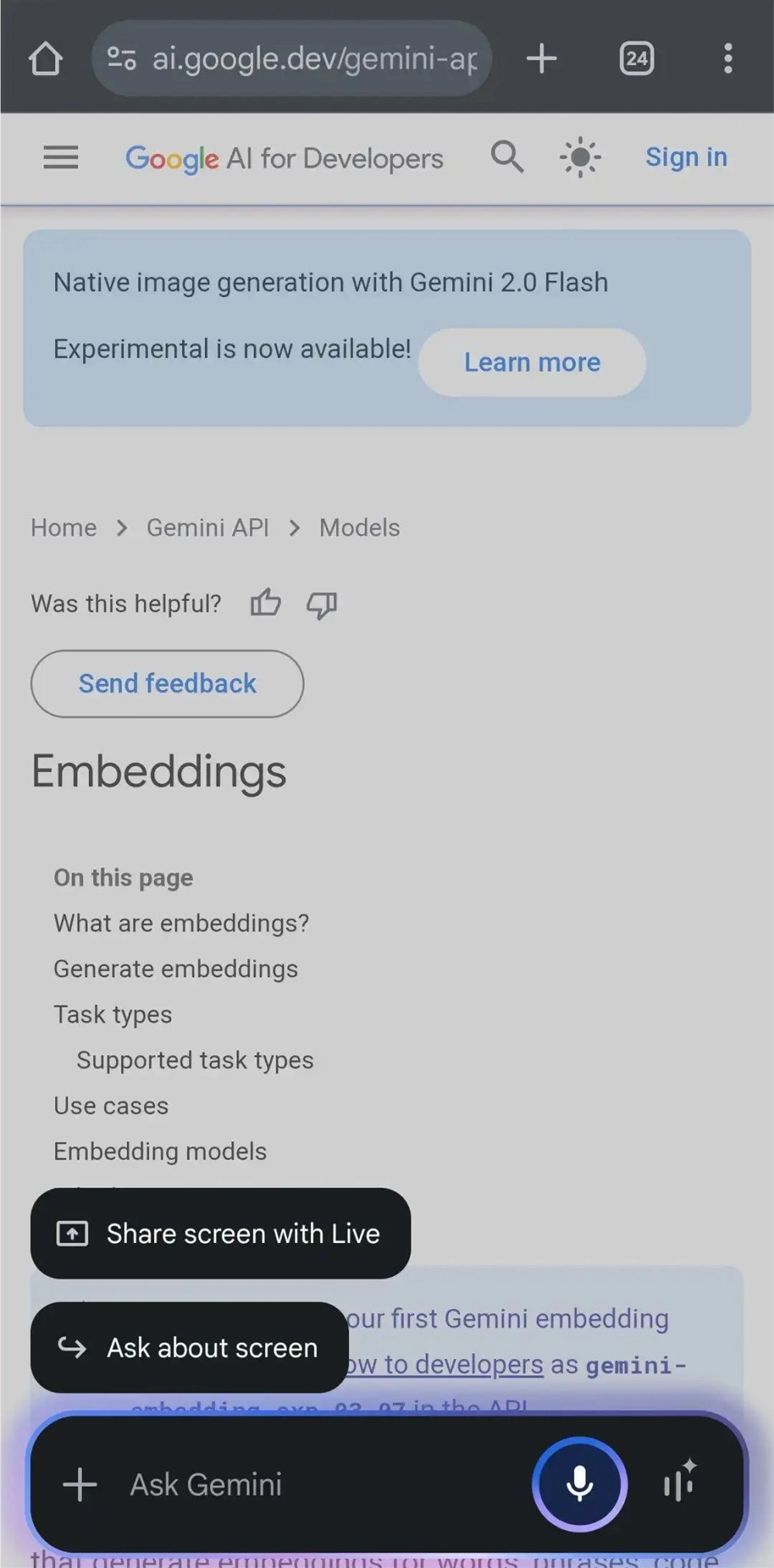
他还展示了具体使用案例,视频中显示Gemini可以获取实时信息、根据手机屏幕信息给出快速回答。
3月23日,YouTube网友“Mike Stevens”也发视频表示,自己的Gemini已经实装屏幕识别功能。
就实际展示结果而言,最终效果与国内很多品牌的手机助手非常相似。但不同之处在于,很多国内手机品牌的内置助手在调出后只能识别当前页面的内容,Gemini则允许用户一边操作手机一边与助手交流,给出实时交流的结果。
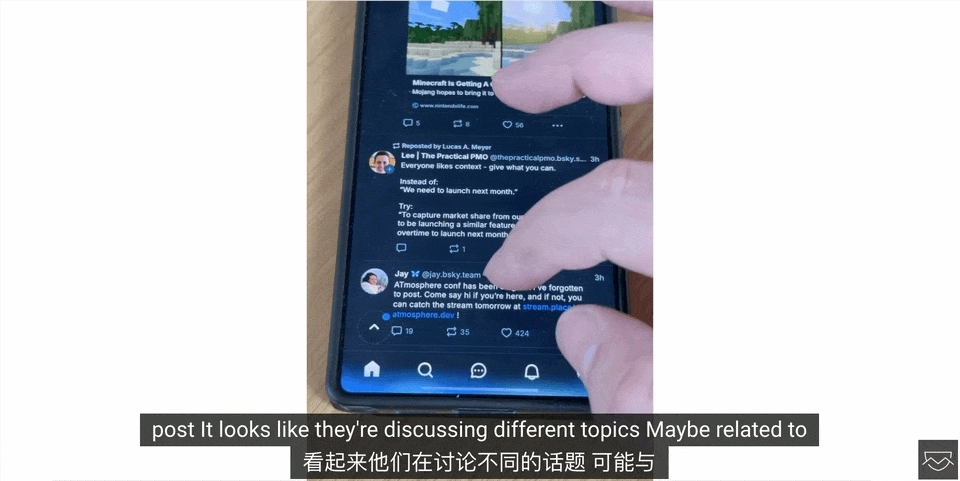
不只是屏幕内的图像识别,近期官方还在YouTube上放出了一段视频,展示了Gemini使用摄像头拍摄周围环境并实时响应的功能。
视频中Gemini能实时分析手机摄像头捕捉到的画面,并回答用户提出的问题。例如用户拿不定该用哪种颜色,Gemini能快速识别并给出建议。
关注谷歌的朋友可能看得出来,这与2024年3月谷歌I/O大会上展示的视频非常相似,当时谷歌对这款名为Project Astra的智能助手是这样定义的:
这是一个实时、多模态的人工智能助手,它可以看见世界,知道事物是什么以及你把它们放在哪里,并且可以回答问题或帮助你做几乎所有事情。

显然,从用户反馈来看,如今的呈现状态已经非常接近当初设想的Project Astra。尽管只是将去年展示的产品实装,但是比起隔壁深陷AI Siri难产、Apple智能虚假宣传风波的苹果而言,“言而有信”已是最大的优点。
不过,谷歌给我们的惊喜还不止这些。就在3月23日,X网友发现了一个泄露的大模型Nebula,通过询问和分析API,发现这可能是谷歌还未发布的“Gemini2.0Pro Thinking”。

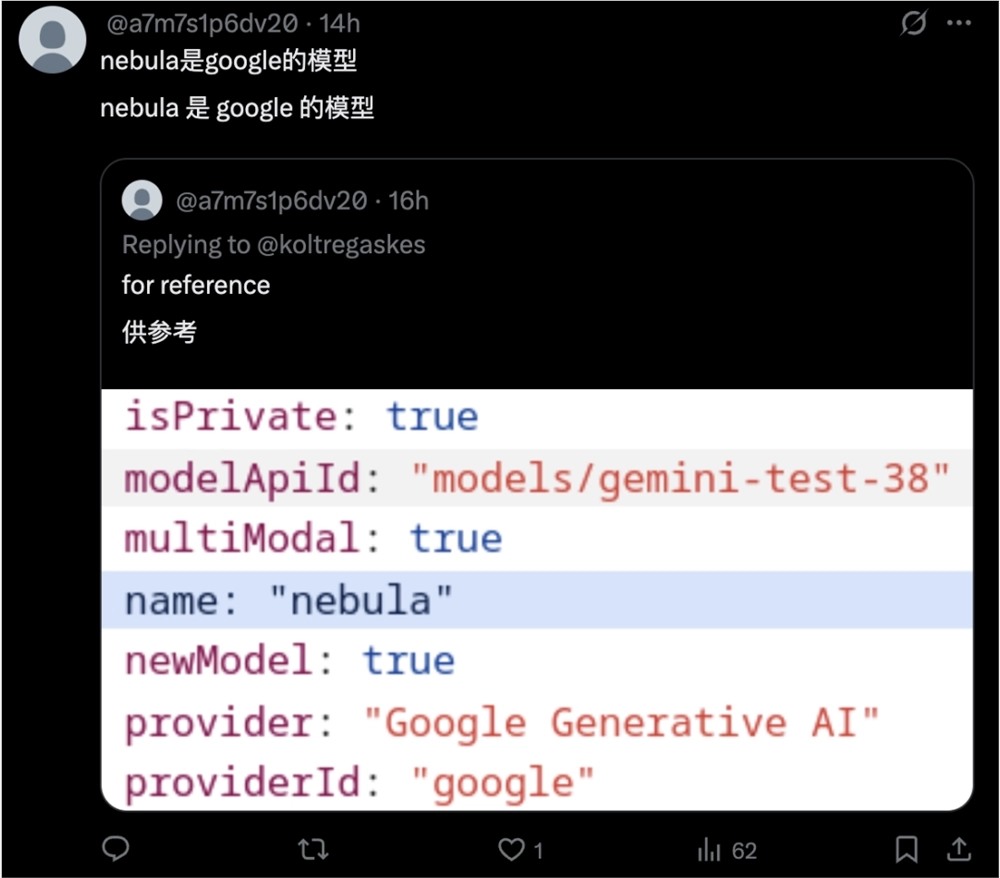
虽然后来该模型迅速下线,但从网络上保留的信息和网友测试来看,它的能力已经超过了o1、o3mini、Claude3.7Thinking等模型,也许在谷歌这里,还有更多惊喜在等着我们。